高级RAG检索策略之知识图谱
在文档的属性分明,不同的文档之间没有很强的关联性,或者每个文档的长度都不大的情况下,基于向量数据库的普通RAG也能很好地工作。但如果使用大型的私有知识库,普通的RAG检索的效果往往没有那么理想。知识图谱的核心在于通过三元组形式(实体-关系-实体)来描述事物之间的关联,这种结构化的数据表示方法不仅能够捕捉数据的语义含义,还能便于理解和分析。
整体流程
知识图谱在RAG中的使用流程如图所示:
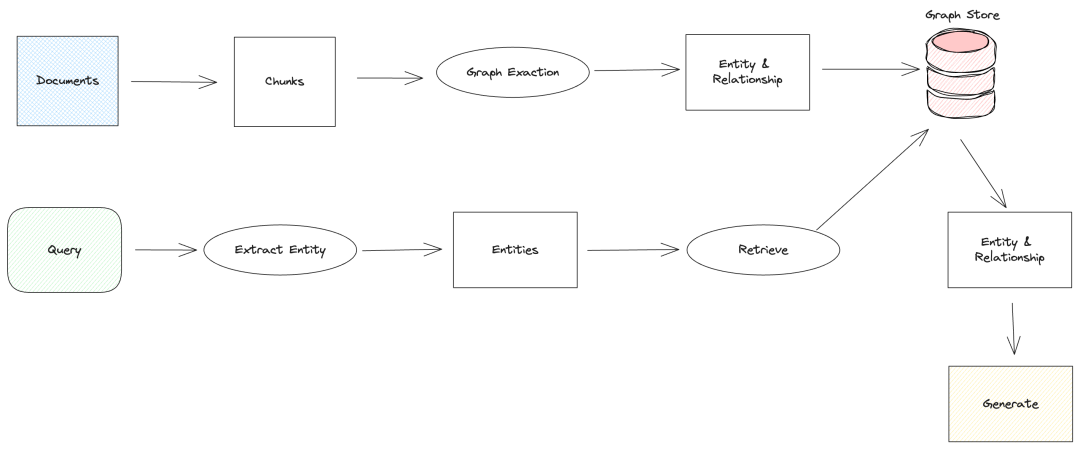
首先和普通RAG的流程相同的是,它们首先都需要进行文本分块。后续知识图谱RAG会将分块后的文档进行实体和关系的提取,提取出实体和关系后保存到图数据库中。
检索的时候会将问题的实体提取出来再对图数据库进行检索,检索结果是一个庞大的实体关系网络,最后将检索到的实体和关系以及目标文本结合问题提交给大模型进行答案生成。
当然知识图谱RAG也可以图检索、向量检索和关键词检索等,这样可以综合利用多个检索的链路进行判断,提高检索的准确性和效率。
解决的场景
在 RAG 中使用知识图谱主要解决在大型文档库上问答和理解困难的问题,特别是那些普通RAG方法难以处理的全局性问题。
普通RAG在回答针对整个文档库的全局性问题时表现不佳,例如问题:请告诉我所有关于XXX的事情,这个问题涉及到的上下文可能分布在整个大型文档库中,普通RAG的向量检索方法很难得到这种分散、细粒度的文档信息,向量检索经常使用top-k算法来获取最相近的上下文文档,这种方式很容易遗漏关联的文档块,从而导致信息检索不完整。
知识图谱RAG和普通RAG的区别
- 知识图谱RAG使用图结构来表示和存储信息,捕捉实体间的复杂关系,而普通RAG通常使用向量化的文本数据
- 知识图谱RAG通过图遍历和子图检索来获取相关信息,普通RAG主要依赖向量相似度搜索
- 知识图谱RAG能更好地理解实体间的关系和层次结构,提供更丰富的上下文,普通RAG在处理复杂关系时能力有限
数据入库
知识图谱和普通RAG的数据入库流程不同,普通RAG在进行文档分块后,通常使用embedding模型将文档块进行向量化,将向量和文档保存到向量数据库。与普通RAG不同,知识图谱RAG在入库过程中会将文档块进行实体和关系的提取,提取出实体和关系后保存到图数据库。
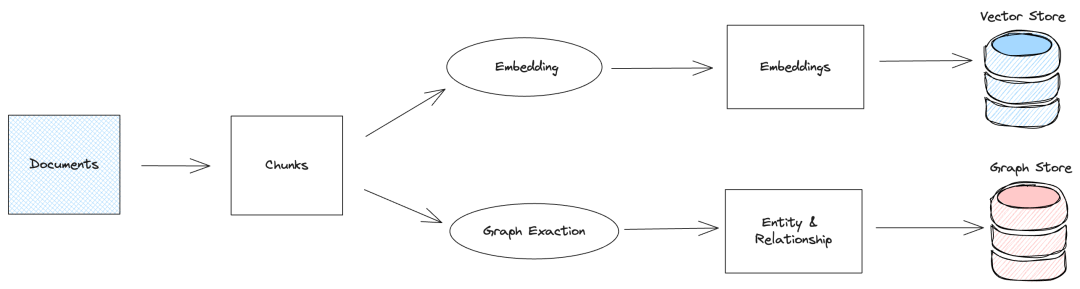
实体提取的传统方法是基于预定义的规则和词典、统计机器学习或者深度学习等技术,但进入到LLM时代后,实体提取更多的是使用LLM来进行,因为LLM能够更好地理解文本的语义,实现也更加简单。
LLamaIndex中的KnowledgeGraphIndex类中的实体提取提示词如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
DEFAULT_KG_TRIPLET_EXTRACT_TMPL = (
"Some text is provided below. Given the text, extract up to "
"{max_knowledge_triplets} "
"knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.\n"
"---------------------\n"
"Example:"
"Text: Alice is Bob's mother."
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n"
"(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
# 中文版本
DEFAULT_KG_TRIPLET_EXTRACT_TMPL_ZH = (
"下面提供了一些文本。给定文本,提取成"
"{max_knowledge_triplets}"
"知识三元组的形式(主语、谓语、宾语)。"
"避免停顿。\n"
"---------------------\n"
"例子:"
"文本:张三是李四的妈妈"
"三元组:\n(张三, 是妈妈, 李四)\n"
"文本:星巴克是一家2000年在杭州成立的咖啡店。\n"
"三元组:\n"
"(星巴克, 是, 咖啡店)\n"
"(星巴克, 成立于, 杭州)\n"
"(星巴克, 成立于, 2000年)\n"
"---------------------\n"
"文本:{text}\n"
"三元组:\n"
)
|
在提示词中要求 LLM 将文档块 text 提取成实体-关系-实体这样的三元组,实体一般是名词,表示文档块中的实体,关系是动词或者介词,表示实体之间的关系,并给出了几个 Few Shot,让LLM能更好地理解实体抽取的任务。
实体抽取出来保存到图数据库,也有其他的知识图谱RAG是将数据保存到文件中,然后用特有的算法进行检索,比如GraphRAG。
图数据库是一种专门用来存储图结构的数据库,常见的数据库有Neo4j、ArangoDB等。不同的图数据库有不同的查询语言,比如Neo4j的查询语言使用的是Cypher,如果想要在RAG中使用Neo4j来存储知识图谱数据,那么掌握一些基础的Cypher语法是有必要的。
检索生成
知识图谱RAG在检索过程中会将问题进行实体提取,将提取出来的实体通过图数据库进行检索,这样可以获取到名称相同的实体,以及与实体相关的实体和关系,最后将检索到的所有实体和关系提交给LLM进行答案生成。
对问题进行实体提取与数据入库时的实体提取方法类似,也是通过 LLM 来进行,但只需要提取出问题中的实体即可,不需要提取三元组,LlamaIndex的KGTableRetriever类中提取问题关键字的提示词:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
DEFAULT_QUERY_KEYWORD_EXTRACT_TEMPLATE_TMPL = (
"A question is provided below. Given the question, extract up to {max_keywords} "
"keywords from the text. Focus on extracting the keywords that we can use "
"to best lookup answers to the question. Avoid stopwords.\n"
"---------------------\n"
"{question}\n"
"---------------------\n"
"Provide keywords in the following comma-separated format: 'KEYWORDS: <keywords>'\n"
)
# 中文版本
DEFAULT_QUERY_KEYWORD_EXTRACT_TEMPLATE_TMPL_ZH = (
"下面提供了一个问题。给定问题,提取至"
"{max_keywords}"
"文本中的关键词。专注于提取我们可以使用最好地
"查找问题的答案的关键词,避免停语。\n"
"--------------------\n"
"{question}\n"
"--------------------\n"
"按照以下逗号分隔的格式提供关键字:'关键词:<关键词>'\n”
)
|
提示词要求LLM从问题中提取出多个关键字,并用逗号分隔,这些关键字通常是问题中的实体。将问题的实体提取出来后,再用实体名称去图数据库中进行检索,检索的原理就是使用图数据库的查询语句对每个实体进行检索,获取对应的三元组。以Neo4j图数据库为例,下面是一个简单的Cypher查询语句:
MATCH (n {name: 'Alice'})-[r]-(m)
RETURN n, r, m
LLamaIndex实现知识图谱RAG
Neo4j安装
直接使用Docker下载镜像并启动:
1
2
3
4
5
6
7
|
docker pull neo4j:5.21.0
docker run --name neo4j -d \
--publish=7474:7474 --publish=7687:7687 \
--volume=/your/host/path/neo4j-data/data:/data \
--env NEO4J_PLUGINS='["apoc"]' \
neo4j:5.21.0
|
端口7474的服务是Web管理服务,端口7687的服务是数据库服务。进入http://localhost:7474连接localhost:7687,输入初始账号密码:neo4j/neo4j,然后设置新密码,就可以进入到Neo4j的管理界面了。
LLamaIndex中使用Neo4j
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from llama_index.graph_stores.neo4j import Neo4jGraphStore
username = "neo4j"
password = "neo4j"
# bolt一种高效的二进制协议,用于在客户端和服务器之间传输数据
url = "bolt://localhost:7687"
database = "neo4j"
graph_store = Neo4jGraphStore(
username=username,
password=password,
url=url,
database=database,
)
|
然后将文档保存到Neo4j数据库中,示例代码如下:
1
2
3
4
5
6
7
8
9
10
|
from llama_index.core import StorageContext, SimpleDirectoryReader KnowledgeGraphIndex
documents = SimpleDirectoryReader("./data").load_data()
storage_context = StorageContext.from_defaults(graph_store=graph_store)
index = KnowledgeGraphIndex.from_documents(
documents,
storage_context=storage_context,
max_triplets_per_chunk=2,
include_embeddings=True,
)
|
文档经过分块、实体提取、Embedding 等操作后,最后将实体和关系保存到 Neo4j 数据库中。最后我们构建查询引擎,并对问题进行检索生成:
1
2
3
4
5
6
7
8
9
|
query_engine = index.as_query_engine(
include_text=True,
response_mode="tree_summarize",
embedding_mode="hybrid",
similarity_top_k=5,
verbose=True,
)
response = query_engine.query("Which two members of the Avengers created Ultron?")
print(f"Response: {response}")
|
最后修改于 2024-08-31

本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。