NLP & LLM入门
对于一个LLM菜鸡来说,从头理解LLM主要架构和任务是很有意义的。
LLM发展
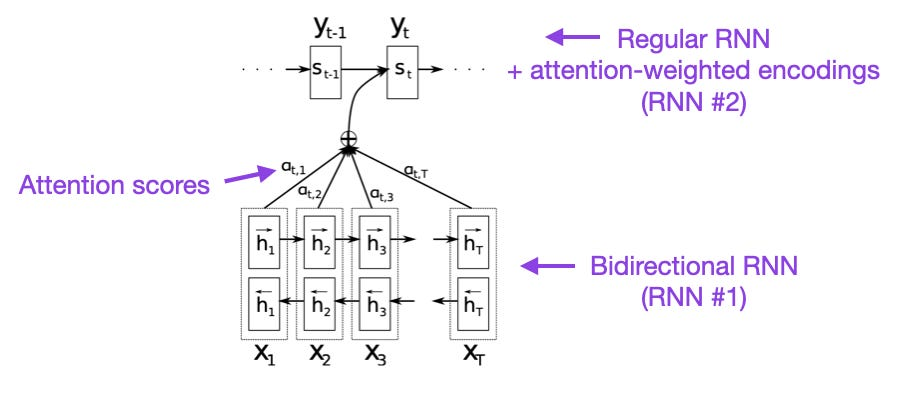
双向RNN中的注意力
论文:Neural Machine Translation by Jointly Learning to Align and Translate
链接:https://arxiv.org/pdf/1409.0473.pdf
该论文引入了循环神经网络(RNN)的注意力机制。传统的 RNN 在处理较长序列时可能会遇到梯度消失或梯度爆炸等问题,导致远程位置的信息难以传递。注意力机制能够通过给予不同位置的输入不同的权重,使模型更好地捕捉到远程位置的信息,从而提高模型处理远程序列的能力。后续Transformer网络的开发也是为了提高网络的远程序列建模能力。
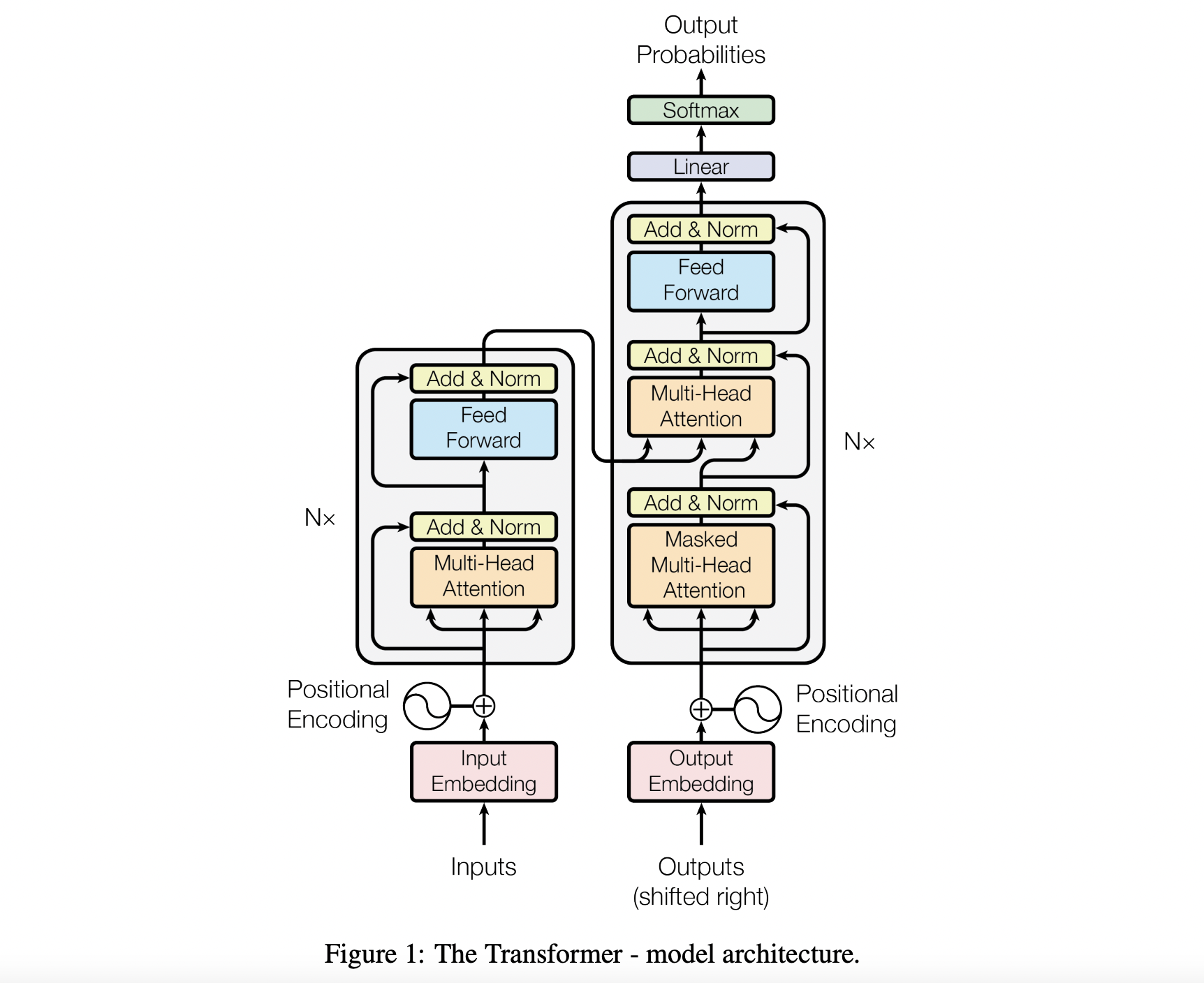
Transformer
论文:Attention Is All You Need
链接:https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
无论是做NLP还是做CV,这篇论文大家应该都很熟悉。Transformer是一个编码器解码器结构,其引入了位置编码,使得模型能够直接看到全局的信息,更有利于序列的长距离建模。其主要的结构Transformer Block主要由一个多头自注意力和一个前向传播网络(FFN)组成,内部的归一化使用的是Layer Normal,这可以摆脱训练批次对模型训练性能的影响。
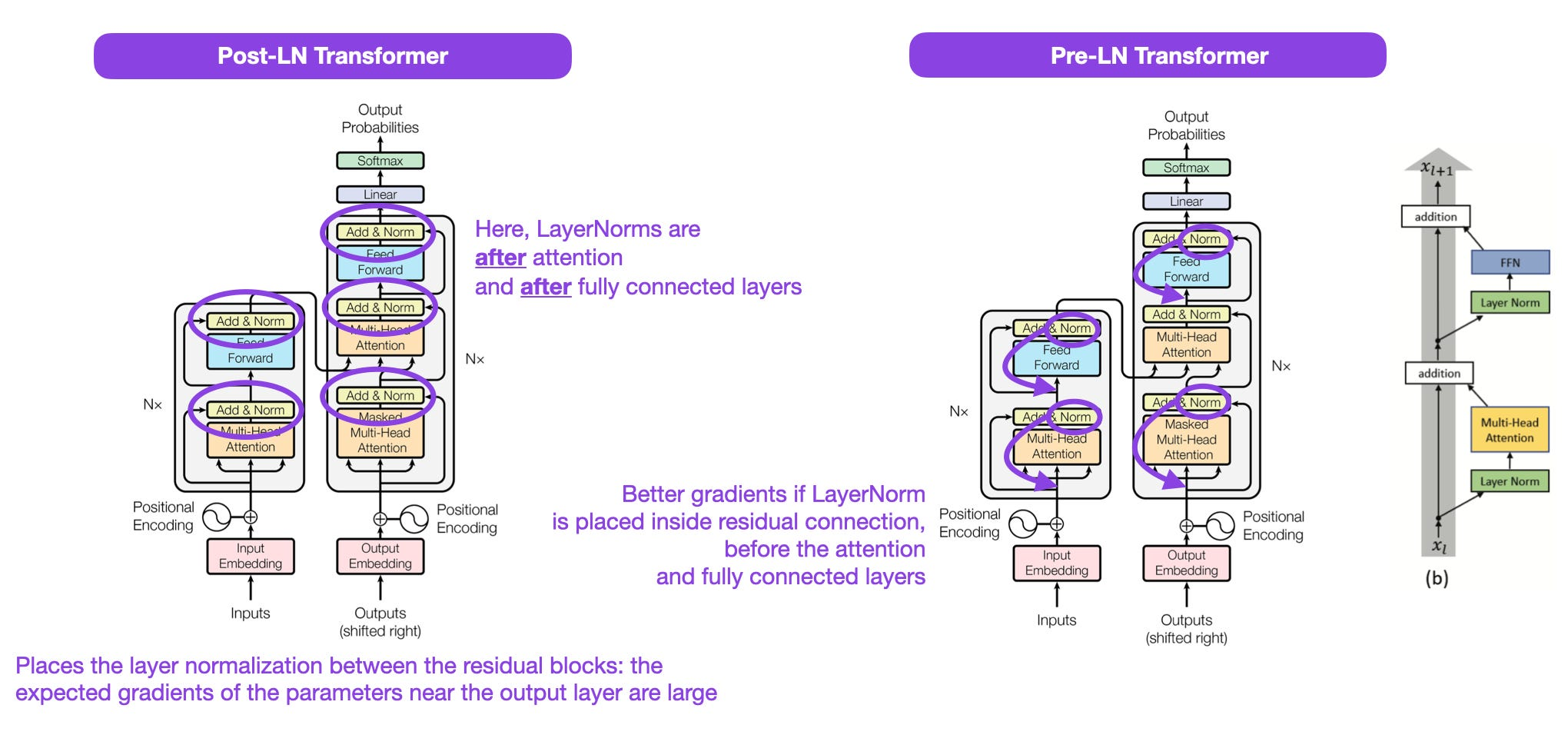
Post-LN vs Pre-LN Transformer
论文:On Layer Normalization in the Transformer Architecture
链接:https://proceedings.mlr.press/v119/xiong20b/xiong20b.pdf
该论文提出Transformer结构中的Layer Normal结构的位置应该放置在多头注意力和FFN之前。该论文表明了Pre-LN的结构比先前的Post-LN效果更佳,解决了梯度问题,许多架构在实践中采用了这一点,但表示它有可能导致崩溃。关于使用Post-LN和Pre-LN的争论目前还在,可以关注后续的发展。
NLP中的训练范式
论文:Universal Language Model Fine-tuning for Text Classification
链接:https://arxiv.org/pdf/1801.06146.pdf
预训练微调的范式最早是在CV界广泛应用。早期NLP中的预训练微调的应用不广泛,大部分研究都是从头开始训练的,少数进行的预训练微调的效果并不好,比随机初始化的结果还差,或者需要很多的数据集作为预训练的语料库。该论文根据CV模型和NLP模型不同的架构,设计了三层完全相同的LSTM网络拼接的预训练网络。

上图所示即为该论文提出的语言模型的预训练微调的范式ULMFit,其主要分为三个阶段:
- 在大量文本语料库上训练语言模型
- 在特定任务数据上微调此预训练的语言模型,使其能适应文本的特定风格和词汇。
- 对特定任务数据的分类器进行微调,逐步解冻层,避免灾难性遗忘。
这个训练范式(在大型语料库上训练语言模型,然后在下游任务上进行微调)是后续基于Transformer的模型和基础模型(如BERT、GPT-2/3/4、RoBERTa等)中使用的中心方法。
然而,在使用Transformer架构时,逐渐解冻在实践中通常不会例行完成,所有层通常都同时进行微调。
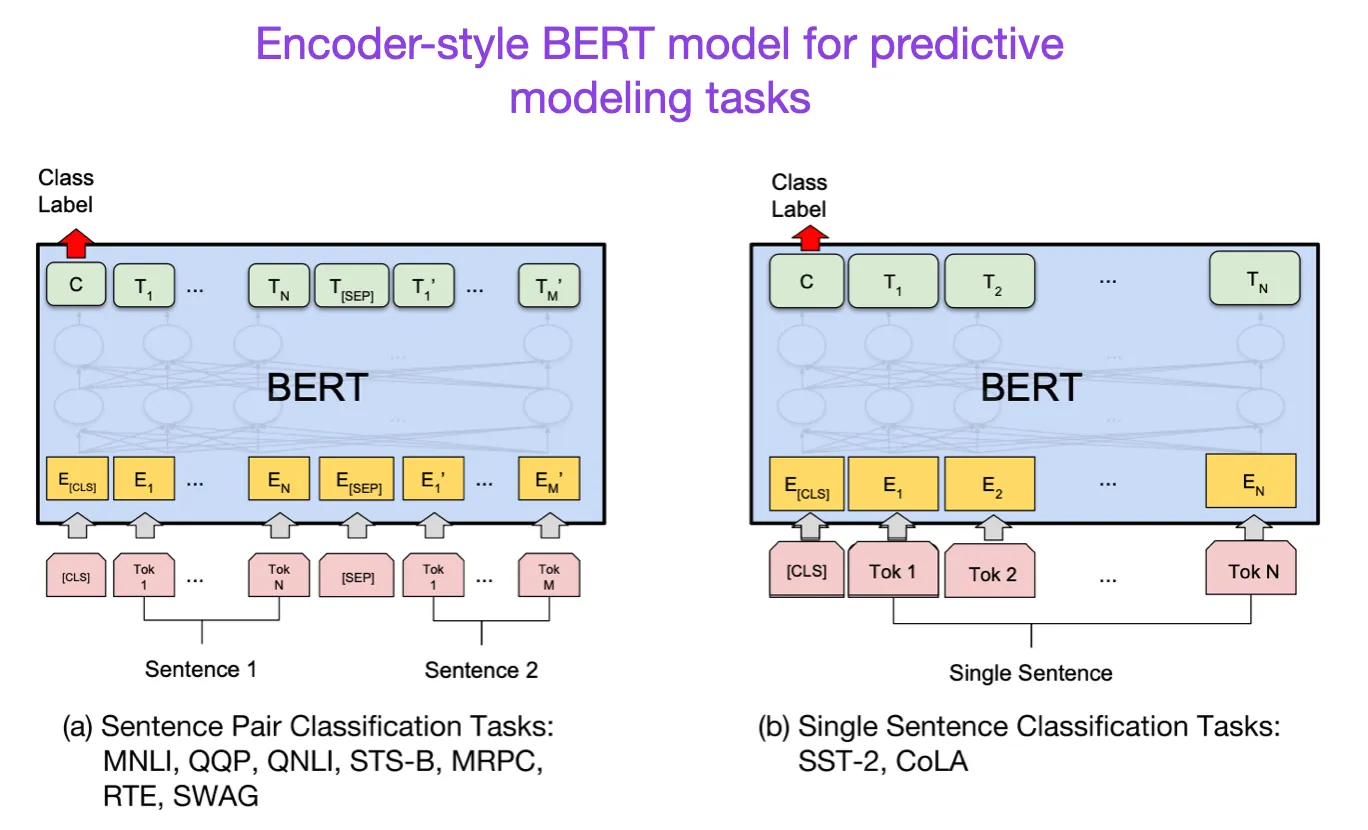
BERT
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
链接:https://arxiv.org/pdf/1810.04805.pdf
BERT模型的基础结构采用了原始的Transformer结构,但是在预训练和微调时,BERT都使用了双向Transformer模型。
BERT的训练过程分为两个阶段:
- 模型在大型语料库中对未标记的数据进行训练:(1)Masked Language Model(MLM),BERT可以关注文本左边的上下文和右边的上下文,为了让文本适应这种双向关注,使用完型填空的方式,只预测这些被屏蔽的单词,而不是重建整个输入。 (2)Next Sentence Prediction(NSP),为了训练句子之间的关系,通过上一句的信息来预测下一句。
- 载入预训练的参数初始化,所有参数使用下游任务有标记的数据进行微调。
GPT-1
论文:Improving Language Understanding by Generative Pre-Training
链接:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
先前用于不同的文本任务上需要添加额外的结构,使得模型需要定制化。GPT提出使用遍历式方法,将结构化输入转化为有序序列,这种输入转化避免了跨任务对任务对模型架构的广泛更改。具体不同如何转化看下图中的右边部分。
GPT的训练范式与BERT类似,都是现在大型无标签数据上进行训练后在有标签数据的目标任务上进行微调。只是GPT是一个解码器式的Transformer架构,它的文本建模方式为以上文为基础,去生成下面的文本(token),这表明模型只能关注左侧的信息来生成下文。GPT系列也被证明在文本生成方面的任务更加有效。

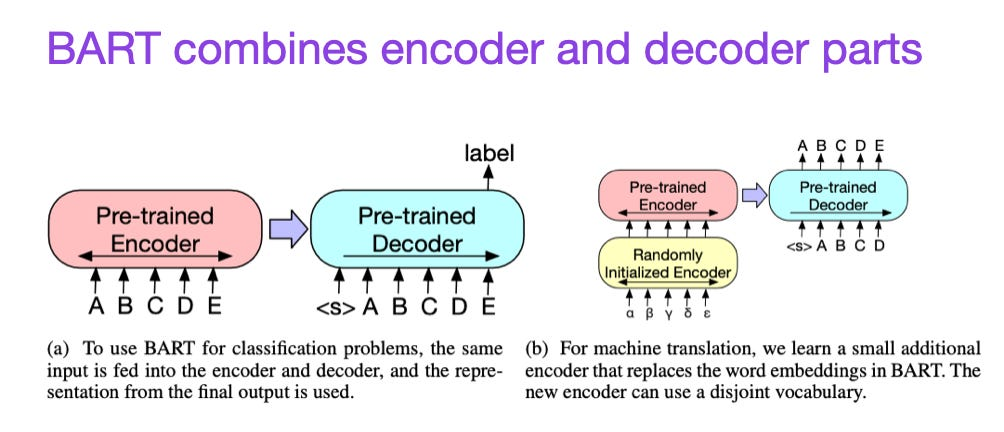
BART
论文:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
链接:https://arxiv.org/pdf/1910.13461.pdf
如前所述,BERT型编码器风格的LLM通常是预测建模任务的首选,而GPT型解码器风格的LLM更擅长生成文本。为了充分利用这两方面,BART模型结合了编码器和解码器部分。
LLM通用架构分类
论文:Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
链接:https://arxiv.org/pdf/2304.13712.pdf
遵循原始的Transformer架构,大型语言模型研究开始向两个方向分叉:用于文本分类等预测建模任务(NLU)的编码器式(Encoder-style)Transformer和用于翻译、总结和其他形式文本创建等生成建模任务(NLG)的解码器式(Decoder-style)Transformer。
主流LLM
ChatGLM
论文:GLM: General Language Model Pretraining with Autoregressive Blank Infilling
链接:https://arxiv.org/pdf/2103.10360.pdf
自动编码模型(例如BERT)、自动回归模型(例如GPT)和编码器-解码器模型(例如T5)。然而,没有一个预训练框架对三个主要类别的所有任务表现最好,包括自然语言理解(NLU)、无条件生成和条件生成。
GLM通过添加2D位置编码和允许任意顺序预测跨度来改进空白填充预训练,从而在NLU任务上比BERT和T5的性能提高。
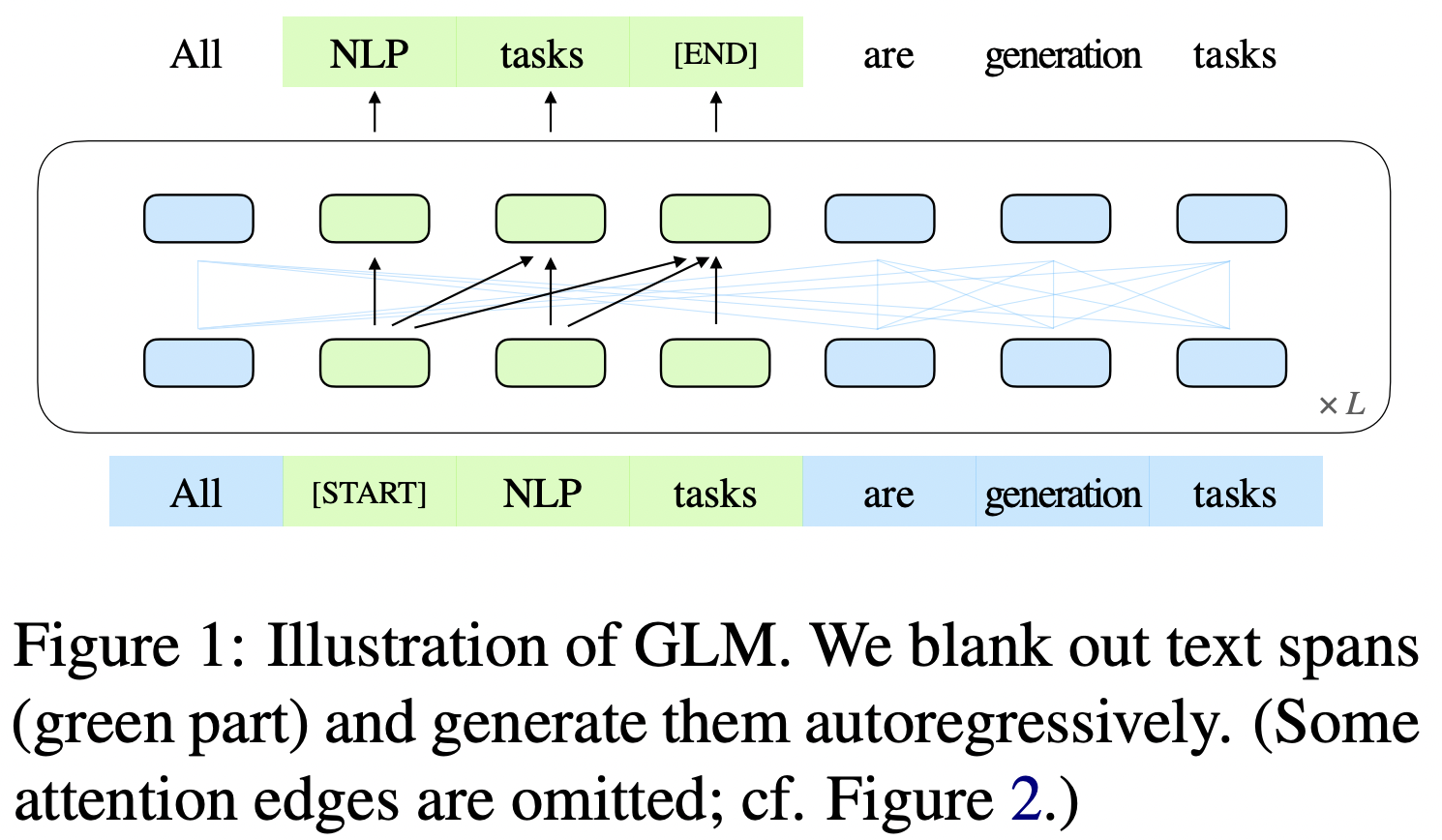
- 任务1:自动回归空白填充
- mask的token方面:(1)一个句子随机抽取连续的几个token,使用一个Span盖住,再把Span随机打乱(为了充分捕捉不同Span之前见的依赖关系,使用随机跨度顺序,类似于排列语言模型)
- 被mask的部分:(1)单向注意力(前面预测后面,带箭头)(2)不参与预测没有被mask的部分。(如下图所示)
- 没有被mask的部分:双向注意力(前后双向预测,不带箭头)
- 2D位置编码过程

其中(a)为原始序列,被分为A和B两个序列。图(d)中表示了具体的自注意力mask。
- 多任务学习:使用了Document level和Sentence level两个级别进行学习。
论文:Glm-130b: An open bilingual pre-trained model
链接:https://arxiv.org/pdf/2210.02414.pdf
GLM-130b是对标GPT-3 175B参数规模大小的模型。训练100B左右规模的模型与训练10B规模模型在训练效率、稳定性和收敛性上带来了很多技术和工程上的挑战。

上表是描述两个开源大模型工作和GPT-3以及PaLM使用的架构、语种、数据类型、稳定性策略、量化、推理要求等对比。
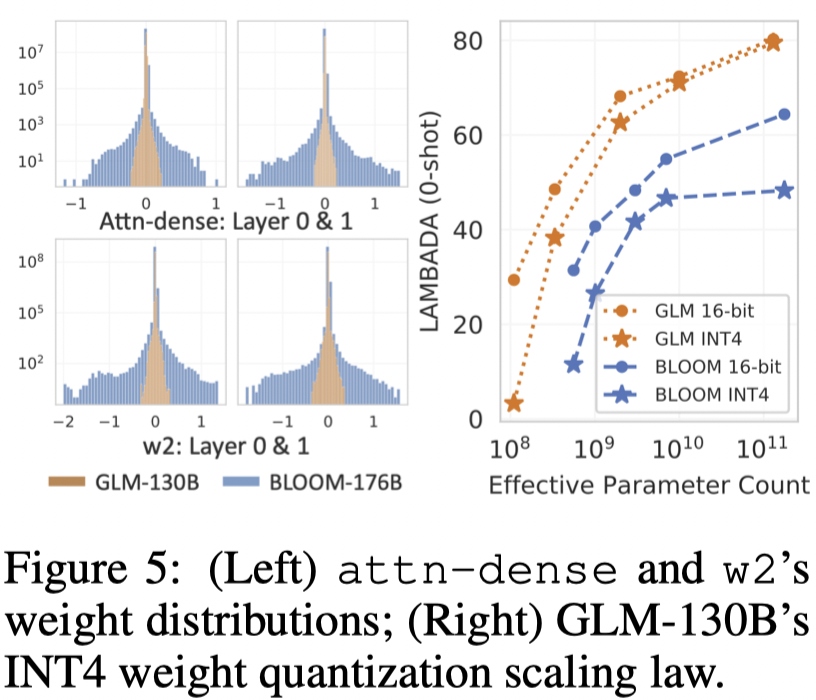
可以看到,经过量化到INT4类型后,仅需要4张3090(4$\times$24)或者8张1080Ti(8$\times$12)就可以进行130B模型的推理。

大体量LLM的训练,相对于10B规模的训练不同,需要大量的工程优化技术,且参数比较难以训练。控制训练过程中的梯度非常重要,这成为了模型是否训练成功的关键。
- INT4量化:研究团队根据不同架构模型的权重精度分布来表现量化对性能的影响,可以看到GLM的权重精度分布使得其直接进行量化后few shot性能几乎没有影响。
Qwen
论文:Qwen Technical Report
链接:https://arxiv.org/pdf/2309.16609.pdf
Baichuan
论文:Baichuan 2: Open Large-scale Language Models
链接:https://arxiv.org/pdf/2309.10305.pdf
llama
论文:LLaMA: Open and Efficient Foundation Language Models
链接:https://arxiv.org/pdf/2302.13971.pdf
GPT系列
论文:Language Models are Few-Shot Learners
DeepSeek
论文:DeepSeek LLM Scaling Open-Source Language Models with Longtermism
链接:https://arxiv.org/pdf/2401.02954.pdf
数据
为了全面增强数据集的丰富性和多样性,将数据收集的手段的方法分为了三个阶段:数据删除、过滤和重新混合。
架构
DeepSeek LLM的微观设计在很大程度上遵循了LLaMA的设计,采用具有RMSNorm功能的Pre-Norm结构,并使用SwiGLU作为前馈网络的激活函数,中间层尺寸为38d模型。它还纳入了旋转嵌入用于位置编码。为了优化推理成本,67B模型使用GroupedQuery Attention,而不是传统的多头注意力。
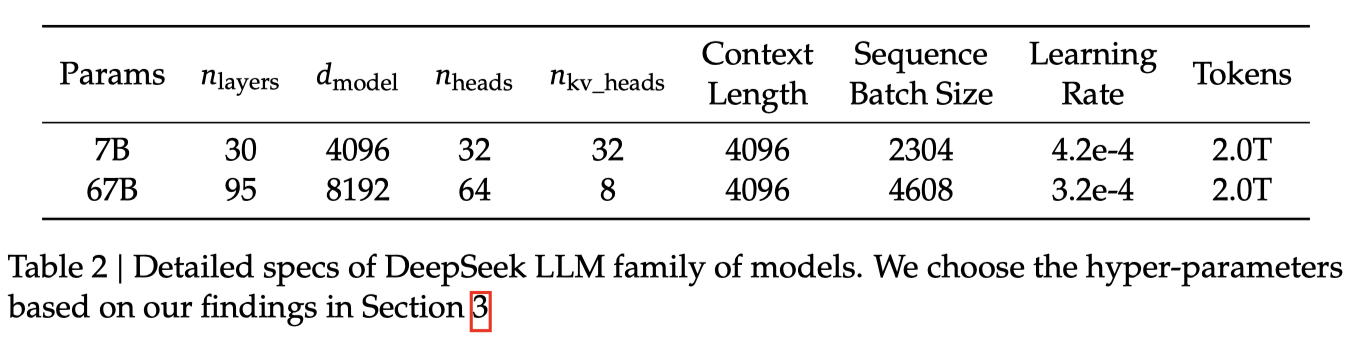
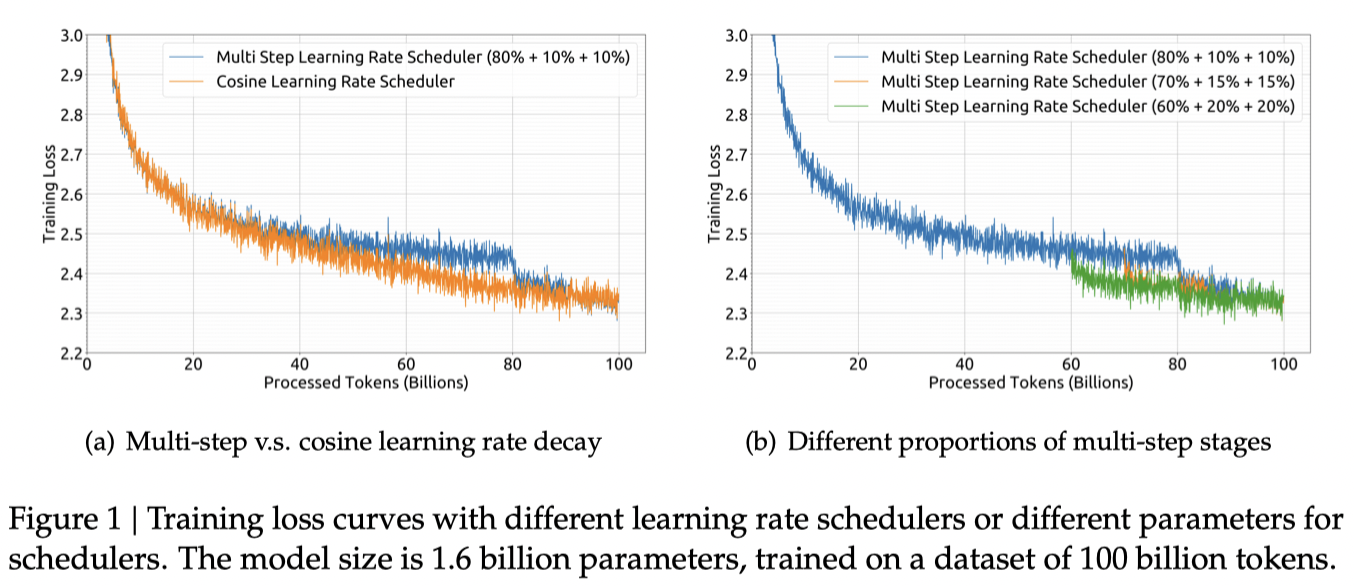
DeepSeek一共有两个版本的模型,分别是7B和67B。DeepSeek在模型训练上没有使用传统的余弦退火学习策略。而采用了多步学习率下调策略,可以看到下图是他们训练结果的区别。
LLM训练
Common NLU和NLG任务
NLU (Natural Language Understanding) 和 NLG (Natural Language Generation) 是自然语言处理中常见的任务类型。
- NLU 任务(自然语言理解):
- 文本分类:将文本分为不同的类别,如情感分类、主题分类等。
- 命名实体识别(NER):从文本中识别并标记出命名实体,如人名、地名、组织机构等。
- 意图识别(Intent Recognition):从用户输入的文本中识别用户的意图或目的,常用于对话系统中。
- 语义角色标注(Semantic Role Labeling):为句子中的每个单词或短语标注其在句子中扮演的语义角色,如施事者、受事者、时间等。
- 语义解析(Semantic Parsing):将自然语言转换为结构化的表示形式,如逻辑形式或查询语言,以便进行进一步的处理。
- NLG 任务(自然语言生成):
- 文本生成:根据给定的输入或上下文生成自然语言文本,如自动摘要、机器翻译等。
- 问答生成(Question Answering Generation):根据问题生成相应的回答。
- 对话生成:在对话系统中生成自然语言回复,使其与用户进行交互。
- 文本摘要生成:从大量文本中生成简洁的概括性摘要。
- 生成式对话系统:构建能够进行连贯、有逻辑的对话的系统,使其能够与人类进行自然交流。
大模型应用训练选择
论文:Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
链接:https://arxiv.org/pdf/2304.13712.pdf
下图是制作一个大模型应用的选择流程,主要涉及目标任务的难度、类型、以及标签数据是否丰富等。其中LLMs是指使用原生的预训练LLM搭配不同的Prompt来完成任务,而Fine-tuned Models则是LLM模型对目标任务的数据进行参数调整。
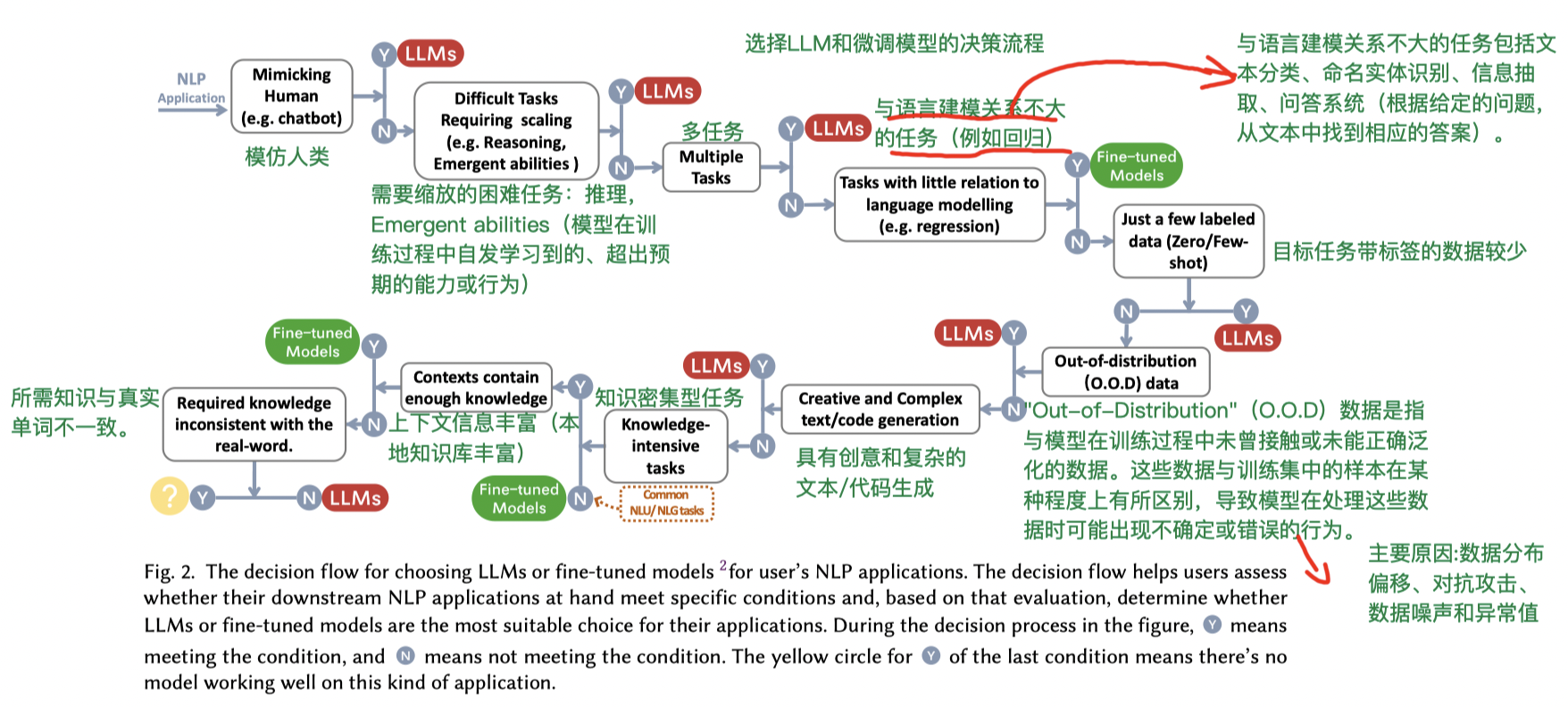
选择LLM模型与微调模型?
- 在面临非分布数据(如对抗性示例和领域转移)的下游任务中,LLM比微调模型更通用。
- 在处理有限的注释数据时,LLM比微调模型更可取,当有丰富的注释数据可用时,两者都可以成为合理的选择,具体任务要求。
- 建议在类似于下游任务的数据字段上选择LLM。
- 在为下游任务选择LLM时,最好选择在类似数据领域进行预训练的模型。
- 进行下游任务时需要考虑注释数据的可用性。没有注释时,直接使用预训练的LLM模型;上下文学习: 将一些例子包含在LLM的输入提示中;如果目标任务的数据很丰富,可以考虑微调模型参数或者直接用LLM。
- RLHF方法可以显著增强LLM的泛化能力。
- 在大多数自然语言理解任务中带有丰富的注释数据,并且在测试集中包含很少的分布外示例,则微调模型仍然具有更好的性能。
- 由于大模型的生成能力和创造力,LLM在大多数生成任务上表现出较强的优势。
- LLM擅长要求模型全面了解输入内容和要求,并具有一定的创造能力的任务,比如文本总结,机器翻译,开放式生成。
PEFT
论文:Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
链接:https://arxiv.org/pdf/2303.15647.pdf
关于PEFT的内容,在大模型高效微调博文中已经仔细分析,这里通过综述论文进行一定的总结。
该论文将所有的论文分为了3种大类方法:
- Additive methods:这种方法背后的主要想法是用额外的参数或层增强现有的预训练模型,并仅训练新添加的参数。
- Selective methods: 这种方法主要是通过自由选择网络的一些层进行微调,例如调整偏置(bias)等,以及一些稀疏更新的方法,然而不受限制的非结构化稀疏性在当代硬件上很难得到很好的加速。
- Reparametrization-based methods: 该类别方法使用了低秩矩阵分解的原理,最大限度地减少可训练的参数。
检索增强生成
论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
链接:https://proceedings.neurips.cc/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
该论文针对序列到序列(seq2seq)模型的”幻觉”问题,提出了一种检索增强生成的问题。
大模型通常在知识密集型任务上低于特定任务架构的性能。该文提出的RAG只要由参数存储器(参数可调整模型)和非参数存储器相结合,如下图所示。其中编码器和检索器组成了非参数存储器,而生成器(后面演变成LLM)充当参数存储器。
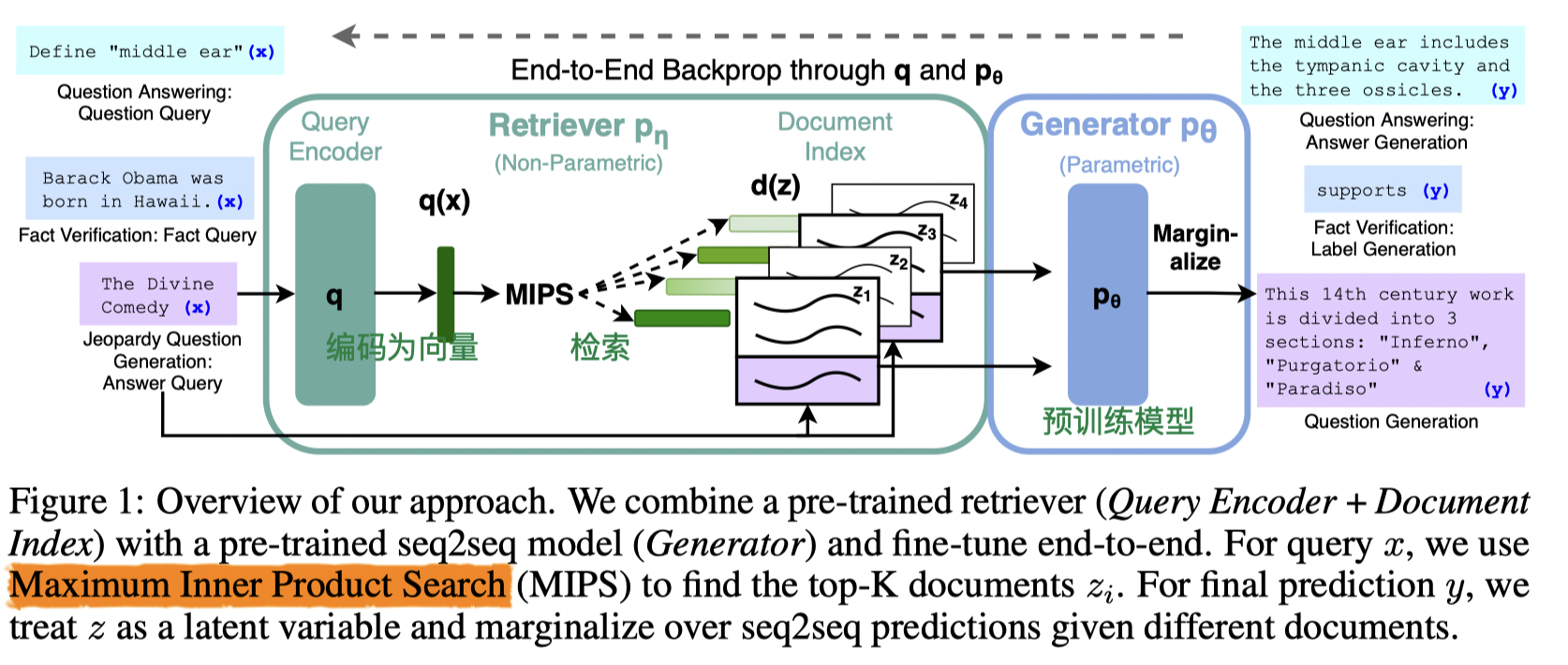
RAG有两种训练范式:
- RAG-Sequence Model:使用序列级别的检索来增强生成模型。生成模型负责生成目标序列,检索模型负责从候选文档集中选择相关的文档或片段,组合模块将生成模型和检索模型的输出结合起来,以生成最终的结果。
- RAG-Token Model:将检索模型的输出直接融入到生成模型中,而不是作为上下文输入。具体而言,RAG-Token Model将检索模型的输出表示为一个可学习的标记嵌入向量,并将其与输入序列的标记嵌入向量进行拼接或加权求和。
为了深入理解这种区别,我们将BART模型分别作为分词器和生成器,使用代码来解释这种区别。
- RAG-Sequence Model:
|
|
- RAG-Token Model:
|
|
RLHF训练
最后修改于 2024-01-19

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。