TensorRT简介
- TensorRT是用于高效实现已经训练好的深度学习模型的推理过程的SDK。
- TensorRT内含
推理优化器和运行时环境。
- TensorRT使Deep Learning模型能以更高的吞吐量和更低的延迟运行。
- 包含C++和python的API,完全等价可以混用。
一些reference:
TensorRT文档:https://docs.nvidia.com/deeplearning/tensorrt/quick-start-guide/index.html
C++ API文档:https://docs.nvidia.com/deeplearning/tensorrt/api/c_api/index.html
python API文档:https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/index.html
TensorRT下载:https://developer.nvidia.com/nvidia-tensorrt-download
该教程配套代码:https://github.com/NVIDIA/trt-samples-for-hackathon-cn/tree/master/cookbook
TensorRT基本特性
TensorRT的基本流程
示例代码
基本流程:
- 构建期:
- 建立Buider(构建引擎器)
- 创建Network(计算图内容)
- 生成SerializedNetwork(网络的TRT内部表示)
- 运行期:
- 建立Engine和Context
- Buffer相关准备(Host端 + Device端 + 拷贝操作)
- 执行推理(Execute)
TensorRT工作流
- 使用框架自带的TRT接口(TF-TRT、Torch-TensorRT)
- 使用Parser(TF/Torch/… -> ONNX -> TensorRT)
- 流程成熟,ONNX通用性好,方便网络调整,兼顾性能效率
- 使用TensorRT原生API搭建网络
使用TensorRT API搭建
下面是一个API完整搭建一个MNIST手写识别模型的示例:
示例代码
由于我没有学过Tensorflow,我也不会使用该框架去实现,未来应该只选择Parser的方式实现,这里只做了解。
基本流程:
- 1.Tensorflow中创建并训练一个网络
- 2.提取网络权重,保存为para.npz
- 3.TensorRT中重建该网络并加载para.npz的权重
- 4.生成推理引擎
- 5.用引擎做实际推理
用一张图来表示TensorRT使用的通用流程:
 其中黄色部分文字是API创建方式特有的步骤,Parse将用onnx来代替。
其中黄色部分文字是API创建方式特有的步骤,Parse将用onnx来代替。
构建阶段介绍
1
2
3
|
# 可选参数:VERBOSE,INFO,WARNING,ERROR,INTERNAL_ERROR,
# 产生不同等级的日志 ,由详细到简略。
logger = trt.Logger(trt.Logger.VERBOSE)
|
1
2
3
4
|
# 常用成员:Builder.max_batch_size = 256 (不推荐使用将被废弃)
# Dynamic Shape模式必须使用 builderConfig及相关的API
# 官方说builder只作为引擎构建的入口,相应的成员属性将会通过builderConfig进行设置
builder = trt.Builder(logger)
|
1
2
3
4
5
|
config = builder.create_builder_config()
# 常用成员
config.max_workspace_size = 1 < 30 # 指定构建期可用显存
config.flag = ... # 设置标志位,如1 << int(trt.BuilderFlag.FP16)...
config.int8_calibrator = ... # 指定calibrator
|
注意Dynamic Shape模型下使用builder.max_workspace_size可能会报错。
1
2
3
4
5
6
7
8
9
10
|
network = builder.create_network()
# 常用参数
1 << int(tensorrt.NetworkDefinationCreationFlag.EXPLICT_BATCH) # 使用Explicit Batch模式
# 常用方法
network.add_input('oneTensor', trt.float32, (3,4,5)) # 标记网络输入张量
convLayer = network.add_convolution_nd(XXX) # 添加各种网络层
network.mark_output(convLayer.get_output(0)) # 标记网络输出张量
# 常用获取网络信息的成员
network.name/network.num_layers/network.num_inputs/network.num_outputs
network.has_implicit_batch_dimension/network.has_explicit_precision
|
TensorRT主流Network模式采用Explicit Batch模式,即所有张量都显式包含Batch维度,从onnx导入的模型也默认使用Explicit Batch模式。
- Dynamic Shape模式
- 适用于输入张量形状在推理时才决定的网络。(也就是支持多个分辨率输入且性能差异较小的网络)
- 除了Batch维,其他维度也可以推理时才决定
- 需要
Explicit Batch模式
- 需要
Optimazation Profile帮助网络优化
- 需要
context.set_binding_shape绑定实际输入数据形状
- Profile指定输入张量大小范围
1
2
3
4
|
profile = builder.create_optimization_profile()
# 常用方法
profile.set_shape(tensorName, minShape, commonShape, maxShape) # 给定输入张量的最小、最常见 、最大尺寸
config.add_optimization_profile(profile) # 将设置的profile传递给config以创建网络
|
- 使用TensorRT API搭建(API方式独有的部分)
如果使用
onnx格式搭建该部分可以省略!
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 注意区别Layer和Tensor
oneLayer = network.add_identity(inputTensor) # 输出是一个层
oneTensor = oneLayer.get_output(0) # 从层中推理得到张量
nextLayer = network.add_identity(oneTensor) # 将张量放入下一个layer
# Layer的常用成员和方法
oneLayer.name = 'one' # 获取或者指定Layer的名字
oneLayer.type # 获取该层的种类
oneLayer.precison # 指定该层计算精度(需配合builder.strict_type_constraints)
oneLayer.get_output(i) # 获取活该层的第i个输出张量
# Tensor常用成员和方法
oneTensor.name = 'one' # 获取或指定tensor的名字
oneTensor.shape # 获取tensor的形状,可用于print检查或作为后续层的参数
oneTensor.dtype # 获取或设定tensor的数据类型
|
- 从network中打印所有层和张量的信息
- 外层循环遍历所有layer
- 内层循环遍历该Layer的所有input/output
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
for i in range(network.layers):
layer = network.get_layer(i)
print(i, "%s,in=%d,out=%d,%s"%(str(layer.type)[10:], layer.num_inputs, layer.num_outputs, layer.name))
for j in range(layer.nun_inputs):
tensor = layer.get_input(j)
if tensor == None:
print("\tInput %2d:"%j, "None")
else:
print("\tInput %2d:%s,%s,%s"%(j, tensor.shape, str(tensor.dtype)[9:], tensor.name))
for j in range(layer.num_outputs):
tensor = layer.get_output(j)
if tensor == None:
print("\tOutput %2d:"%j, "None")
else:
print("\tOutput %2d:%s,%s,%s"%(j, tensor.shape, str(tensor.dtype)[9:], tensor.name))
|
FP16:部分层可能精度下降导致较大的误差,找到误差较大的层,强制该层使用FP32进行计算
1
2
|
config.flags = 1 << int(trt.BuilderFlag.STRICT_TYPES)
layer.precision = trt.float32
|
Int8模式(PTQ):需要有校准集(输入范例数据),自己实现calibrator
1
2
|
config.flags = 1 << int(trt.BuilderFlag.INT8)
config.int8_calibrater = ...
|
Int8模式(QAT)
1
|
config.flags = 1 << int(trt.BuilderFlag.INT8)
|
需要在Pytorch网络中插入Quantize/Dequantize层
TensorRT运行期(Runtime)
1
|
serializedNetwork = builder.build_serialized_network(network, config)
|
1
|
engine = trt.Runtime(logger).deserialize_cuda_engine(serializedNetwork)
|
1
|
context = engine.create_execution_context()
|
- 绑定输入输出(Dynamic Shape模式必须)
1
|
context.set_binding_shape(0, [1, 1, 28, 28])
|
1
2
3
4
|
inputHost = np.ascontiguousarray(inputData.reshape(-1))
outputHost = np.empty(context.get_binding_shape(1), trt.ntype(engine.get_binding_dtype(1)))
inputDevice = cudart.cudaMalloc(inputHost.nbytes)[1]
outputDevice = cudart.cudaMalloc(outputHost.nbytes)[1]
|
1
2
3
|
cudart.cudaMemcpy(inputDevice, inputHost.ctypes.data, inputHost.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice)
context.execute_v2([int(inputDevice), int(outputDevice)])
cudart.cudaMemcpy(outputHost.ctypes.data, outputDevice, outputHost.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost)
|
Engine计算引擎的生成
1
2
3
4
5
6
7
8
9
10
11
|
serializedNetwork = builder.build_serialized_network(network, config)
engine = trt.Runtime(logger).deserialize_cuda_engine(serializedNetwork)
# 常用成员:
engine.num_bindings # 获取engine绑定的输入输出张量总数,n+m
engine.max_batch_size # 获取engine的最大batch size,Explicit Batch模式下为1
engine.num_layer # 获取engine(自动优化后)总层数
# 常用方法
engine.get_binding_dtype(i) # 第i个绑定张量的数据类型,0~n-1为输入张量,n~n+m-1为输出张量
engine.get_binding_shape(i) # 第i个绑定张量的张量形状,Dynamic Shape模式下可能结果含-1
engine.binding_is_input(i) # 第i个绑定张量是否为输入张量
engine.get_binding_index('n') # 名字叫'n'的张量在engine中的绑定索引
|
- 什么是Binding?
- engine/context给所有输入输出张量安排了位置
- 总共有engine.num_bindings个binding,输入张量排在最前,输出张量排在最后。(如图,假设模型输入为x、y,输出两个张量index和entropy)
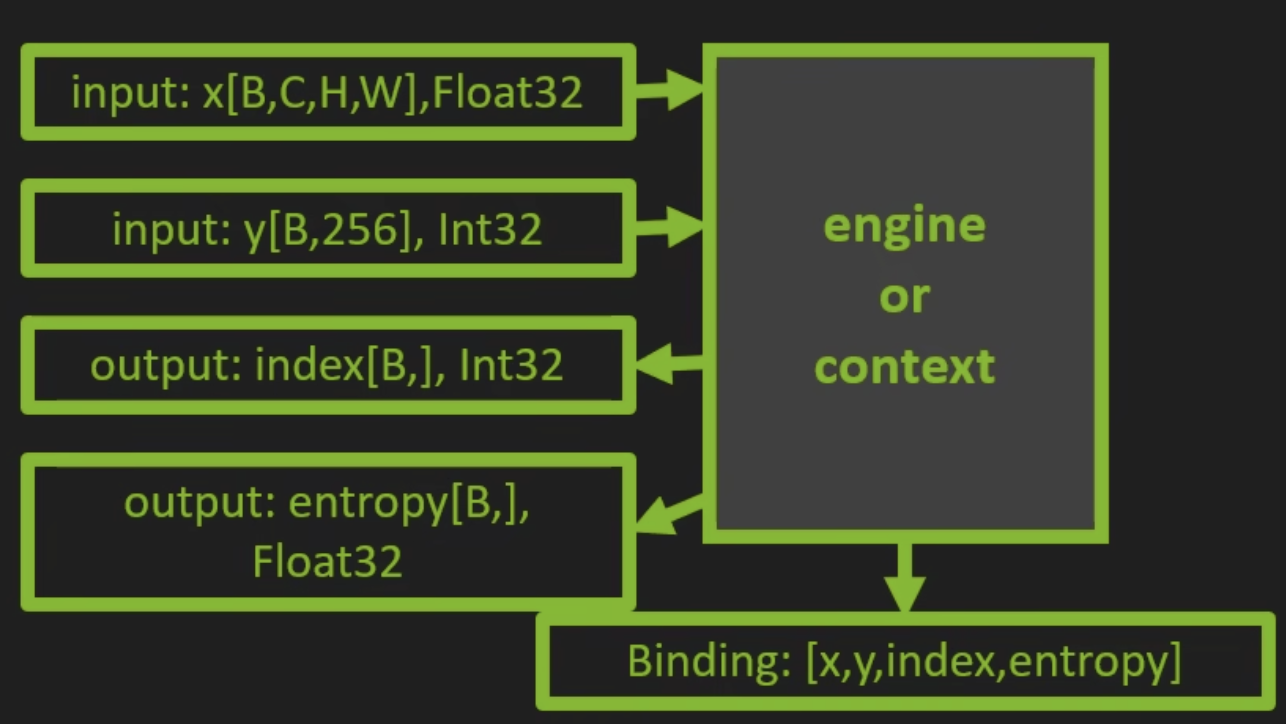
- 运行期绑定张量形状是,要按指定位置绑定
1
2
3
|
context.set_binding_shape(0, [4, 1, 28, 28])
context.set_binding_shape(1, [4, 256])
# 此时输出张量形状会自动计算,从(-1,)和(-1,)变成(4,)和(4,)
|
- 多Profile功能中Binding规则会变复杂一些
- Context推理进程
1
2
3
4
5
6
7
8
|
context = engine.create_execution_context()
# 常用成员
context.all_binding_shapes_specified # 确认所有绑定的输入输出张量形状均被指定
# 常用方法:
context.set_binding_shape(i, shapeOfInputTensor) # 设定第i个绑定张量的形状(Dynamic Shape中使用)
context.get_binding_shape(i) # 获取第i个绑定张量的形状
context.execute_v2(listOfBuffer) # Explicit batch模式的同步执行
context.execute_async_v2(listOfBuffer, srteam) # Explicit batch模式的异步执行
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 内存和显存的申请
inputHost = np.ascontiguousarray(inputData.reshape(-1))
outputHost = np.empty(context.get_binding_shape(1), trt.ntype(engine.get_binding_dtype(1)))
inputDevice = cudart.cudaMalloc(inputHost.nbytes)[1]
outputDevice = cudart.cudaMalloc(outputHost.nbytes)[1]
# 内存和显存之间的拷贝
cudart.cudaMemcpy(inputDevice, inputHost.ctypes.data, inputHost.nbytes, cudart.cudaMemcpyKind.cudaMemcpyHostToDevice)
context.execute_v2([int(inputDevice), int(outputDevice)])
cudart.cudaMemcpy(outputHost.ctypes.data, outputDevice, outputHost.nbytes, cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost)
# 推理完成后释放显存
cudart.cudaFree(inputDevice)
cudart.cudaFree(outputDevice)
|
高级话题:利用CUDA stream 将buffer申请、拷贝做成异步操作。(教程第4部分)
- 序列化和反序列化
-
将SerializedNetwork保存为文件,下次跳过构建直接使用
-
注意环境统一(硬件环境 + CUDA/cuDNN/TensorRT环境)
- Engine包含硬件优化,不能跨平台使用
- 不同版本TensorRT生成的engine不能相互兼容
- 同平台同环境多次生成的engine可能不同
-
TensorRT runtime版本与engine版本不同时会出现如下报错信息:
[TensorRT]ERROR:INVALID_CONFIG:The engine plan file is not compatible with this version of TensorRT, expecting library version 7.2.3 got 7.2.2,please rebuild.
[TesnorRT]ERROR:engine.cpp(1646) - Serialization Error in deserialize:0(Core engine deserialization failure)
-
高级话题:利用AlgrothimSelector或TimingCache多次生成一模一样的engine。(教程第4部分)
使用Parser(是我们学习的重点)
- ONNX
- 针对机器学习所设计的开放式的文件格式
- 用于存储训练好的模型,使得不同框架可以采用相同格式存储模型数据并交互
- Pytorch/TensorFlow转TensorRT的中间表示
- 当前TensorRT导入模型的主要途径
- Onnxruntime
- 利用onnx格式尽心推理计算的框架
- 兼容多硬件、多操作系统,支持多深度学习框架
- 可用于检查TensorFLow/Torch模型导出到onnx的正确性
工作流程如下:
Pytorch转ONNX转TensorRT范例代码
-
基本流程:
- PyTorch中创建网络并保存为
.pt或者.pth文件
- 使用PyTorch内部API讲
.pt或者.pth转化为.onnx
- TensorRT中读取
.onnx构建engine并作推理
-
示例代码在TensorRT中开启了Int8模式
- 需要自己实现calibrator类(calibrator.py可作为Int8通用样例)
TensorFlow转ONNX转TensorRT范例代码
最后修改于 2023-05-17

本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。