LLaMA-Factory:大模型的训练工厂
Github官网:https://github.com/hiyouga/LLaMA-Factory
LLaMA-Factory集成了几乎市面上所有的开源大模型架构的训练,也集成了Full、Freeze、LoRA、QLoRA等主流训练方法,以及各种数据精度(16、8、4、2)的训练。
训练框架部署
- 如果你使用conda管理python环境,则使用如下命令:
1
2
3
4
5
|
conda create -n LLaMA-Factory python=3.10
conda activate LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
|
- 如果你使用Docker部署,可以直接执行说明书指出的
Build without Docker Compose:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
docker build -f ./docker/docker-cuda/Dockerfile \
--build-arg INSTALL_BNB=false \
--build-arg INSTALL_VLLM=false \
--build-arg INSTALL_DEEPSPEED=false \
--build-arg INSTALL_FLASHATTN=false \
--build-arg PIP_INDEX=https://pypi.org/simple \
-t llamafactory:latest .
docker run -dit --gpus=all \
-v ./hf_cache:/root/.cache/huggingface \
-v ./ms_cache:/root/.cache/modelscope \
-v ./data:/app/data \
-v ./output:/app/output \
-p 7860:7860 \
-p 8000:8000 \
--shm-size 16G \
--name llamafactory \
llamafactory:latest
docker exec -it llamafactory bash
|
根据个人需要,我需要对一些文件进行修改之后,再构建镜像:
原本的文件内容:
.vscode
.git
.github
.venv
cache
data
docker
saves
hf_cache
output
.dockerignore
.gitattributes
.gitignore
其中docker是部署需要的文件,saves是模型微调后保存权重的位置,data是数据集保存的位置。由于我后续需要先制作数据集并拷贝进容器,所以需要把data去掉,修改后的文件内容:
.vscode
.git
.github
.venv
cache
docker
saves
hf_cache
output
.dockerignore
.gitattributes
.gitignore
- 修改
docker/docker-cuda/Dockerfile的内容,修改pip源,修改下载环境的参数,将内容中的设置卷去掉:
1
2
3
4
5
6
7
8
9
|
# Define installation arguments
ARG INSTALL_BNB=false
ARG INSTALL_VLLM=true
ARG INSTALL_DEEPSPEED=false
ARG INSTALL_FLASHATTN=false
ARG PIP_INDEX=https://pypi.tuna.tsinghua.edu.cn/simple
# Set up volumes
# VOLUME [ "/root/.cache/huggingface", "/root/.cache/modelscope", "/app/data", "/app/output" ]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
docker build -f ./docker/docker-cuda/Dockerfile \
-t llamafactory:latest .
# 映射的做法,将本地文件映射到容器中进行操作
# model_hub存放大模型相关的权重
# 也可以去掉-v相关的内容,容器启动后使用docker cp将需要的文件传进去
docker run -itd --gpus all \
-v ./data:/app/data \
-v ./output:/app/output \
-v ./model_hub:/app/model_hub \
-p 7860:7860 \
-p 8000:8000 \
--shm-size 16G \
--name llamafactory \
llamafactory:latest
docker exec -it llamafactory /bin/bash
|
数据集准备
由于我们常用的场景通常为对话问答场景,中文相关的问答数据在data文件夹下的alpaca_zh_demo.json有说明:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[
{
"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。",
"input": "",
"output": "细胞理论是生物科学的一个理论,它认为所有生命体都是由微小的基本单元——细胞所构成。这是生物学的一个基础理论,认为细胞是所有生物的基本结构和功能单位,所有的生物都是由一个或多个细胞组成,细胞只能通过细胞分裂产生新的细胞。这一理论由薛定谔、施瓦内和雪莱于1839年首次提出。\n\n日心说是指太阳是太阳系的中心,也就是说,行星围绕太阳旋转的理论。这个理论打破了传统的地心说观点,认为地球并不是宇宙的中心。日心说的提出者是尼古拉·哥白尼,他在16世纪初发表了他的著作《天体运行论》,阐述了太阳系行星围绕太阳运行的模型,为天文学的发展做出了巨大贡献。"
},
...
{
"instruction": "输入三支篮球队的名称并生成一个适当的口号。",
"input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。",
"output": "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\""
}
]
|
instruction中的内容代表指令,也就是你需要让大模型干什么事,这往往是和大模型的系统提示词相关的。然后定义输入和输出。
数据集的数据组织方式
一个比较简单的方式,就是根据你需要大模型做的一个提示词来生成相关的数据。举一个CoT风格的提示词例子:
系统提示词:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
你是一个高级自然语言处理专家,专注于解决复杂的文本分析任务。你的任务是分析一段文本,识别其中的情感倾向,并提供详细的推理过程。请按照以下步骤操作:
1. **文本输入**:接收用户提供的文本段落。
2. **初步分析**:对文本进行初步的情感分析,识别可能的情感倾向。
3. **深入分析**:详细分析文本中的关键词和短语,确定情感的具体类型(如正面、负面、中性)。
4. **推理过程**:列出所有支持你情感分析结论的关键证据和逻辑推理步骤。
5. **输出结果**:总结你的分析和推理过程,提供一个明确的情感倾向结论。
**注意事项**:
- 确保分析过程中考虑文本的上下文和语境。
- 避免仅基于单一词汇做出判断,要综合考虑整个文本段落。
- 推理过程要详细且逻辑清晰,便于理解和验证。
**输出样例**:
- 输入文本:"今天天气真好,阳光明媚,我感到非常愉快。"
- 输出结果:情感倾向为正面。推理过程:1. 文本中提到“天气真好”和“阳光明媚”,这些词汇通常与正面情感相关。2. “感到非常愉快”直接表明了正面情感。综合以上分析,确定情感倾向为正面。
|
用户提示词:
1
|
我今天吃了一个汉堡,它很好吃,而且我只花了5块钱。
|
我们可以生成如下的数据样例:
1
2
3
4
5
6
7
|
[
{
"instruction": "请分析以下文本的情感倾向,并提供详细的推理过程。确保考虑文本的上下文和语境,避免仅基于单一词汇做出判断。推理过程要详细且逻辑清晰,便于理解和验证。",
"input": "文本:'我昨天去了一家新开的餐厅,食物非常美味,服务也很周到,我感到非常满意。'",
"output": "情感倾向:正面\n\n推理过程:\n1. 文本中提到“食物非常美味”,这是一个明显的正面评价,表明用户对食物的质量感到满意。\n2. “服务也很周到”进一步强化了正面情感,因为良好的服务体验通常会提升整体满意度。\n3. “我感到非常满意”直接表达了用户的正面情感,确认了整体的正面评价。\n\n结论:根据上述分析,文本的情感倾向为正面。"
}
]
|
将制作好的数据集放在data目录下,并在data/dataset_info.json文件中加入新的字段:
1
2
3
4
5
|
{
<自定义数据集名称>: {
"file_name": <数据集所在位置文件>
}
}
|
你也可以将数据集的字段多写一些!
在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction + “\n” + input。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
包含所有可选字段的数据集格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
|
对于上述格式的数据,dataset_info.json中的数据集描述应为:
1
2
3
4
5
6
7
8
9
10
|
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
|
然后,你就可以在训练的配置文件中使用这个数据集了!
训练参数详解
我的习惯是通过调整examples文件夹的配置文件来修改训练、验证、推理、模型合并等。
- 训练,这里只讲最常用的LoRA训练参数解析,找到
train_lora下面的llama3_lora_sft.yaml文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
### model
model_name_or_path: model_hub/qwen/Qwen2-7B-Instruct # 本地的模型路径(如果是docker则是容器内的路径)
### method (这部分的参数主要是选择使用什么训练方法,不需要改)
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
### dataset (数据集必须要选dataset_info.json中注册的数据集)
dataset: zhidian_data_3000, alpaca_zh_demo
template: qwen
cutoff_len: 4096 # 模型最大长度,也就是模型训练完成之后的最大上下文长度,一般是1024的倍数(instrcution + input + output)
max_samples: 1000 # 每个数据集的最大样本数,假设你的数据集大小超过了1000,则需要调整
overwrite_cache: true
preprocessing_num_workers: 4 # 数据集读取使用的线程数
### output
output_dir: saves/qwen/Qwen2-7B-Instruct/lora/sft1 # 输出的lora权重路径
logging_steps: 10 # 日志的记录步数(一般会记录学习率、损失等信息)
save_steps: 500 # 权重检查点的保存步数
plot_loss: true # 是否进行画图
overwrite_output_dir: true # 是否覆盖训练的路径
### train
per_device_train_batch_size: 1 # 训练的batch
gradient_accumulation_steps: 8 # 梯度累计步数
learning_rate: 1.0e-4 # 基础学习率
num_train_epochs: 2.0 # 训练的epoch数
lr_scheduler_type: cosine # 学习率优化的方法
warmup_ratio: 0.1 # warm up热身训练比
bf16: true # 使用bf16数据进行训练
ddp_timeout: 180000000
### eval
val_size: 0.1 # 验证集占训练过程的比例
per_device_eval_batch_size: 1 # 验证集每次验证的样本数
eval_strategy: steps # 评估使用的步数计量
eval_steps: 500 # 500个step进行一次评估,一般来说都会与训练保存权重的steps保持一致
|
运行如下命令:
1
2
|
CUDA_VISIBLE_DEVICES=<你的gpu id> \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
|
这些只是最基础的一些设置,你也可以使用训练面板去训练,往往参数会更详细一些,运行如下命令打开面板:
然后在浏览器打开<ip地址>:7860打开训练面板,进行设置训练参数。如果要改端口号需要先输入,export GRADIO_SERVER_PORT=<端口号>再运行上述命令即可。
界面预览:
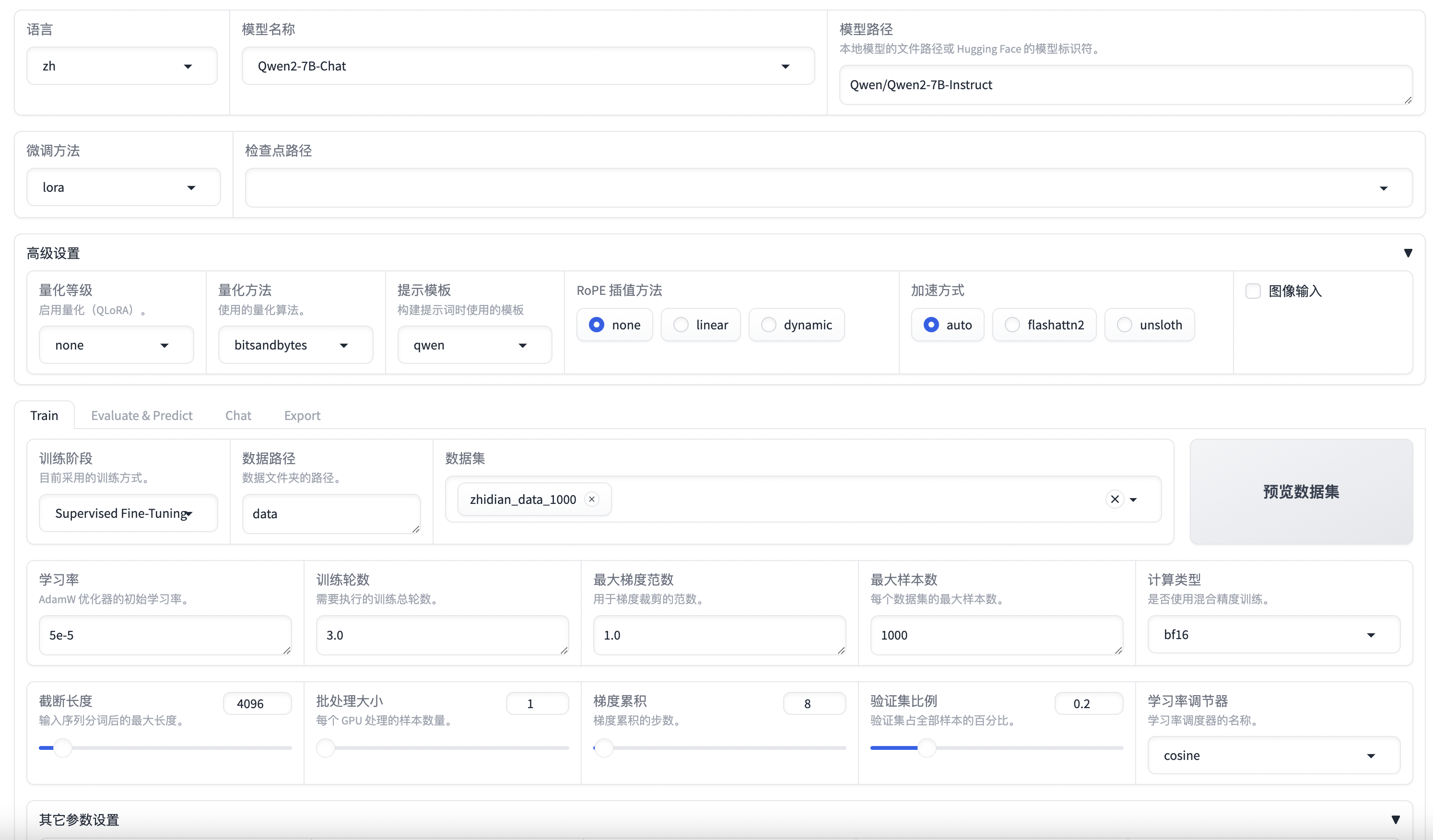
在设置好训练参数后,点击预览命令,会生成命令行的命令。
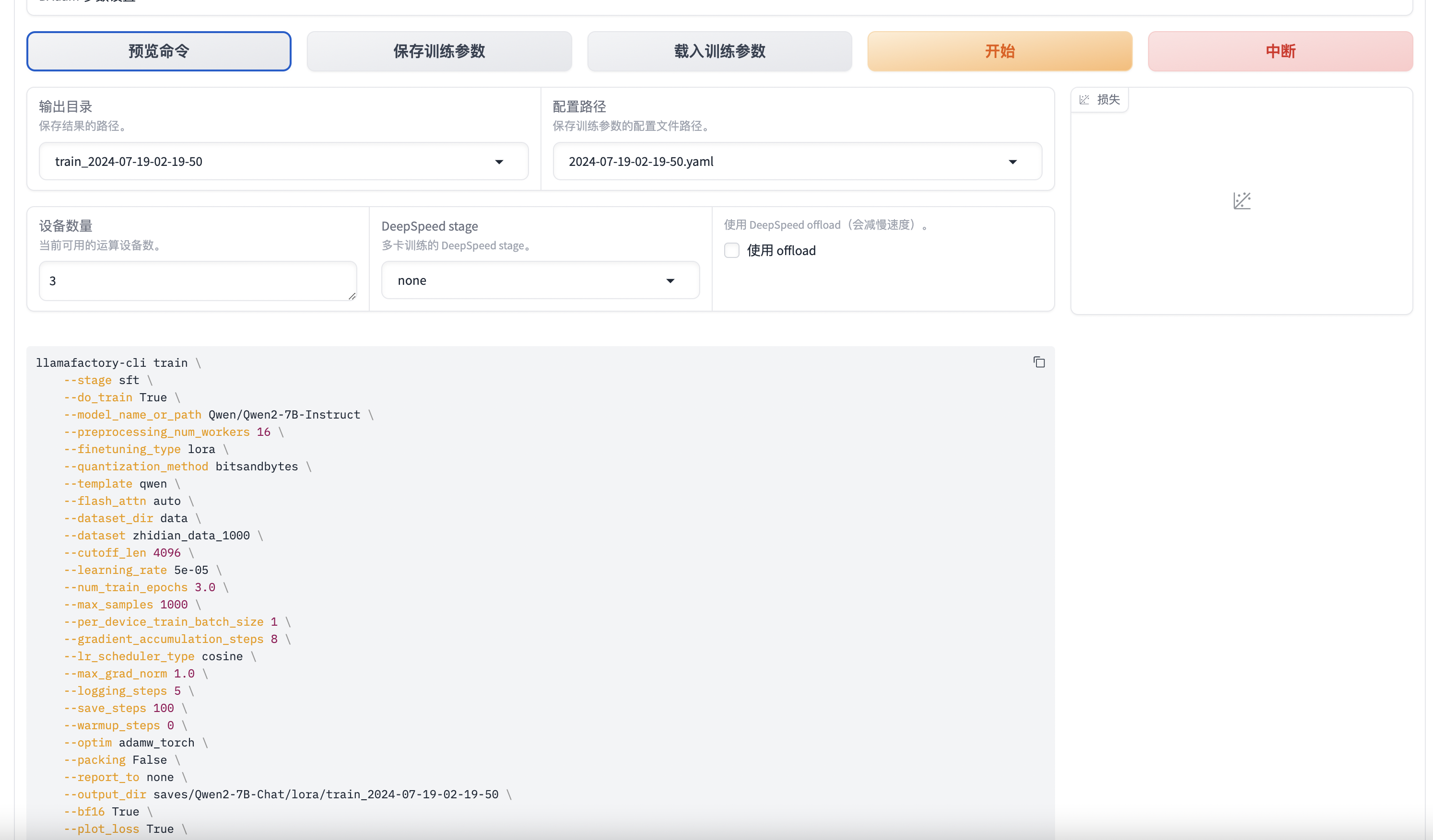 复制出来,在前面加上
复制出来,在前面加上CUDA_VISIBLE_DEVICES=<gpu-ids>在命令行运行开始训练。
训练完之后之后的推理接口以及大模型与LoRA权重合并,分别使用如下命令:
1
2
|
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
|
修改里面的参数再运行即可,其中chat命令对应的端口号是8000,如果想要修改端口号同样要先修改环境变量,export API_PORT=<端口号>再运行命令。你也可以直接在命令之前加上环境变量的取值。
1
|
API_PORT=10000 chat examples/inference/llama3_lora_sft.yaml
|
注意:使用容器的话修改了端口号,必须要宿主机的端口映射进入容器中的端口号,这样才能正确访问
运行脚本编写
1
2
|
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 nohup llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml > output.log 2>&1 &
|
运行./train.sh。
- 多个运行任务(后台运行,并行),
train.sh:
1
2
3
4
|
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 nohup llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml > output.log 2>&1 &
CUDA_VISIBLE_DEVICES=0 nohup llamafactory-cli train examples/train_lora/llama3_lora_sft-1.yaml > output-1.log 2>&1 &
CUDA_VISIBLE_DEVICES=0 nohup llamafactory-cli train examples/train_lora/llama3_lora_sft-2.yaml > output-2.log 2>&1 &
|
运行./train.sh。
1
2
3
4
|
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml > output.log 2>&1
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/train_lora/llama3_lora_sft-1.yaml > output-1.log 2>&1
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/train_lora/llama3_lora_sft-2.yaml > output-2.log 2>&1
|
运行nohup bash train.sh &。
最后修改于 2024-07-18

本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。