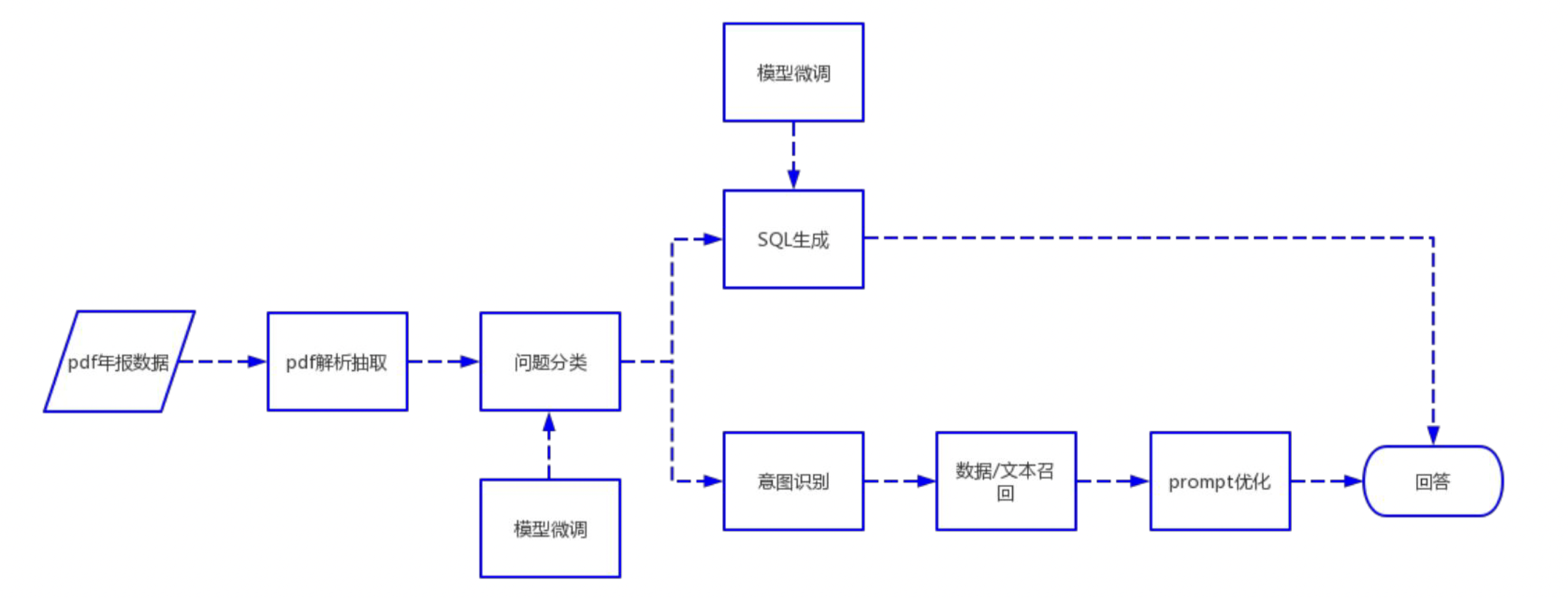
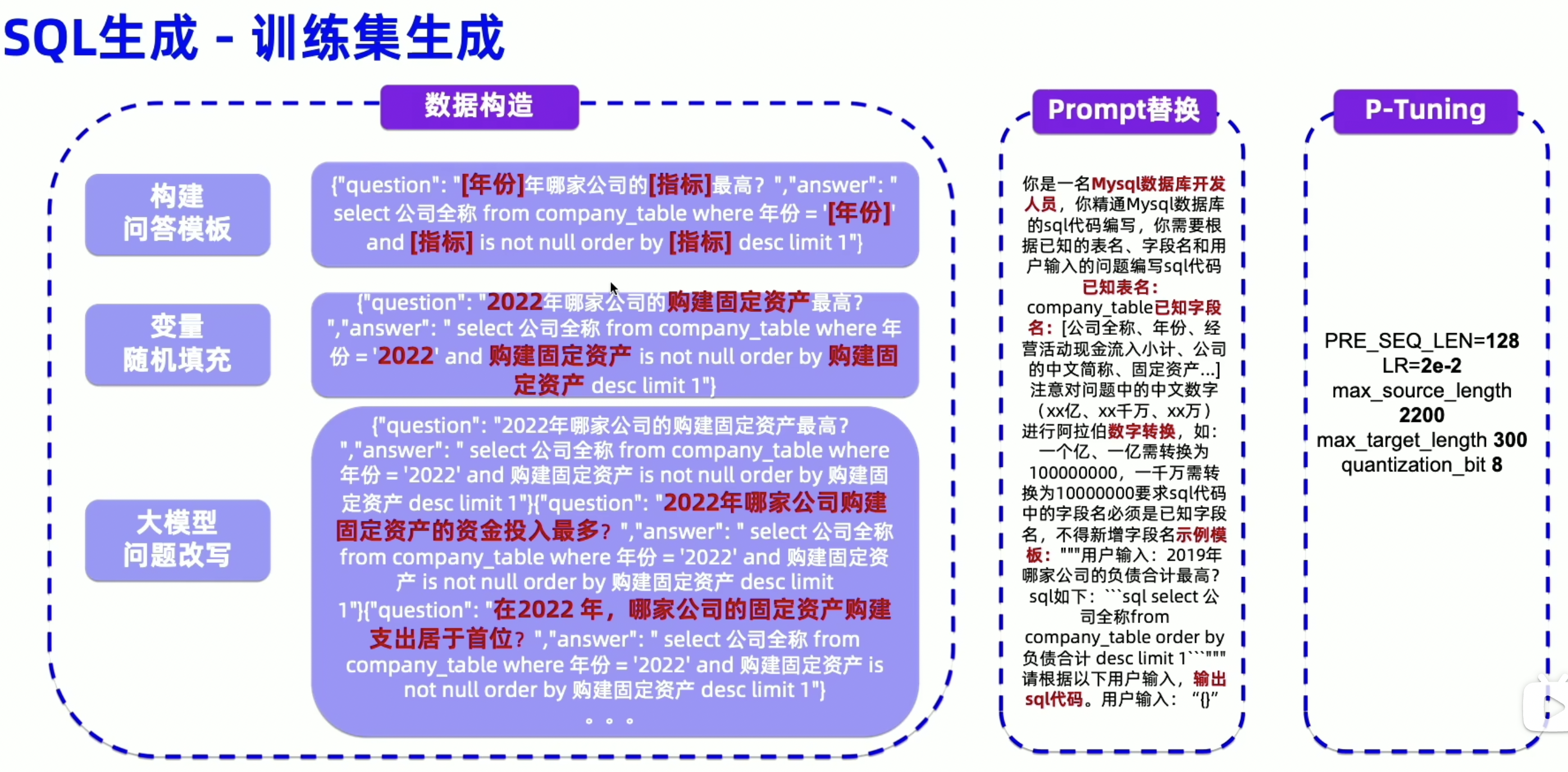
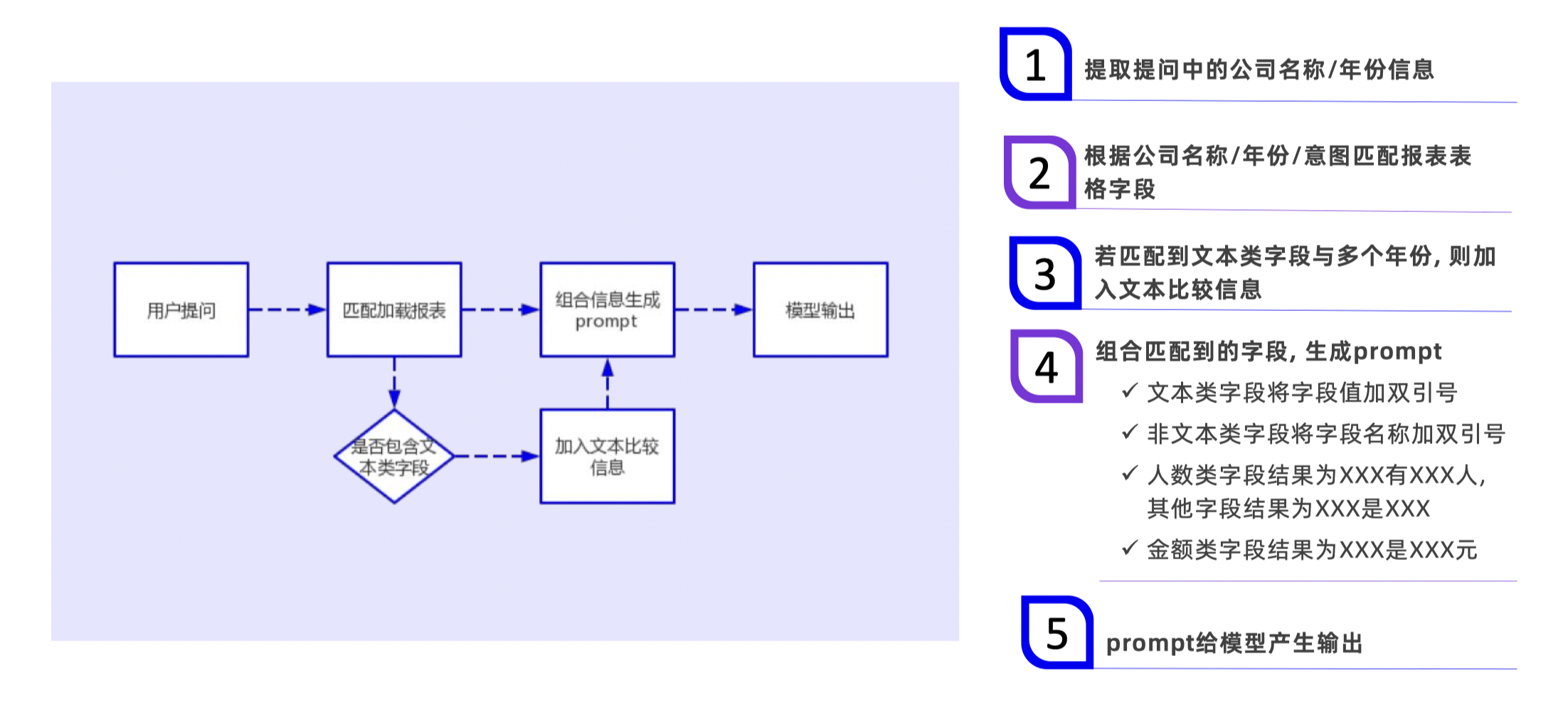
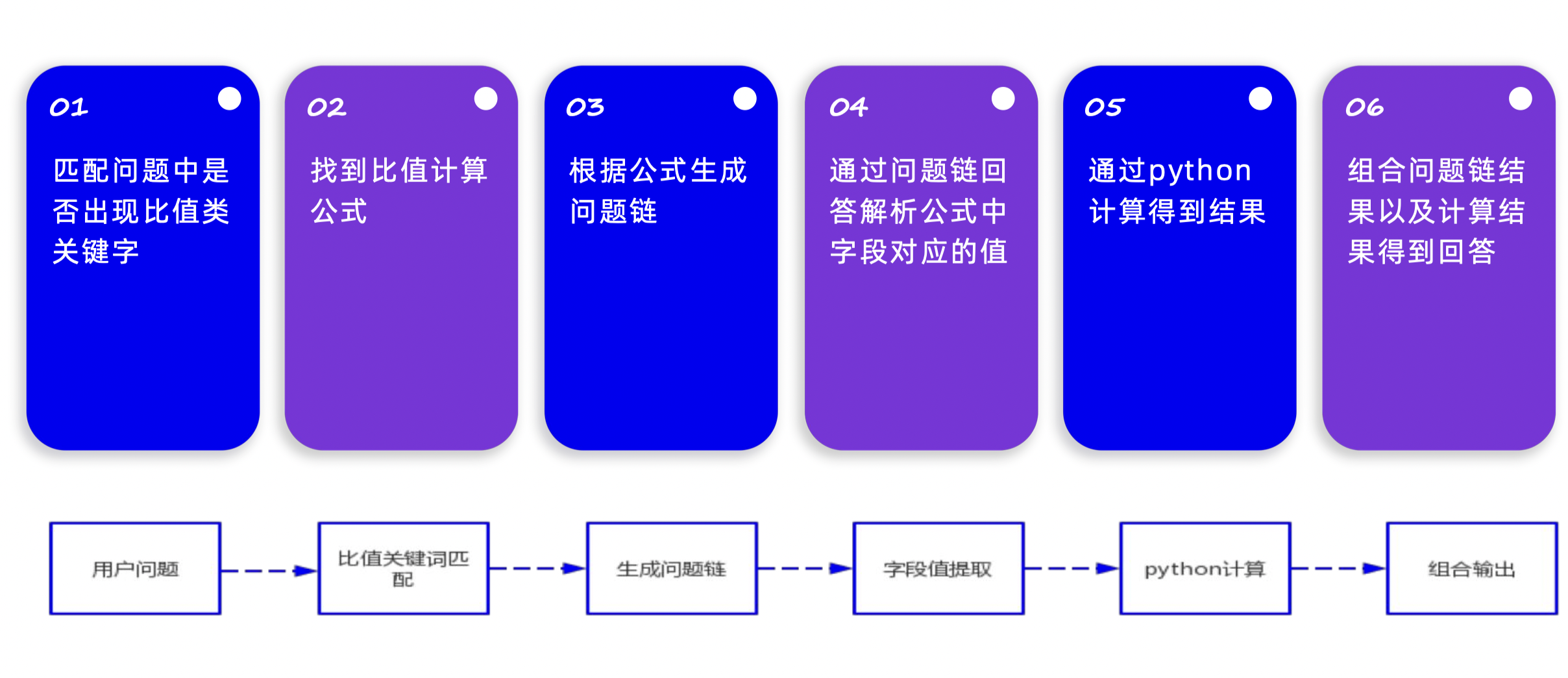
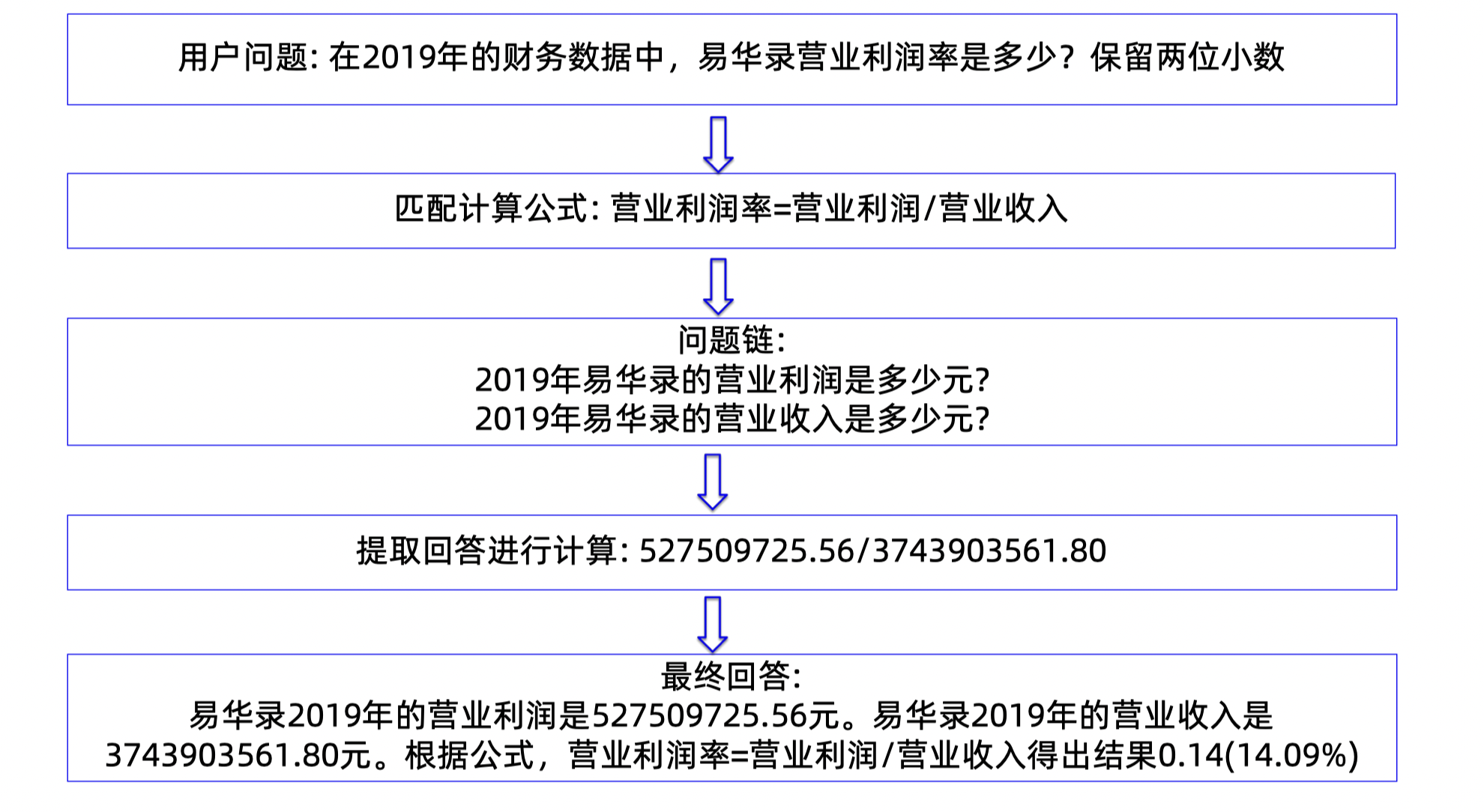
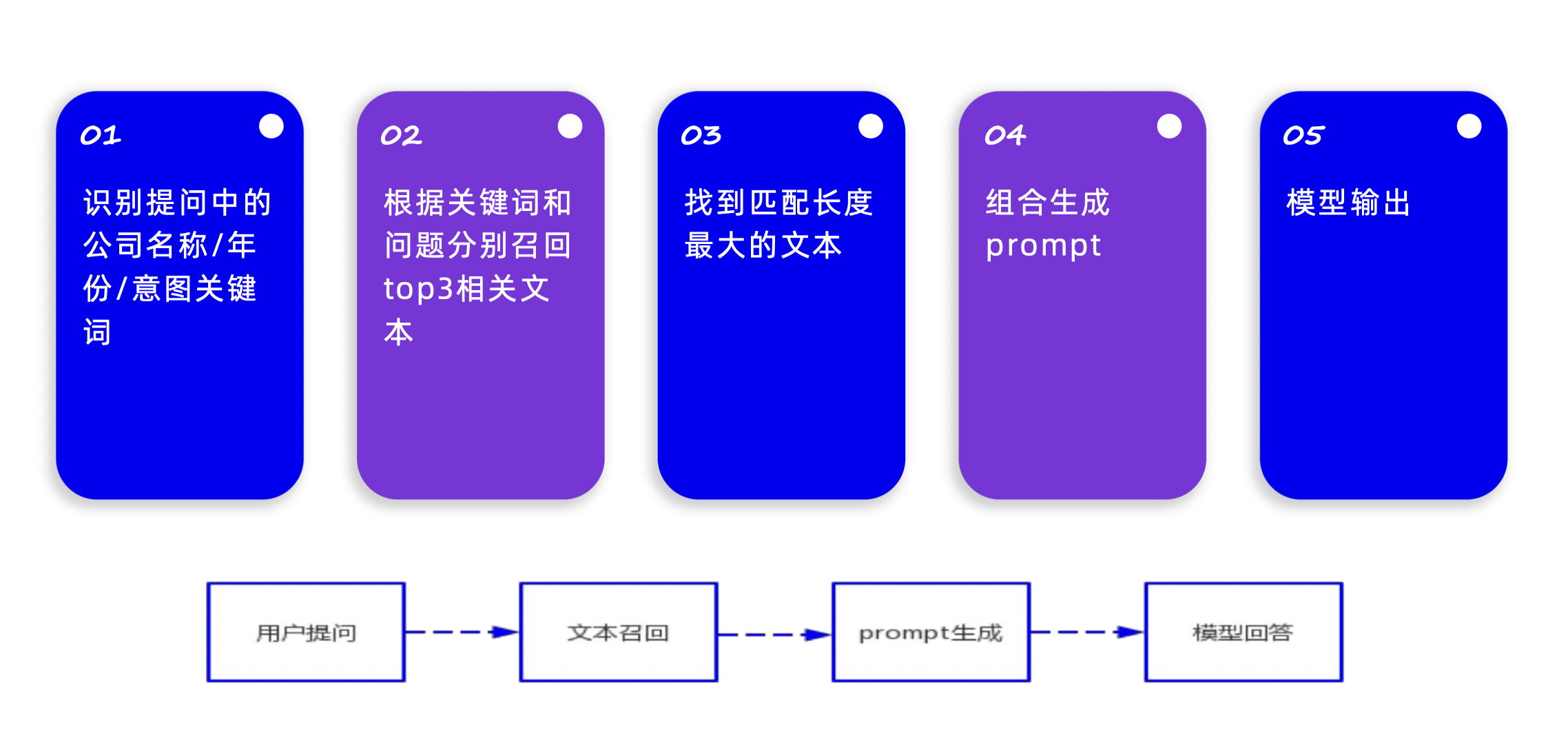
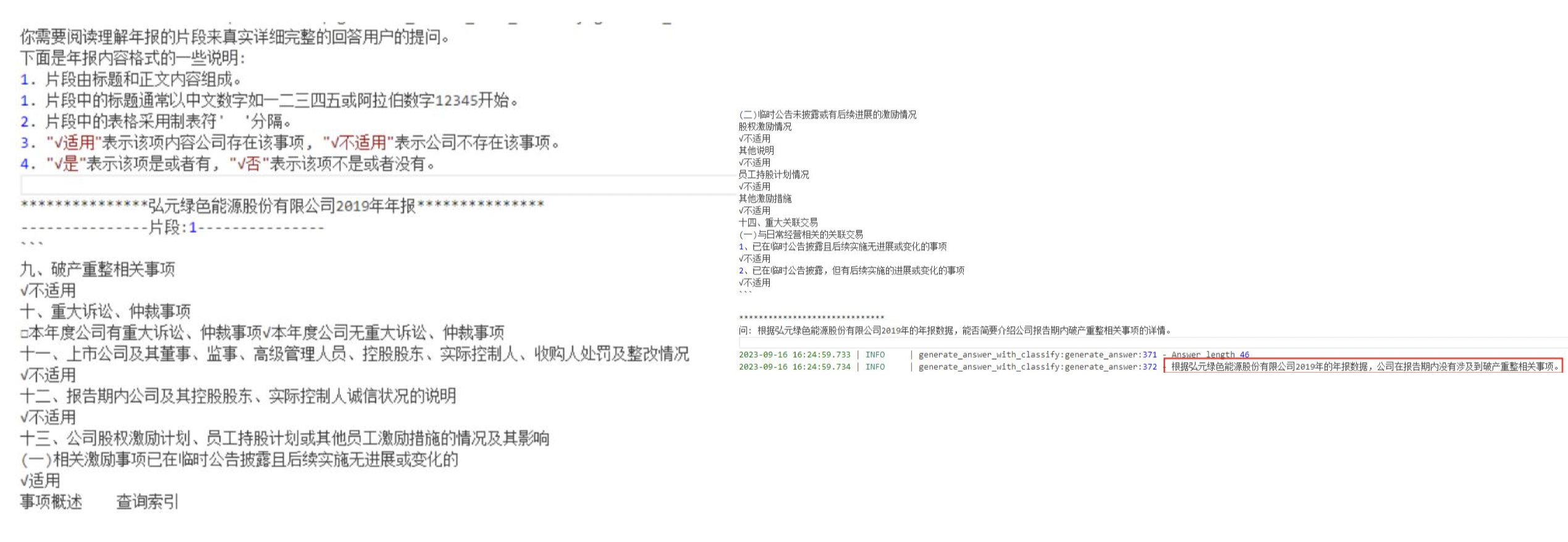
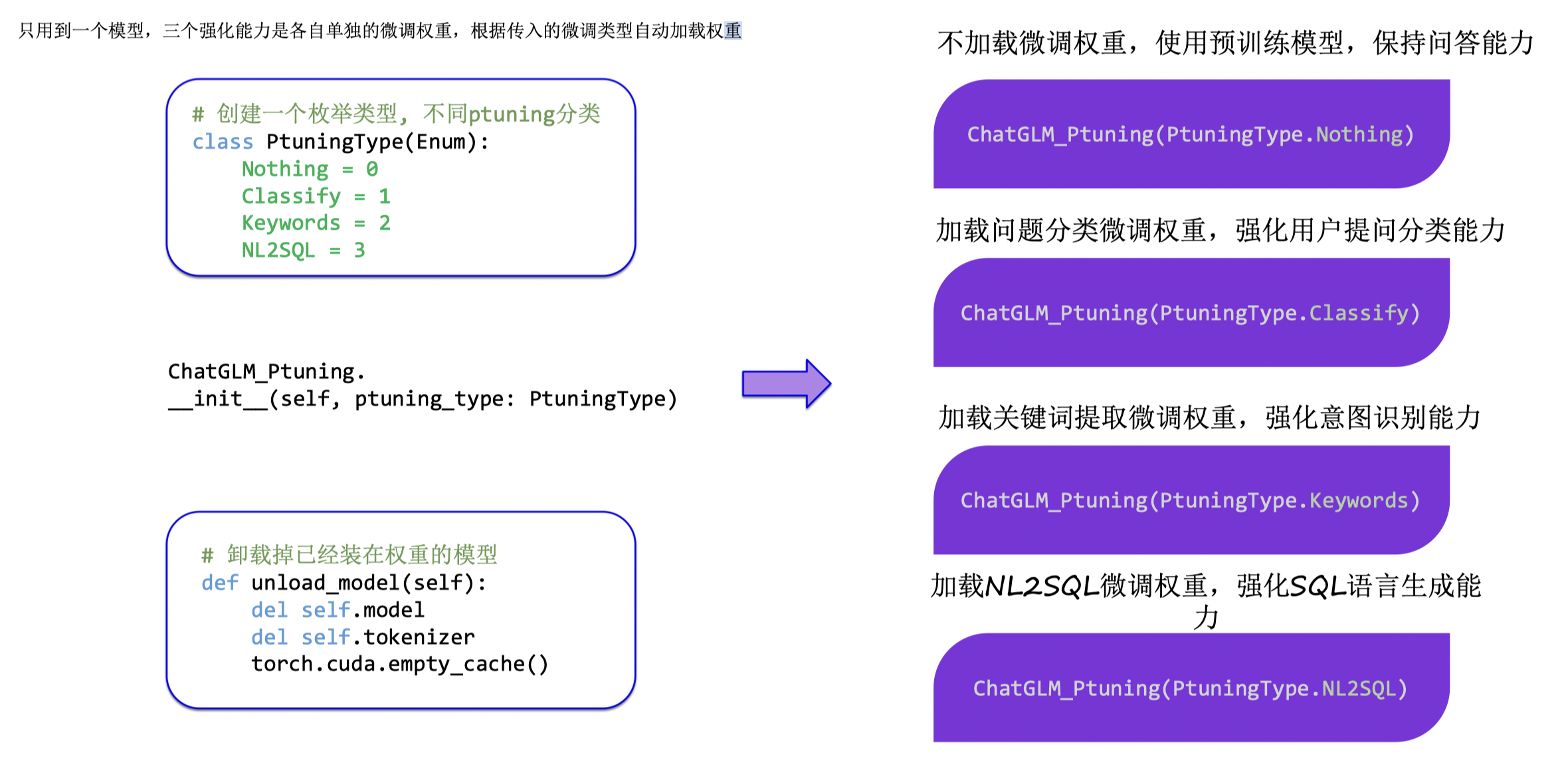
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
|
{"page": 1, "allrow": 0, "type": "text", "inside": ""}
{"page": 1, "allrow": 1, "type": "页眉", "inside": "江苏安靠智能输电工程科技股份有限公司2019年年度报告全文"}
{"page": 1, "allrow": 2, "type": "text", "inside": "江苏安靠智能输电工程科技股份有限公司"}
{"page": 1, "allrow": 3, "type": "text", "inside": "2019年年度报告"}
{"page": 1, "allrow": 4, "type": "text", "inside": "2020-008"}
{"page": 1, "allrow": 5, "type": "text", "inside": "2020年01月"}
{"page": 1, "allrow": 6, "type": "页脚", "inside": "1"}
{"page": 2, "allrow": 7, "type": "text", "inside": ""}
{"page": 2, "allrow": 8, "type": "页眉", "inside": "江苏安靠智能输电工程科技股份有限公司2019年年度报告全文"}
{"page": 2, "allrow": 9, "type": "text", "inside": "第一节重要提示、目录和释义"}
{"page": 2, "allrow": 10, "type": "text", "inside": "公司董事会、监事会及董事、监事、高级管理人员保证年度报告内容的真实、准确、完整,不存在虚假记载、误导性陈述或重大遗漏,并承担个别和连带的法律责任。"}
{"page": 2, "allrow": 11, "type": "text", "inside": "公司负责人陈晓晖、主管会计工作负责人陈晓凌及会计机构负责人(会计主管人员)王春梅声明:保证年度报告中财务报告的真实、准确、完整。"}
{"page": 2, "allrow": 12, "type": "text", "inside": "所有董事均已出席了审议本报告的董事会会议。"}
{"page": 2, "allrow": 13, "type": "text", "inside": "本报告中如有涉及未来的计划、业绩预测等方面内容,均不构成公司对任何投资者及相关人士的承诺,投资者及相关人士应对此保持足够的风险认识,并且应当理解计划、预测与承诺之间的差异。"}
{"page": 2, "allrow": 14, "type": "text", "inside": "本公司敬请广大投资者认真阅读本报告,并注意以下风险:"}
{"page": 2, "allrow": 15, "type": "text", "inside": "1、宏观经济增速放缓带来的行业风险"}
{"page": 2, "allrow": 16, "type": "text", "inside": "当前国内国际宏观经济环境下,增长放缓,需求下降。公司所处行业发展与宏观经济环境及下游行业景气度密切相关。当宏观经济处于上升阶段时,新开工上升,电力需求增加,输配电系统投资增加;反之,当宏观经济处于下降阶段时,供需逆转,电力需求减少,输配电系统投资减少。若宏观经济形势发生变化或产业经济发展方向发生重大调整,导致国家电力网络建设投资规模相应缩减,将对公司所处行业经营环境产生较大的不利影响,导致行业市场容量缩减,对公司业绩造成不利影响。"}
{"page": 2, "allrow": 17, "type": "text", "inside": "2、客户高度集中风险"}
{"page": 2, "allrow": 18, "type": "text", "inside": "公司主要通过参与国家电网、南方电网、五大发电集团、地方政府或下属"}
{"page": 2, "allrow": 19, "type": "页脚", "inside": "2"}
{"page": 3, "allrow": 20, "type": "text", "inside": ""}
{"page": 3, "allrow": 21, "type": "页眉", "inside": "江苏安靠智能输电工程科技股份有限公司2019年年度报告全文"}
{"page": 3, "allrow": 22, "type": "text", "inside": "机构等客户招标的方式进行销售,部分投标采取与电缆厂商合作的方式。而我国发电企业及输配电企业高度集中的格局决定了公司客户集中度较高。鉴于国家电网、南方电网及五大发电集团在产业链中的主导地位以及市场高度集中的格局,如果公司主要客户发生重大变化,可能对公司经营造成不利影响。"}
{"page": 3, "allrow": 23, "type": "text", "inside": "3、市场竞争风险"}
{"page": 3, "allrow": 24, "type": "text", "inside": "随着行业的不断发展,政策及监管环境等可能发生变化,市场竞争方式可能发生改变,公司产品面临的市场竞争环境也将日趋激烈,产品售价存在下降风险。随着客户对高压、超高压产品需求的不断提升,潜在生产厂商可能积极进入,现有生产厂商投资力度可能加大,亦可能取得技术上的实质突破;国外厂商也可能采取降价等手段加剧市场竞争状况。如公司不能维持技术竞争力及价格竞争力等方面的优势,将面临竞争力下降、毛利率降低等风险。"}
{"page": 3, "allrow": 25, "type": "text", "inside": "4、产品质量风险"}
{"page": 3, "allrow": 26, "type": "text", "inside": "公司生产的产品是输配电环节重要的组成部分,若产品发生质量问题,将很有可能对电力输送产生重大影响,造成严重损失。未来,若公司相关产品出现质量问题,可能面临退货、民事赔偿以及行政处罚等不利影响,情形严重的,可能导致公司不再满足国家电网、南方电网或五大发电集团等客户的投标资格,上述情况的发生将会对公司声誉和经营业绩带来不利影响。"}
{"page": 3, "allrow": 27, "type": "text", "inside": "公司经本次董事会审议通过的利润分配预案为:以截至2019年12月31日扣除回购专户上已回购股份(已回购股份2,209,650股)后的总股本97,795,350"}
{"page": 3, "allrow": 28, "type": "text", "inside": "股为基数,向全体股东每10股派发现金红利5元(含税),送红股0股(含税),以资本公积金向全体股东每10股转增3股,共计转增29,338,605股,转增后总股本为129,343,605股(不扣除已回购的股份2,209,650股)。"}
{"page": 3, "allrow": 29, "type": "页脚", "inside": "3"}
{"page": 4, "allrow": 30, "type": "text", "inside": ""}
{"page": 4, "allrow": 31, "type": "页眉", "inside": "江苏安靠智能输电工程科技股份有限公司2019年年度报告全文"}
{"page": 4, "allrow": 32, "type": "text", "inside": "目录"}
{"page": 4, "allrow": 33, "type": "text", "inside": "第一节重要提示、目录和释义.......................................................................................................7"}
{"page": 4, "allrow": 34, "type": "text", "inside": "第二节公司简介和主要财务指标.................................................................................................11"}
{"page": 4, "allrow": 35, "type": "text", "inside": "第三节公司业务概要.....................................................................................................................19"}
{"page": 4, "allrow": 36, "type": "text", "inside": "第四节经营情况讨论与分析.........................................................................................................47"}
{"page": 4, "allrow": 37, "type": "text", "inside": "第五节重要事项...........................................................................................................................130"}
{"page": 4, "allrow": 38, "type": "text", "inside": "第六节股份变动及股东情况.......................................................................................................137"}
{"page": 4, "allrow": 39, "type": "text", "inside": "第七节优先股相关情况...............................................................................................................137"}
{"page": 4, "allrow": 40, "type": "text", "inside": "第八节可转换公司债券相关情况...............................................................................................137"}
{"page": 4, "allrow": 41, "type": "text", "inside": "第九节董事、监事、高级管理人员和员工情况.......................................................................138"}
{"page": 4, "allrow": 42, "type": "text", "inside": "第十节公司治理...........................................................................................................................139"}
{"page": 4, "allrow": 43, "type": "text", "inside": "第十一节公司债券相关情况.......................................................................................................148"}
{"page": 4, "allrow": 44, "type": "text", "inside": "第十二节财务报告.......................................................................................................................156"}
{"page": 4, "allrow": 45, "type": "text", "inside": "第十三节备查文件目录...............................................................................................................157"}
{"page": 4, "allrow": 46, "type": "页脚", "inside": "4"}
{"page": 5, "allrow": 47, "type": "text", "inside": ""}
{"page": 5, "allrow": 48, "type": "页眉", "inside": "江苏安靠智能输电工程科技股份有限公司2019年年度报告全文"}
{"page": 5, "allrow": 49, "type": "text", "inside": "释义"}
{"page": 5, "allrow": 50, "type": "excel", "inside": "['释义项', '指', '释义内容']"}
{"page": 5, "allrow": 51, "type": "excel", "inside": "['一、简称', '指', '']"}
{"page": 5, "allrow": 52, "type": "excel", "inside": "['安靠智电、本公司、公司、发行人', '指', '江苏安靠智能输电工程科技股份有限公司']"}
{"page": 5, "allrow": 53, "type": "excel", "inside": "['河南安靠', '指', '河南安靠电力工程设计有限公司']"}
{"page": 5, "allrow": 54, "type": "excel", "inside": "['溧阳常瑞', '指', '溧阳市常瑞电力科技有限公司']"}
{"page": 5, "allrow": 55, "type": "excel", "inside": "['江苏凌瑞', '指', '江苏凌瑞电力科技有限公司']"}
{"page": 5, "allrow": 56, "type": "excel", "inside": "['安靠创投', '指', '江苏安靠创业投资有限公司']"}
{"page": 5, "allrow": 57, "type": "excel", "inside": "['安云创投', '指', '江苏安云创业投资有限公司']"}
{"page": 5, "allrow": 58, "type": "excel", "inside": "['安靠有限', '指', '江苏安靠超高压电缆附件有限公司']"}
{"page": 5, "allrow": 59, "type": "excel", "inside": "['安靠光热', '指', '江苏安靠光热发电系统科技有限公司']"}
{"page": 5, "allrow": 60, "type": "excel", "inside": "['ABB', '指', 'ABB(中国)有限公司']"}
{"page": 5, "allrow": 61, "type": "excel", "inside": "['3M', '指', '明尼苏达矿务及制造业公司']"}
{"page": 5, "allrow": 62, "type": "excel", "inside": "['建创能鑫', '指', '建创能鑫(天津)创业投资有限责任公司']"}
{"page": 5, "allrow": 63, "type": "excel", "inside": "['曲水增益、卓辉增益', '指', '曲水卓辉增益投资管理中心(有限合伙)']"}
{"page": 5, "allrow": 64, "type": "excel", "inside": "['国家电网', '指', '国家电网有限公司']"}
{"page": 5, "allrow": 65, "type": "excel", "inside": "['南方电网', '指', '中国南方电网有限责任公司']"}
{"page": 5, "allrow": 66, "type": "excel", "inside": "['', '', '中国华能集团公司、中国大唐集团公司、中国华电集团公司、中国']"}
{"page": 5, "allrow": 67, "type": "excel", "inside": "['五大发电集团', '指', '国电集团公司、国家电力投资集团公司']"}
{"page": 5, "allrow": 68, "type": "excel", "inside": "['中国证监会、证监会', '指', '中国证券监督管理委员会']"}
{"page": 5, "allrow": 69, "type": "excel", "inside": "['深交所', '指', '深圳证券交易所']"}
{"page": 5, "allrow": 70, "type": "excel", "inside": "['公司法', '指', '中华人民共和国公司法']"}
{"page": 5, "allrow": 71, "type": "excel", "inside": "['证券法', '指', '中华人民共和国证券法']"}
{"page": 5, "allrow": 72, "type": "excel", "inside": "['股东大会', '指', '江苏安靠智能输电工程科技股份有限公司股东大会']"}
{"page": 5, "allrow": 73, "type": "excel", "inside": "['董事会', '指', '江苏安靠智能输电工程科技股份有限公司董事会']"}
{"page": 5, "allrow": 74, "type": "excel", "inside": "['监事会', '指', '江苏安靠智能输电工程科技股份有限公司监事会']"}
{"page": 5, "allrow": 75, "type": "excel", "inside": "['公司章程', '指', '江苏安靠智能输电工程科技股份有限公司章程']"}
{"page": 5, "allrow": 76, "type": "excel", "inside": "['报告期', '指', '2019年1月1日至2019年12月31日']"}
{"page": 5, "allrow": 77, "type": "text", "inside": ""}
...
|