Document-AI
随着RAG的爆火,目前市面上出现了许多做文档解析的工具,它们相比传统的文档解析,增加了许多非结构化数据的读取和识别。现在我将会介绍几款目前市面上比较火的工具。
Datalab开源工具
Datalab目前开源了三款免费使用的工具,不过12个月内超过500w美元收入的组织进行商业使用时需要收费。旗下有三款文档解析工具,分别是Surya、Texify、Marker。
Datalab门户:https://www.datalab.to
Surya
Surya是一个文档OCR工具包,它可以胜任:
- 90多种语言的OCR,与云服务相比,具有良好的基准
- 任何语言的行级文本检测
- 布局分析(表、图像、标题等检测)
- 阅读顺序检测
官方Github:https://github.com/VikParuchuri/surya
下载
首先下载好Python3.9+和Pytorch环境,然后再安装surya-ocr。
|
|
OCR(文本识别)
- 命令行执行:
|
|
-
常用参数说明:
DATA_PATH可以是图片,pdf,或者是包含图片和pdf的文件夹--langs用于指定OCR的语言,可以通过逗号指定多种语言,但不建议同时超过4种。这里使用语言名称或双字母ISO代码来指定。语言相关的ISO代码查询:https://en.wikipedia.org/wiki/List_of_ISO_639_language_codes--lang_file可以为不同的pdf/图像分别使用不同的语言,可以通过该参数自行指定语言。格式为JSON dict,键为文件名,值为列表,如{"file1.pdf": ["en", "hi"], "file2.pdf": ["en"]}。--images参数将保存页面的图像和检测到的文本行(可选)--results_dir参数指定要保存结果的目录--max参数指定要处理的最大页数--start_page参数指定要开始处理的页码
-
结果
results.json文件的格式说明,其中key是没有扩展名(.pdf)的输入文件名。每个value将会是一个字典列表,输入文档每页一个,每页字典都包含:text_lines- 每行检测到的文本和边界框text- 行中的文本confidence- 检测到的文本中的模型置信度(0~1)polygon-(x1,y1),(x2,y2),(x3,y3),(x4,y4)格式的文本行的多边形。这些点从左上角按顺时针顺序排列。bbox- 文本行(x1,y1,x2,y2)格式的轴对齐矩形。(x1,y1)是左上角,(x2,y2)是右下角。
language- 该页面指定的语言page- 文件中的页码image_bbox- (X1,y1,x2,y2)格式的图像的bbox。(x1,y1)是左上角,(x2,y2)是右下角。所有行bbox都将包含在这个bbox中。
-
结果示例:
- 原pdf:

- 转化后的image:这里不是真正的图片的意思,而是为了查看OCR效果使用的临时图片:

result.json中对应的内容格式:这样便可以比较清楚地知道1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72{ "text_lines": [ { "polygon": [ [ 244.0, 83.0 ], [ 967.0, 83.0 ], [ 967.0, 133.0 ], [ 244.0, 133.0 ] ], "confidence": 0.98974609375, "text": "构件与中间件技术 – 构件的复用", "bbox": [ 244.0, 83.0, 967.0, 133.0 ] }, { "polygon": [ [ 331.0, 432.0 ], [ 1230.0, 432.0 ], [ 1230.0, 456.0 ], [ 331.0, 456.0 ] ], "confidence": 0.9853515625, "text": "1、理想状态是直接复用构件库中现成的构件,但大多数情况下,必须对构件进行或", "bbox": [ 331.0, 432.0, 1230.0, 456.0 ] }, ... ], "languages": [ "zh", "en" ], "image_bbox": [ 0.0, 0.0, 1440.0, 810.0 ], "page": 75 }image_bbox代表整个页面的大小,bbox和polygon则代表每条文本的位置。
- 原pdf:
-
Python调用:
|
|
- OCR模型可以通过编译获得15%的速度提升,首先设置
RECOGNITION_STATIC_CACHE=true,然后运行如下代码:
|
|
Text line detection(文本行检测)
- 命令行执行:
|
|
-
常用参数说明:
DATA_PATH可以是图片,pdf,或者是包含图片和pdf的文件夹--images参数将保存页面的图像和检测到的文本行(可选)--max参数指定要处理的最大页数--results_dir参数指定要保存结果的目录
-
结果
results.json文件的格式说明,其中key是没有扩展名(.pdf)的输入文件名。每个value将会是一个字典列表,输入文档每页一个,每页字典都包含:bboxes- 检测到文本的边界框confidence- 检测到的文本中在检测模型中的置信度(0~1)polygon-(x1,y1),(x2,y2),(x3,y3),(x4,y4)格式的文本行的多边形。这些点从左上角按顺时针顺序排列。bbox- 文本行(x1,y1,x2,y2)格式的轴对齐矩形。(x1,y1)是左上角,(x2,y2)是右下角。
vertical_lines- 在文档中检测到的垂直线bbox- 轴对齐的文本坐标。
page- 文件中的页码image_bbox- (X1,y1,x2,y2)格式的图像的bbox。(x1,y1)是左上角,(x2,y2)是右下角。所有行bbox都将包含在这个bbox中。
-
结果示例:
- 文本检测框:
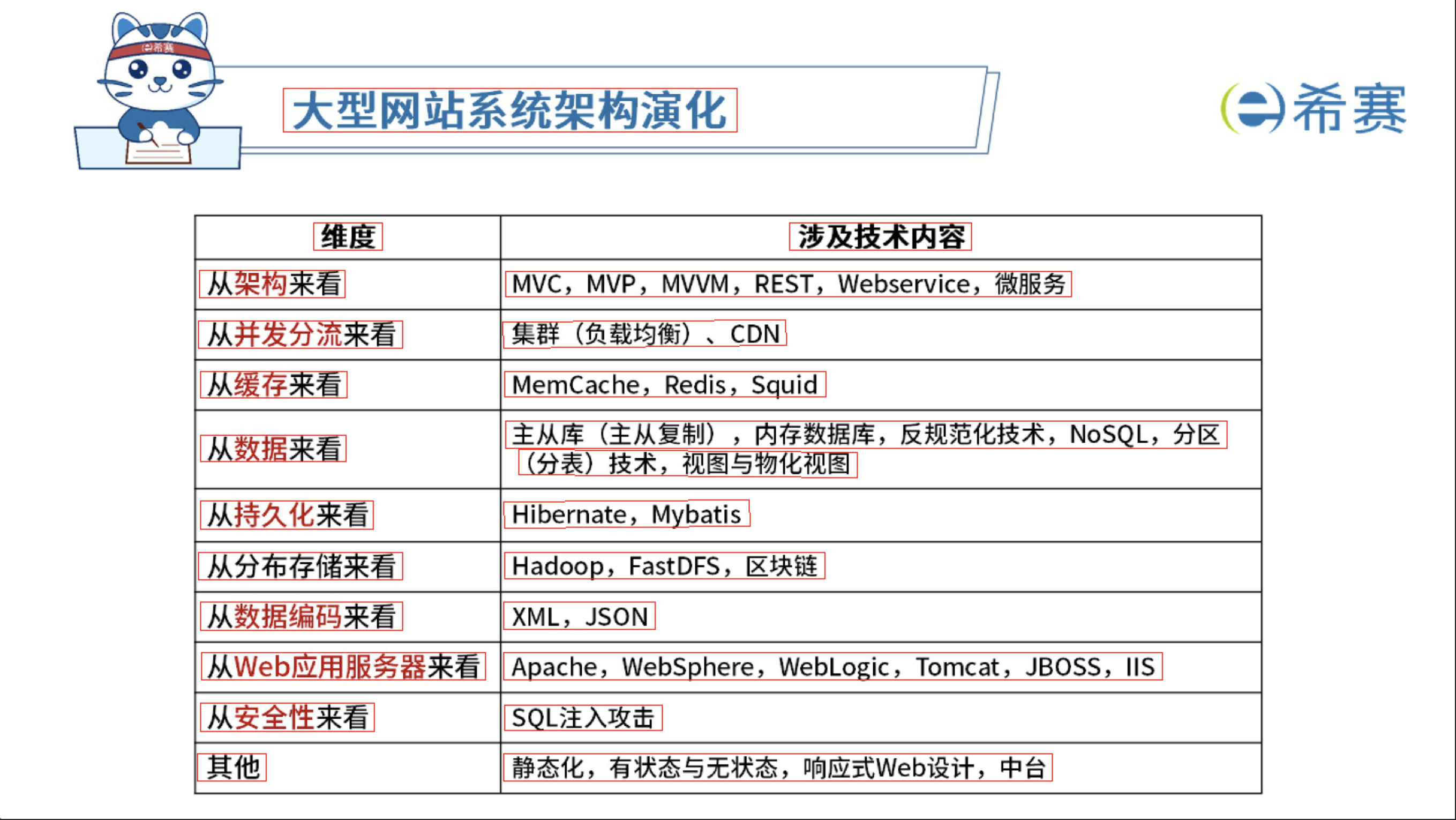
- 垂直线:
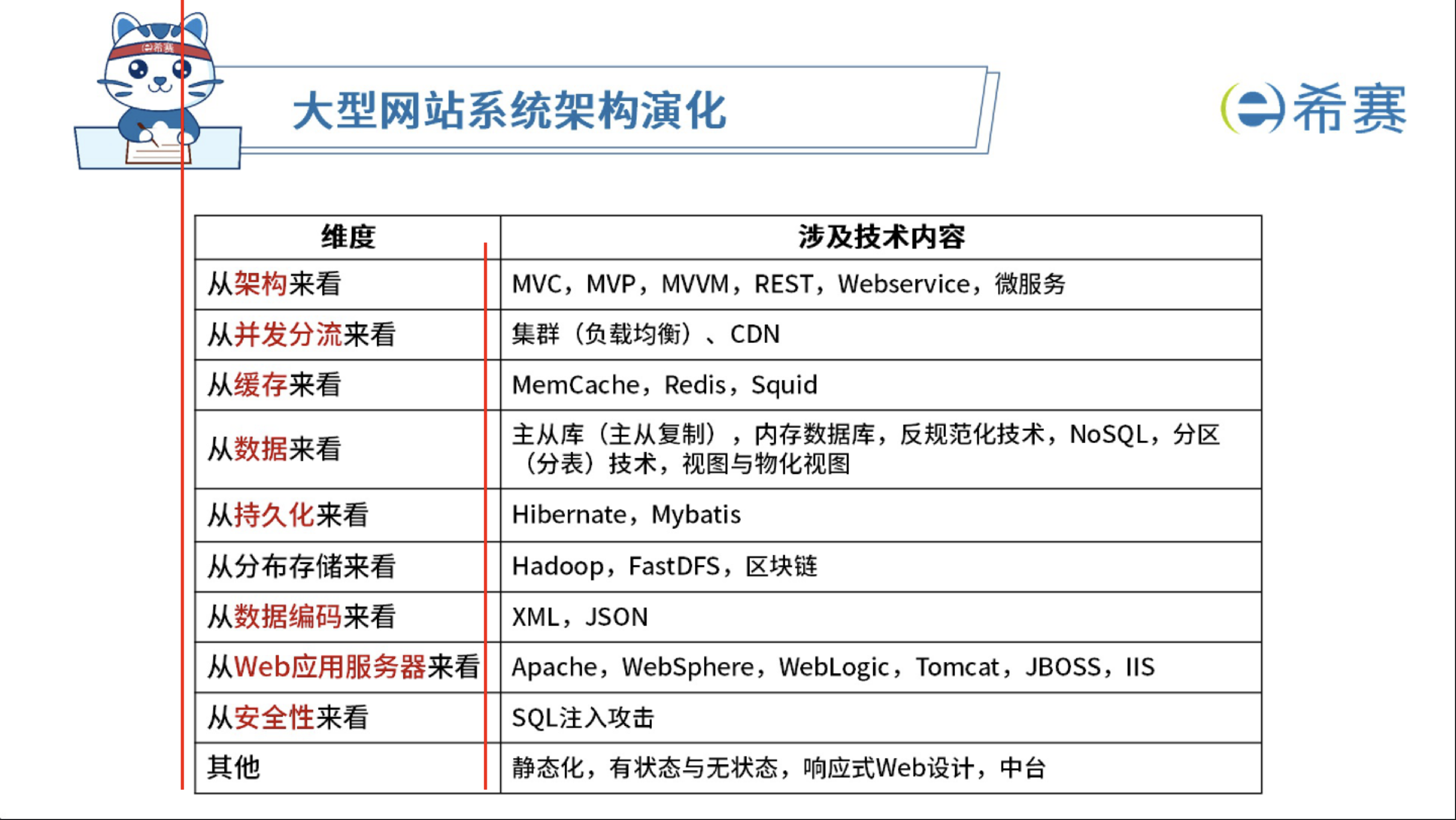
- 文本检测框:
-
Python调用:
|
|
- 总体来说,该部分内容为OCR功能的第一步,也就是文本区域检测,相对多了一个对齐垂直线检测。
Layout analysis(布局分析)
- 命令行执行:
|
|
-
常用参数说明:
DATA_PATH可以是图片,pdf,或者是包含图片和pdf的文件夹--images参数将保存页面的图像和检测到的文本行(可选)--max参数指定要处理的最大页数--results_dir参数指定要保存结果的目录
-
结果
results.json文件的格式说明,其中key是没有扩展名(.pdf)的输入文件名。每个value将会是一个字典列表,输入文档每页一个,每页字典都包含:bboxes- 检测到文本的边界框bbox- 文本行(x1,y1,x2,y2)格式的轴对齐矩形。(x1,y1)是左上角,(x2,y2)是右下角。polygon-(x1,y1),(x2,y2),(x3,y3),(x4,y4)格式的文本行的多边形。这些点从左上角按顺时针顺序排列。confidence- 检测到的文本中在检测模型中的置信度(0~1)label- Bbox的标签。标题、脚注、公式、列表项、页脚、页头、图片、图形、章节标题、表格、文本、标题之一。
page- 文件中的页码image_bbox- (X1,y1,x2,y2)格式的图像的bbox。(x1,y1)是左上角,(x2,y2)是右下角。所有行bbox都将包含在这个bbox中。
-
结果示例:
- pdf版面分析结果:
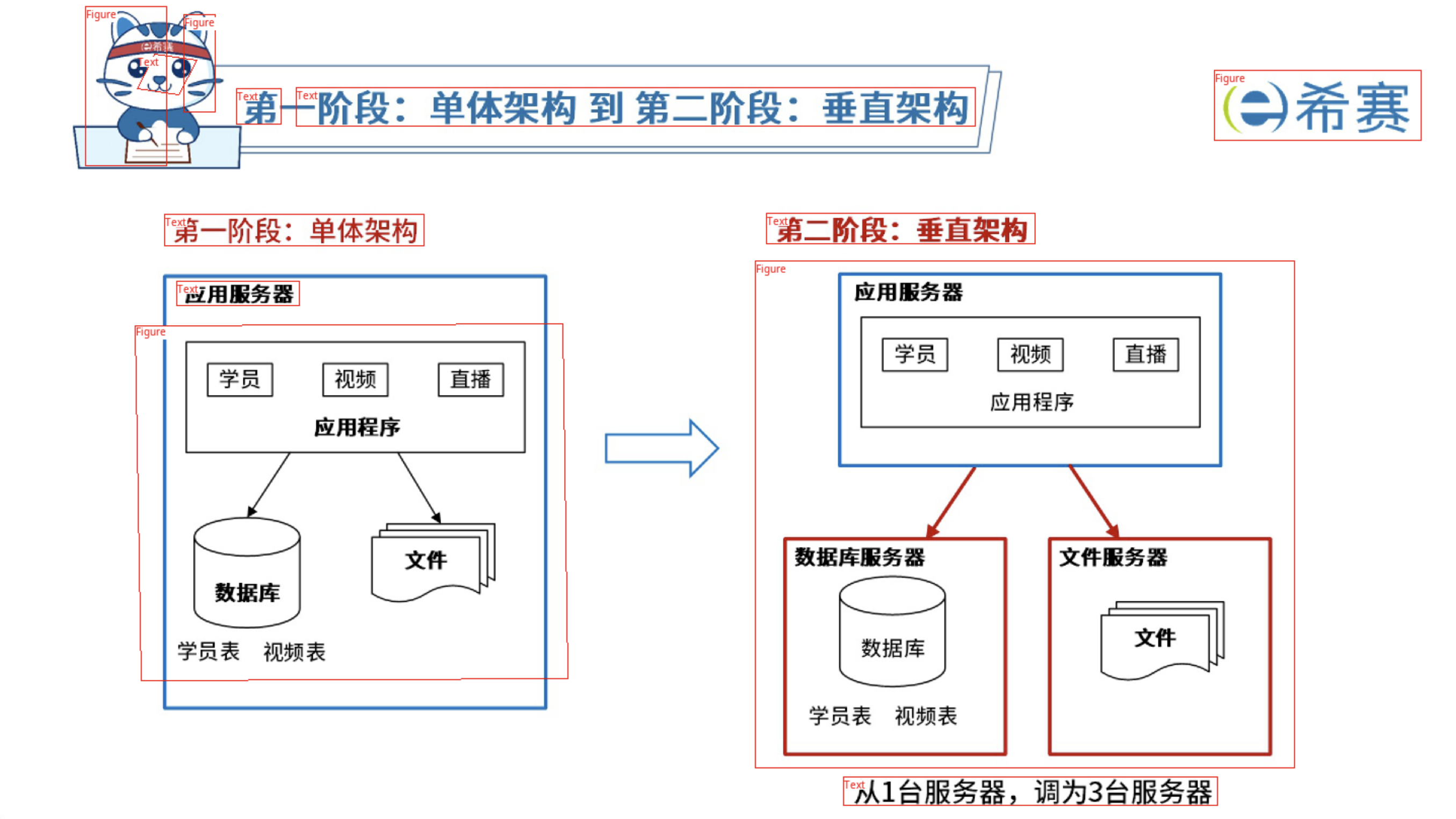
result.json中对应的内容格式:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127{ "3": [ { "bboxes": [ { "polygon": [ [ 60, 13 ], [ 244, 13 ], [ 244, 169 ], [ 60, 169 ] ], "confidence": 1.0, "label": "Figure", "bbox": [ 60, 13, 244, 169 ] }, { "polygon": [ [ 1195, 72 ], [ 1407, 72 ], [ 1407, 135 ], [ 1195, 135 ] ], "confidence": 1.0, "label": "Text", "bbox": [ 1195, 72, 1407, 135 ] }, { "polygon": [ [ 455, 308 ], [ 990, 308 ], [ 990, 398 ], [ 455, 398 ] ], "confidence": 1.0, "label": "Text", "bbox": [ 455, 308, 990, 398 ] }, { "polygon": [ [ 583, 438 ], [ 857, 438 ], [ 857, 516 ], [ 583, 516 ] ], "confidence": 1.0, "label": "Text", "bbox": [ 583, 438, 857, 516 ] } ], "image_bbox": [ 0.0, 0.0, 1440.0, 810.0 ], "page": 1 } ] }
- pdf版面分析结果:
-
Python调用:
|
|
Reading order(阅读顺序)
- 命令行执行:
|
|
- 常用参数说明:
DATA_PATH可以是图片,pdf,或者是包含图片和pdf的文件夹--images参数将保存页面的图像和检测到的文本行(可选)--max参数指定要处理的最大页数--results_dir参数指定要保存结果的目录
- 结果
results.json文件的格式说明,其中key是没有扩展名(.pdf)的输入文件名。每个value将会是一个字典列表,输入文档每页一个,每页字典都包含:bboxes- 检测到文本的边界框bbox- 文本行(x1,y1,x2,y2)格式的轴对齐矩形。(x1,y1)是左上角,(x2,y2)是右下角。position- Bbox阅读顺序中的位置,从0开始。label- Bbox的标签。标题、脚注、公式、列表项、页脚、页头、图片、图形、章节标题、表格、文本、标题之一。
page- 文件中的页码image_bbox- (X1,y1,x2,y2)格式的图像的bbox。(x1,y1)是左上角,(x2,y2)是右下角。所有行bbox都将包含在这个bbox中。
- 结果示例:
- pdf阅读顺序分析结果:

- pdf阅读顺序分析结果:
Texify
Texify是Marker团队针对公式识别难题专门开发的一款pdf上的公式转化为markdown语法的公式识别器。
Marker
Marker是深度学习模型组成的pdf -> markdown 工具的pipeline,Pipeline中的组件包含:
- 提取文本,必要时OCR(启发式、surya、tesseract)
- 检测页面布局并查找阅读顺序(surya)
- 清理和格式化每个块(启发式,texify)
- 合并块和后处理完整文本(启发式,pdf_postprocessor) 需要注意的是,它最后只在必要时使用模型,这提高了速度和准确性。其中提取文本和检测页面布局以及查找阅读顺序使用到的surya,我们在前面已经介绍过了。
在整个Marker工具中用到6个模型:
- 公式转化模型(ocr):texify_model
- 页面布局分析模型(detect):layout_model
- 阅读顺序分析模型:order_model
- 编辑模型(classify):edit_model
- 文本检测模型(detect):detection_model
- 文本识别模型(ocr):ocr_model
Marker识别流程:
- 1、Pypdfium提取PDF数据内容
- 2、对文本内容按照页码进行分块
- 3、检测每页的行级文本(detection_model)
- 4、对需要识别的文本进行识别,主要为无法选中的图片文本(ocr_model)
- 5、对每页文档进行页面布局检测,结合ocr的结果提取出相应的文本块内容(layout_model)
- 6、提取页眉页脚等,再进行阅读顺序排序(order_model)
- 7、将代码块和表格单独识别,并对公式进行转换(texify_model)
- 8、根据需要提取出前面分为纯图片的内容,进行保存,并以链接的形式插入markdown中
- 9、最后将所有提取出的元信息,进行一些基本的过滤清理,按照顺序组装起来成为成品markdown(edit_model)
MinerU
MinerU是上海人工智能实验室推出的一款pdf转markdown的工具。MinerU底层使用了PDF-Extract-Kit工具,布局检测使用了LayoutLMv3模型进行微调后达到一些数据集上的最佳结果。公式检测使用Pix2Text-MFD,行级文本检测使用YOLOv8的微调模型,OCR模型则使用Paddle OCR模型。
与Marker相比,MinerU缺少了基于语义的阅读顺序的模型,也不支持Mac OS,虽然布局检测的模型效果超过了其他模型,但学术性质机构公布的数据真实性有待考量。目前MinerU还在不断迭代中,是一款未来可期的工具。
unstructed
最后修改于 2024-08-06

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。