Xinference:为LLM app赋能
- Xinference Github官网:https://github.com/xorbitsai/inference
- Xinference 官方中文文档:https://inference.readthedocs.io/zh-cn/latest/index.html
Xinference 集成了 LLM、embedding、image、audio、rerank模型。关于LLM,则集成了Transformer、vLLM、Llama.cpp、SGLang引擎。该框架主要是制作了一个UI界面来自主控制集成好的模型,为应用开发提供底层能力。
环境安装
- 本地环境安装:可根据不同的引擎来安装不同的版本,具体看https://inference.readthedocs.io/zh-cn/latest/getting_started/installation.html
- Docker镜像:由于Docker管理起来比较方便,我这里就使用了Docker的部署方式。 官方提供了方便下载的镜像:
|
|
我选择了v0.13.0的版本。
Xinference启动
使用Docker启动的方式比较简单,使用官方提供的命令:
|
|
由于公司的网下载大模型比较慢,所以通常我们会选择在本地下好的模型进行加载,所以需要对命令做一点改造
现在本地新建文件夹,并把需要的模型传入。
|
|
开始启动镜像:
|
|
模型启用
按照上述镜像启动后,容器已经在后台运行,此时可以在浏览器输入相应https://<ip>:9998进行访问了。
在本地开发环境,可以使用界面来操作配置模型,管理模型,启动模型等。
在框架内本身集成了很多现有的模型,如下图所示,你可以直接点击启动,框架会自动去下载模型。
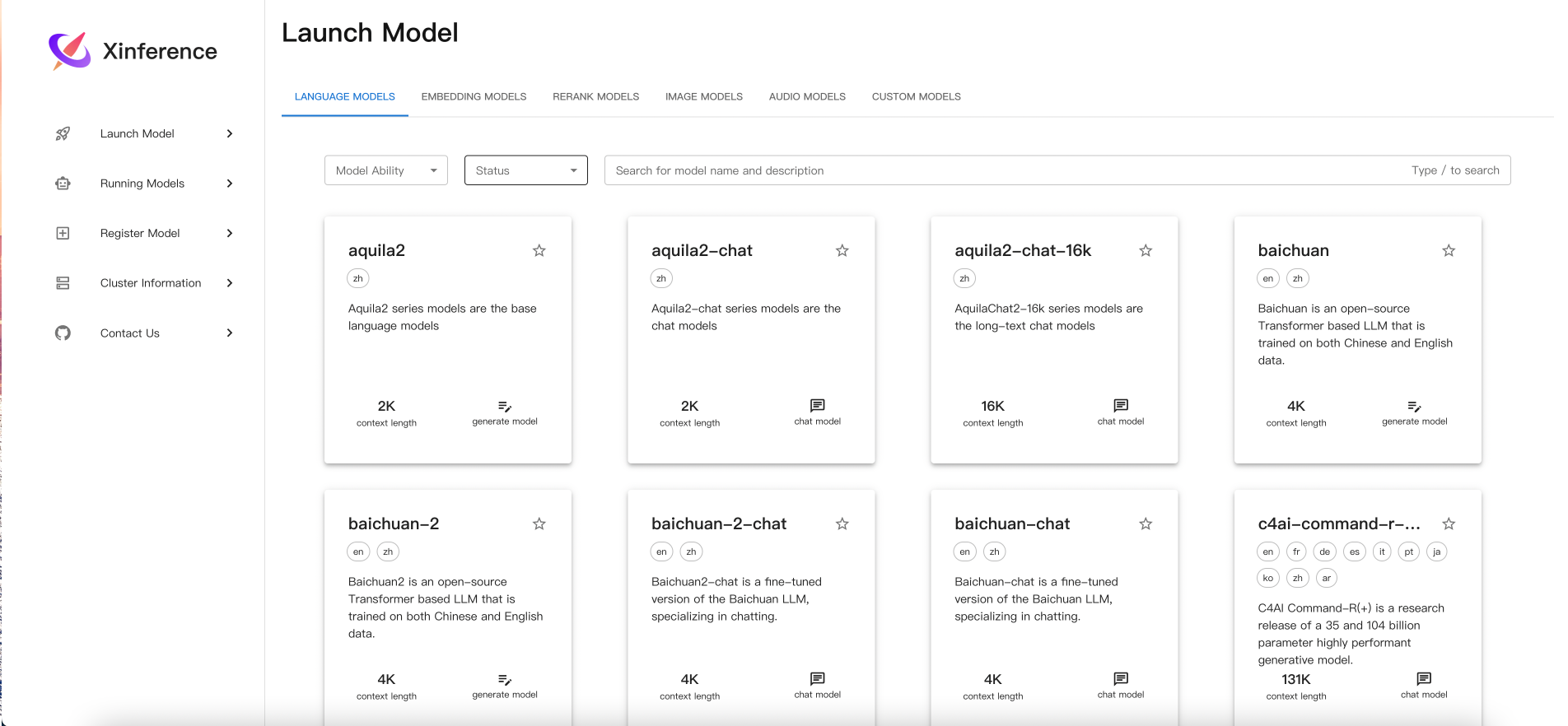
但很多时候网络不好的时候,我们则需要将自己映射进去的模型给注册了并使用。
以Qwen2-7B-Instruct模型为例:
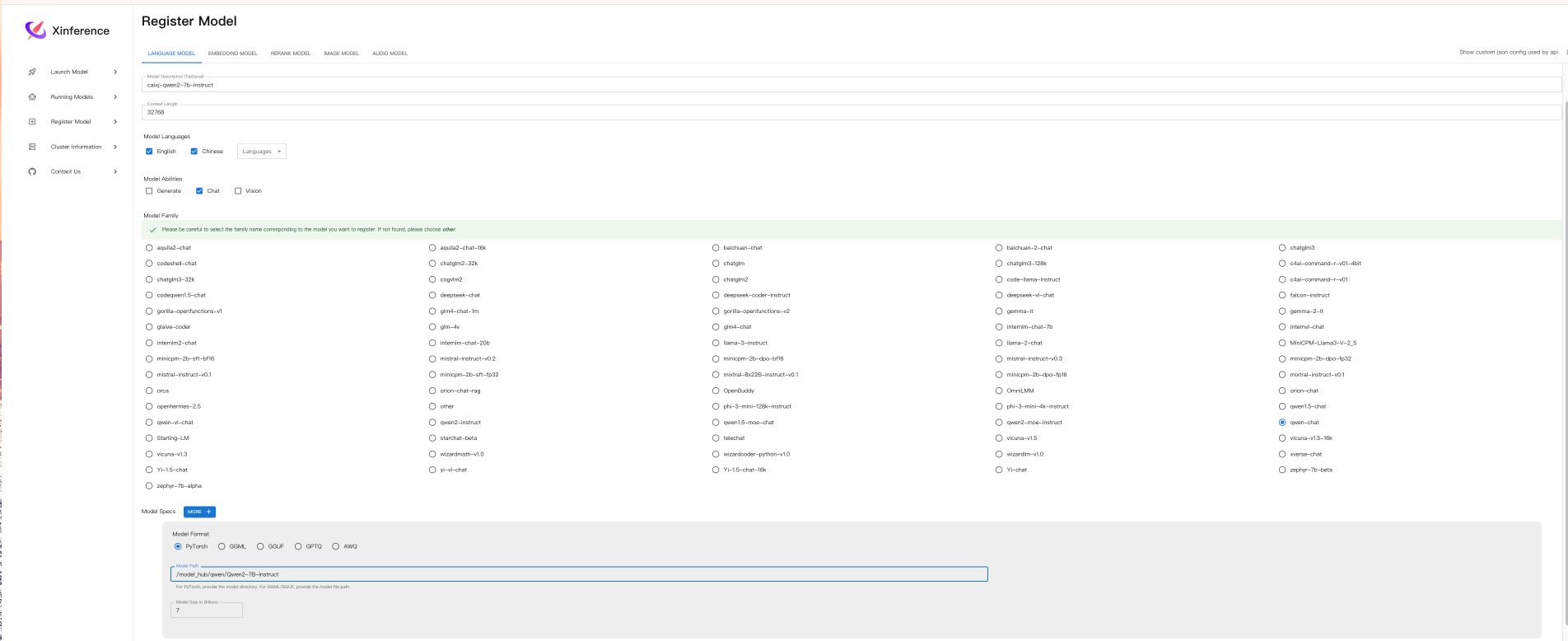
主要还是填写一些基本信息,以及模型的格式,模型的架构等,注意名字要加前缀,防止更系统中自带的模型名字不同而冲突。
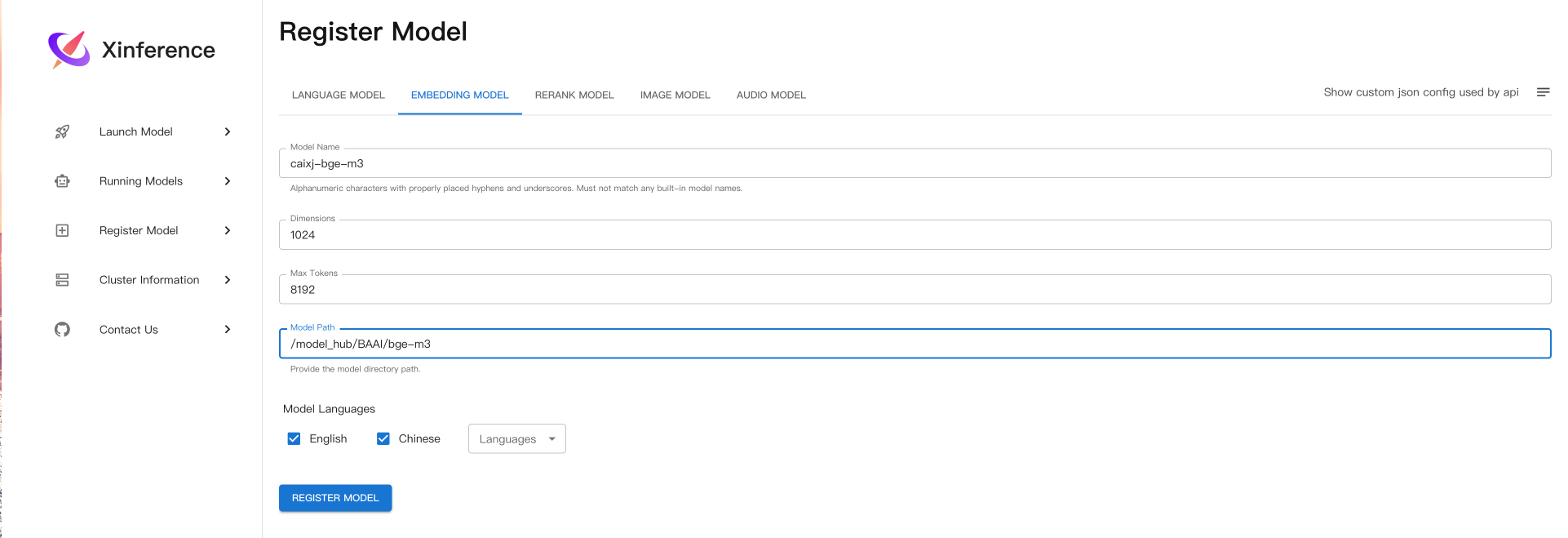
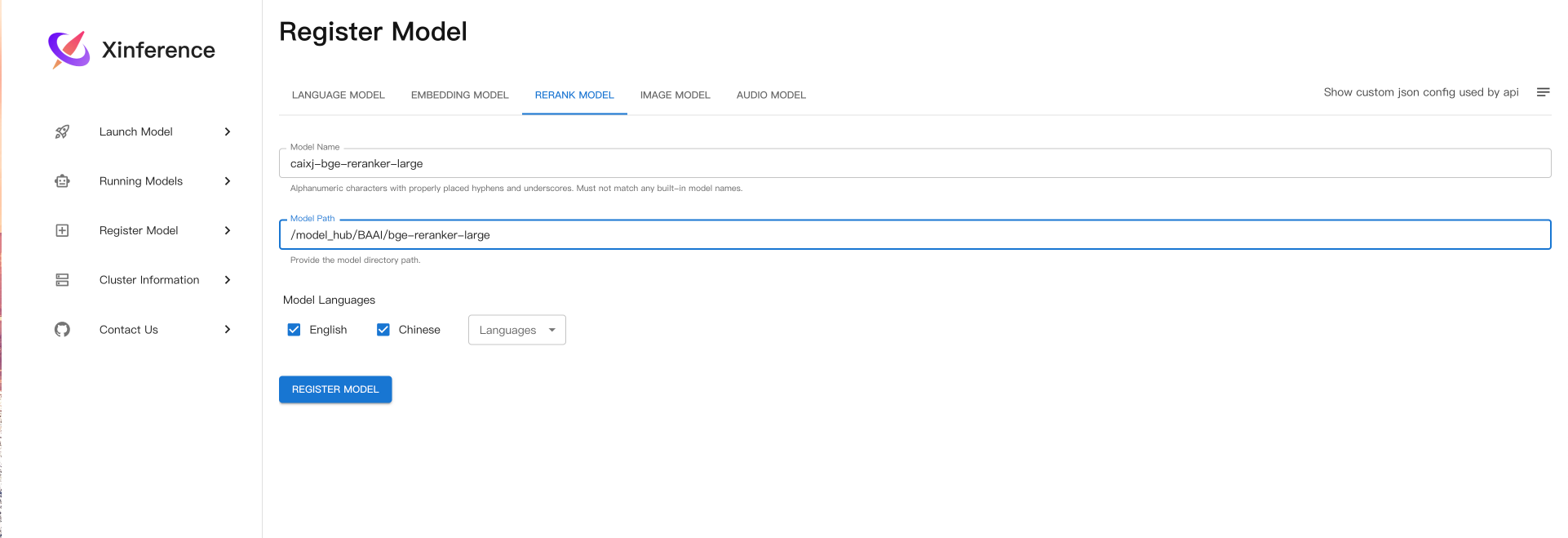
同样的也可以注册embedding、和rerank模型:
注册好之后,就可以在Launch Model的custom models这里找到自己注册的模型:
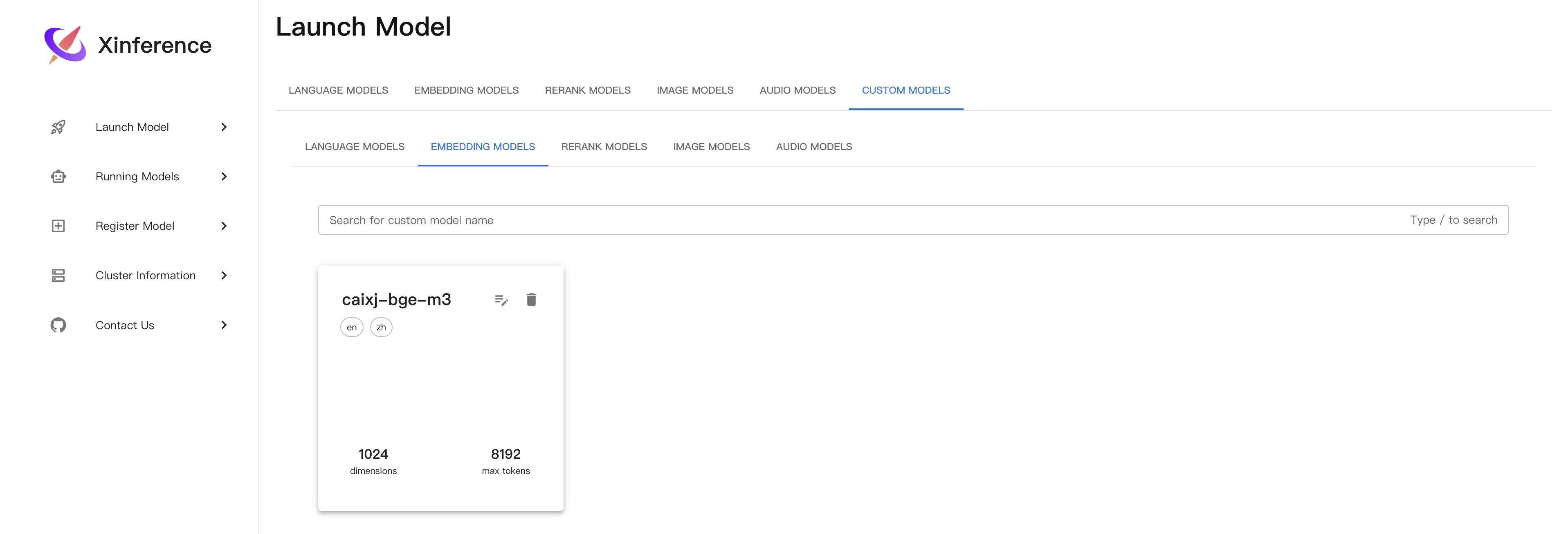
然后就可以启动自己的模型了!
先看LLM Chat模型:
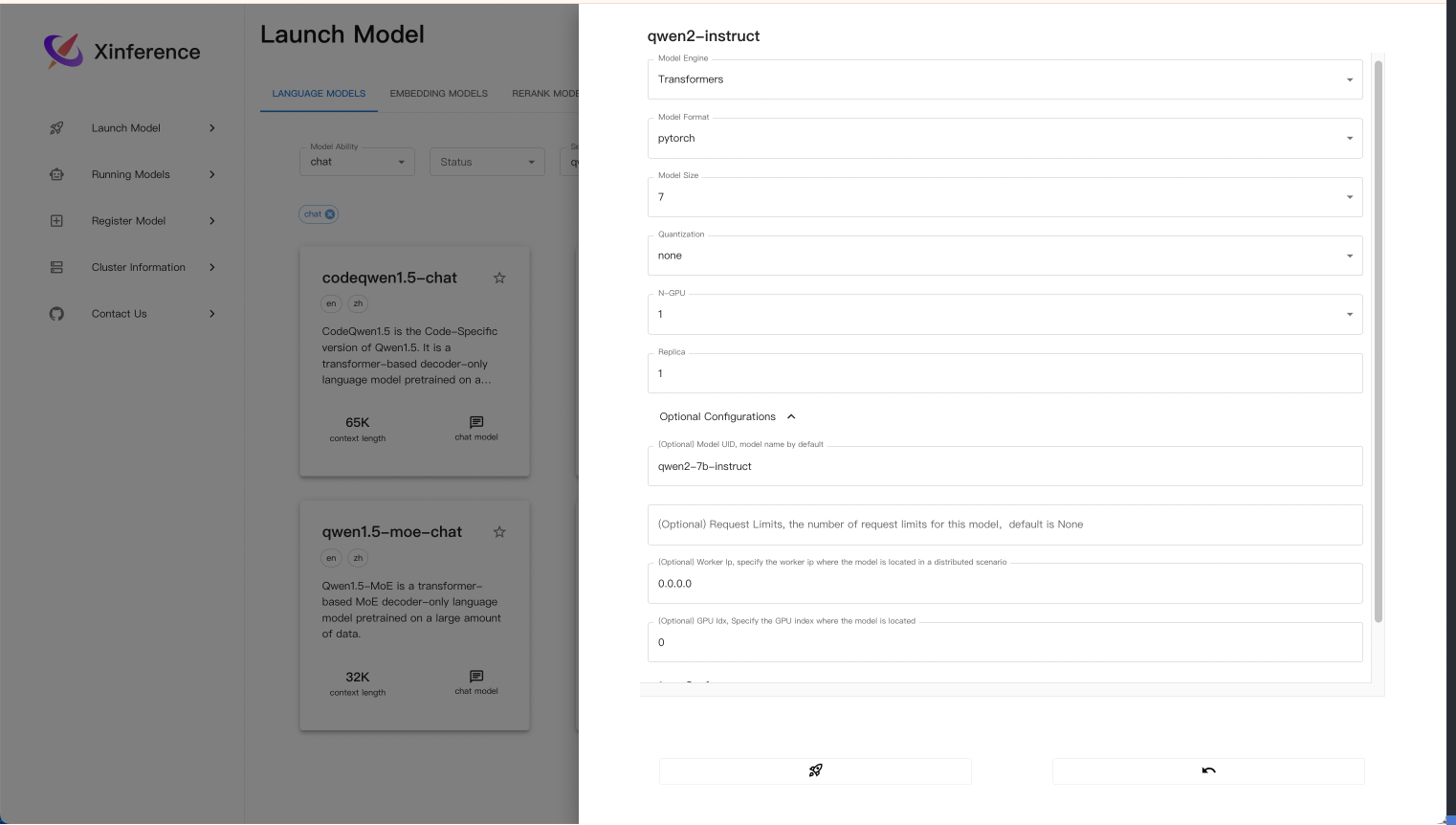 以Qwen2-7B-instruct为例子:
以Qwen2-7B-instruct为例子:
- model_engine可以选择
Transformers、vllm和llama.cpp。 Transformers为例,Model Format参数主要是选择pytorch模型还是gptq,awq模型,后两者为不同量化方法的模型。Model Size在注册模型时便指定,以B为单位。Quantization代表量化的位数,可以选择none,4-bit,8-bit。N-GPU代表使用的GPU数量,这里能选择的参数会根据docker映射进来的GPU数量自动决定选择上限。Optional Configurations中的Model UID是你调用该运行的模型时的名字,后续会用到。Worker Ip一般都直接写0.0.0.0GPU Idx是你要在哪块GPU上进行启动推理。Addtional parameters则需要参考Transformers
查询Xinference可以启动的、某种类型的模型:
|
|
可以使用xinference launch --help来查看命令
上述参数对应的命令为:
|
|
运行成功后就可以在Running Models里面找到它了!
验证方法:
|
|
XINFERENCE_HOST根据启动的机子的ip来,XINFERENCE_PORT默认为9998,Model_UID使用的上述启动模型时设置的model-uid。
Embedding模型启动:
界面启动:
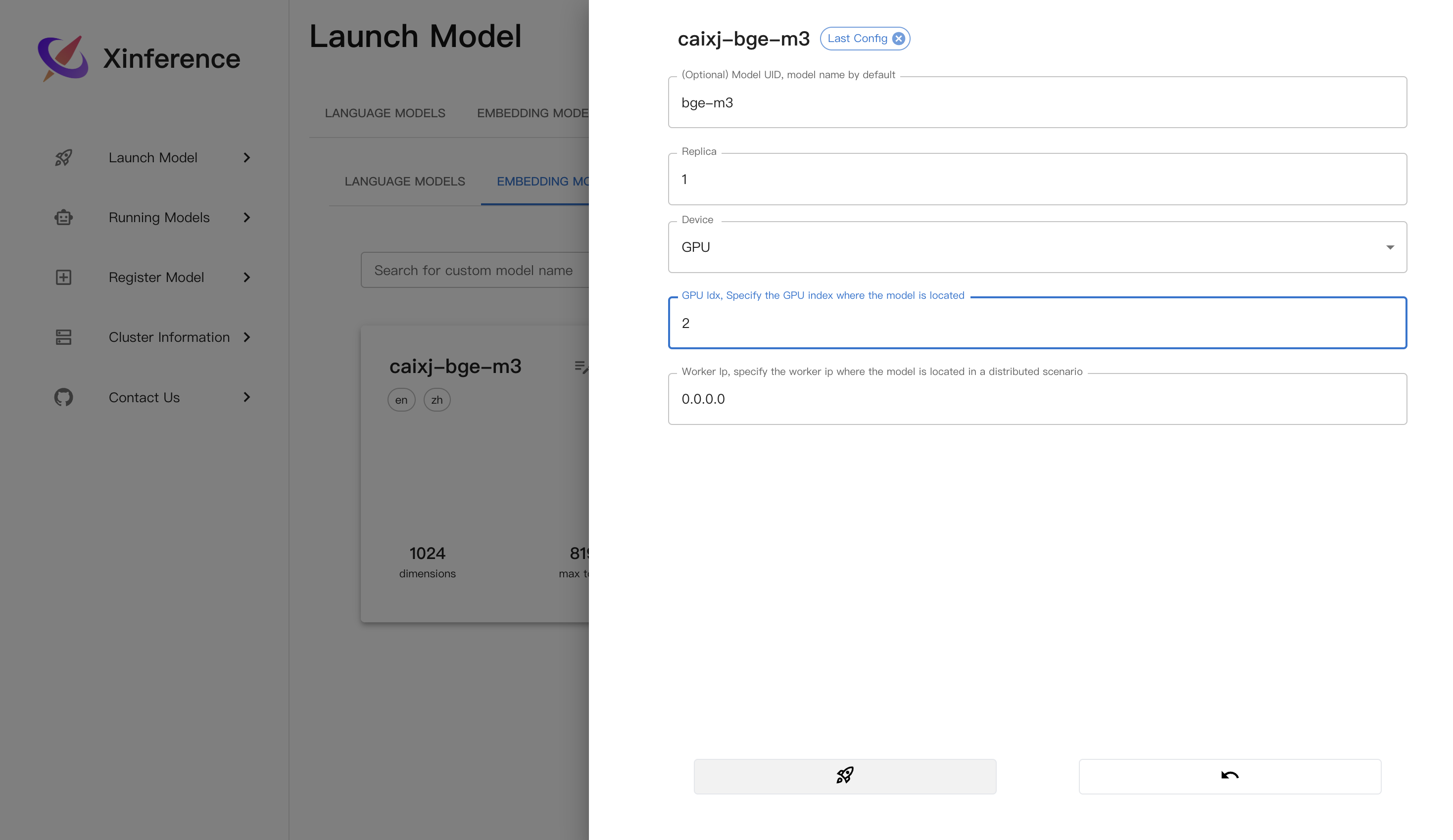
对应命令:
|
|
验证方法:
|
|
输出内容:
{
"object":"list",
"model":"bge-m3-1-0",
"data":[{"index":0,
"object":"embedding",
"embedding":[-0.03103026933968067,0.03556380420923233, ... ,-0.0026659774594008923,-0.006471091415733099,-0.0057240319438278675]}],
"usage":{
"prompt_tokens":23,
"total_tokens":23
}
}
Rerank模型启动:
界面启动:
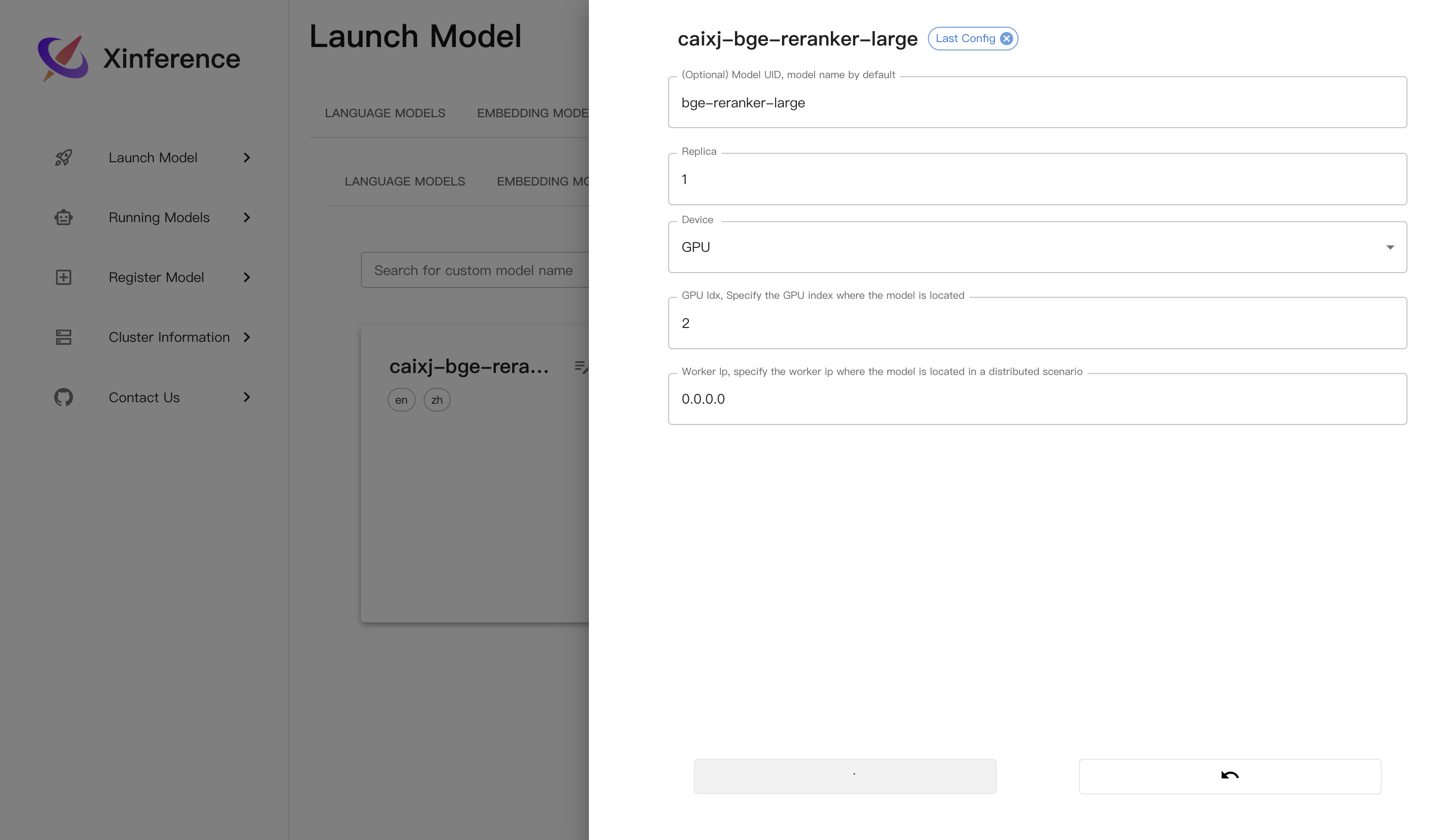
对应命令:
|
|
验证方法:
|
|
输出内容:
{'id': '09e431fa-3f38-11ef-a3c2-0242ac11003a',
'results': [{'index': 0, 'relevance_score': 0.9999258518218994, 'document': {'text': 'A man is eating food.'}},
{'index': 1, 'relevance_score': 0.048283521085977554, 'document': {'text': 'A man is eating a piece of bread.'}},
{'index': 2, 'relevance_score': 7.636439841007814e-05, 'document': {'text': 'The girl is carrying a baby.'}},
{'index': 4, 'relevance_score': 7.636331429239362e-05, 'document': {'text': 'A woman is playing violin.'}},
{'index': 3, 'relevance_score': 7.617334631504491e-05, 'document': {'text': 'A man is riding a horse.'}}],
'meta': {'api_version': None, 'billed_units': None, 'tokens': None, 'warnings': None}}
有时候界面启动了并不一定启动了,你需要结合nvidia-smi显存占用和本地映射文件中的日志来确定,日志一般在logs文件夹下,会根据每次启动单独生成一个文件夹。
最后修改于 2024-07-11

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。