大模型高效微调技术(PEFT)
Adapter Tuning
技术原理
论文:Parameter-Efficient Transfer Learning for NLP 论文链接:http://proceedings.mlr.press/v97/houlsby19a/houlsby19a.pdf
该方法设计了一个Adapter结构,嵌入Transformer结构中。针对一个Transformer Block,增加两个Adapter结构,增加都放在残差结构之前。训练时,固定住原来的预训练模型参数不变,只对Adapter结构和Layer Normal层进行微调。Adapter层是一个类似于Squeeze-and-Excitation层思想的结构,首先使用较高维度的特征投影到较低维度的特征,中间通过一个非线性层,再将低维特征重新映射回原来的高维特征。其参数量主要低维特征的维度决定。

方法效果
对$BERT_{LARGE}$在各个任务上进行全量微调和Adapter-Tuning的结果如下,在不同的任务上,低维特征的维度m不同时效果不同。将m固定在64时,性能会略微下降。
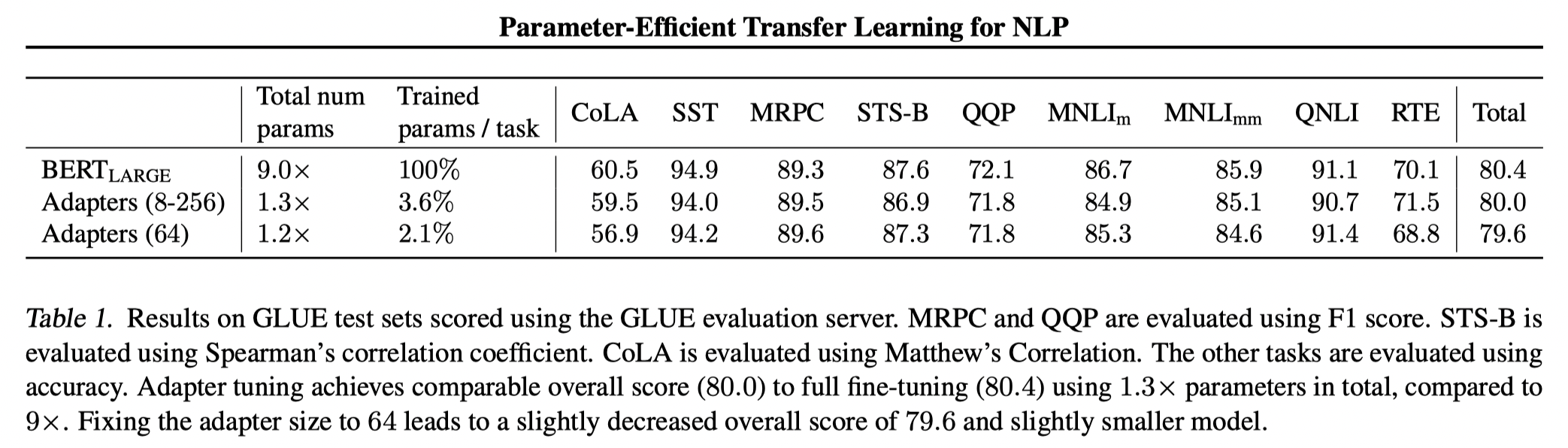
Adapter通过引入额外的0.5%~5%参数可以媲美全量微调的效果,缺点是引入的参数在Transformer Block内部,在面对不同的任务时,需要保存不同的权重副本。
Adapter Fusion
技术原理
论文:AdapterFusion: Non-Destructive Task Composition for Transfer Learning
论文链接:https://arxiv.org/pdf/2005.00247.pdf
整合多个任务的知识,传统的两个方法是按一定顺序微调(Sequential fine-tuning)或者多任务学习(multi-task learning)。前者的问题是灾难性遗忘,后者的问题是不同的任务会相互影响,也难以平衡数据集差距很大的任务,对于新添加任务,需要进行完整的联合训练,这对于大成本的任务是不可取的。
作者在Adapter Tuning的启发下,考虑将多个任务的Adapter参数结合起来。作者提出了Adapter Fusion,这是一种两阶段学习方法,可以同时结合多个任务的知识。第一阶段知识提取,学习适配器的特定参数,这些参数封装了特定任务的信息;第二阶段知识组合,将所有的任务信息进行组合;按照这两步走,可以学习到多个任务中的表示,并且是非破坏性的。
Adapter Fusion根据了Adapter Tuning的优点和局限性,提出了两步训练的方法。
- 第一步:该步骤有两种方法,第一种是对每个任务进行单独微调,各个任务之间互不干扰;第二种方法是对所有任务进行多任务学习,联合优化。
- 第二步:为了避免特定任务接入的灾难性遗忘的问题。Adapter Fusion联合了第一个阶段的N个Adapter信息,新引入AdapterFusion结构的参数,目标函数也是学习针对特定任务m的AdapterFusion的参数。

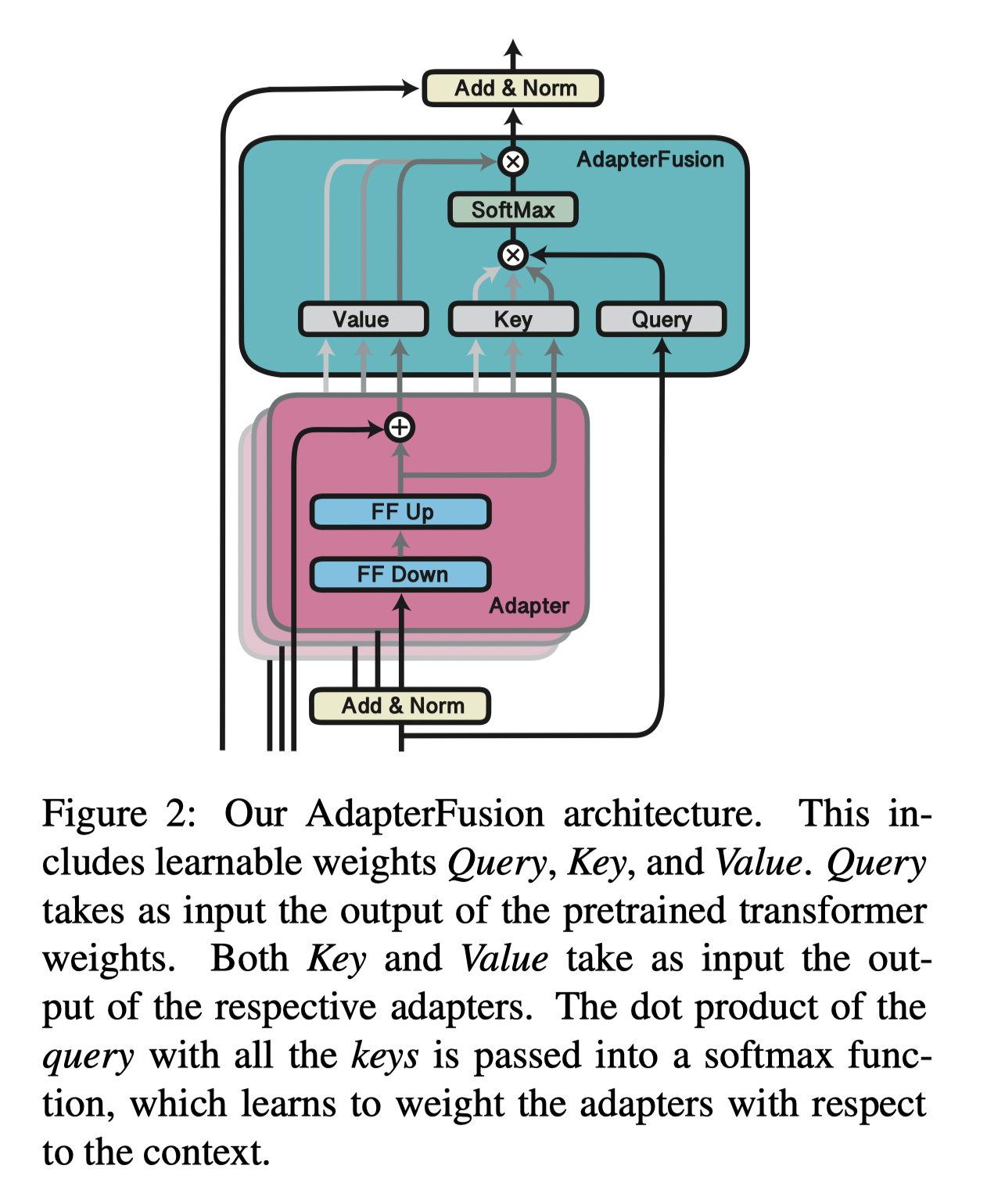
AdapterFusion的结构:
AdapterFusion具体结构就是一个Attention,它的参数包括query,key, value的矩阵参数,在transformer的每一层都存在,它的query是transformer每个子模块的输出结果,它的key跟value则是N个任务的adapter的输出。通过AdapterFusion,模型可以为不同的任务对应的adapter分配不同的权重,聚合N个任务的信息,从而为特定任务输出更合适的结果。
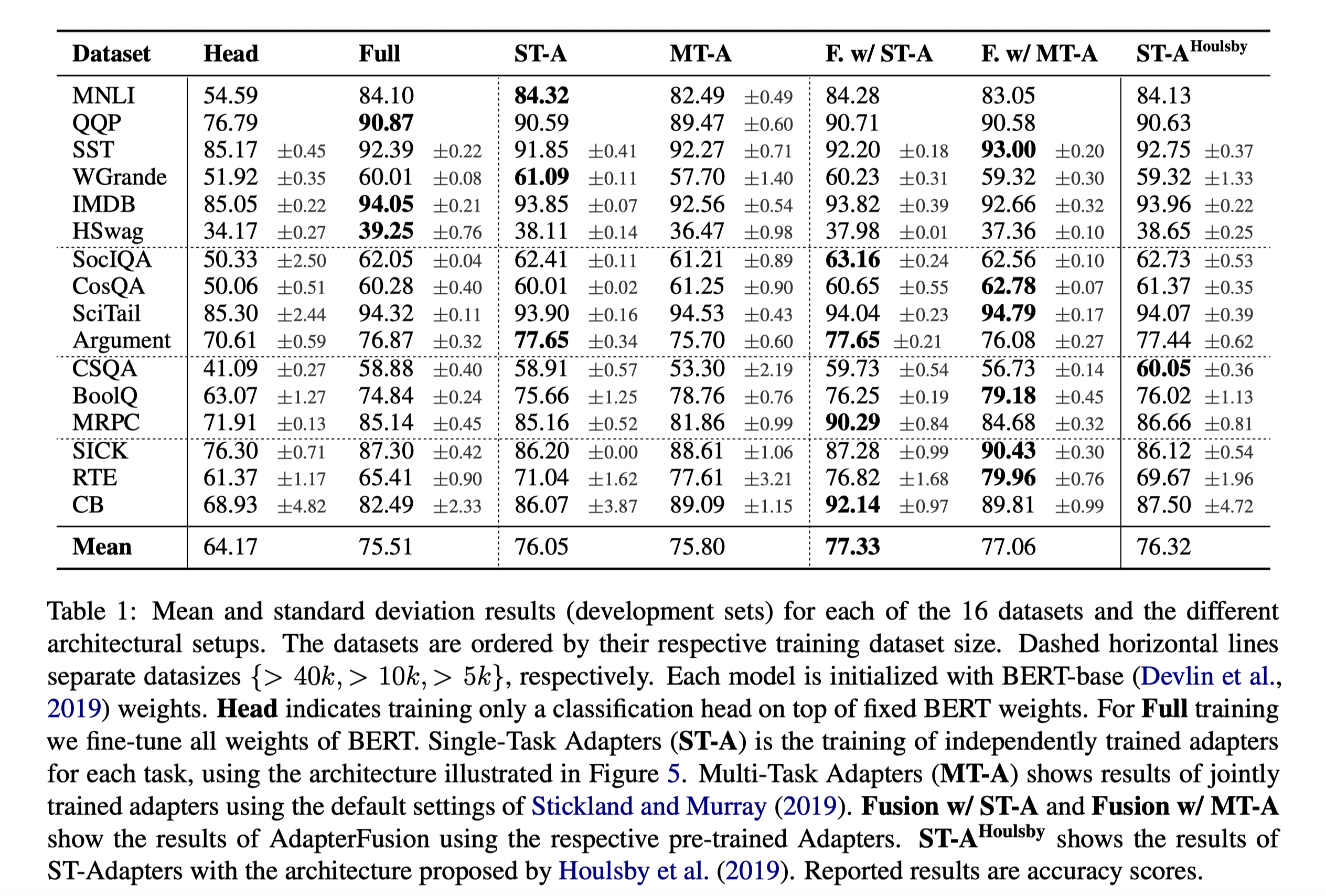
方法效果
ST-A:单任务Adapter Tuning
MT-A:多任务Adapter Tuning 联合调优
F.w/ST-A:第一阶段使用ST-A,第二阶段使用AdapterFusion
F.w/MT-A:第一阶段使用MT-A,第二阶段使用AdapterFusion
可以看到,在第一阶段的只微调分类头的部分,效果并不好,ST-A微调大多数任务都能达到全量微调的水准,而MT-A在进行联合微调的时候发生了明显的任务不平衡的问题,这说明MT-A虽然可以学习到一个通用的表征,但是由于不同任务的差异性,很难保证在所有任务上都取得最优的效果。F.w/ST-A是最有效的方法,在多个数据集上的平均效果达到了最佳。而F.w/MT-A在于第一阶段其实已经联合了多个任务的信息了,所以AdapterFusion的作用没有那么明显,同时MT-A这种多任务联合训练的方式需要投入较多的成本,并不算一种高效的参数更新方式。
Adapter Drop
技术原理
论文:AdapterDrop: On the Efficiency of Adapters in Transformers
论文链接:https://arxiv.org/pdf/2010.11918.pdf
作者通过对Adapter的计算效率进行分析,发现与全量微调相比,Adapter在训练时快60%,但是在推理时慢4%-6%。
基于此,作者提出了AdapterDrop方法缓解该问题。
Adapter Drop 在不影响任务性能的情况下,对Adapter层进行动态删除,尽可能减少模型的参数量,提高模型在训练和特别是推理时的效率。
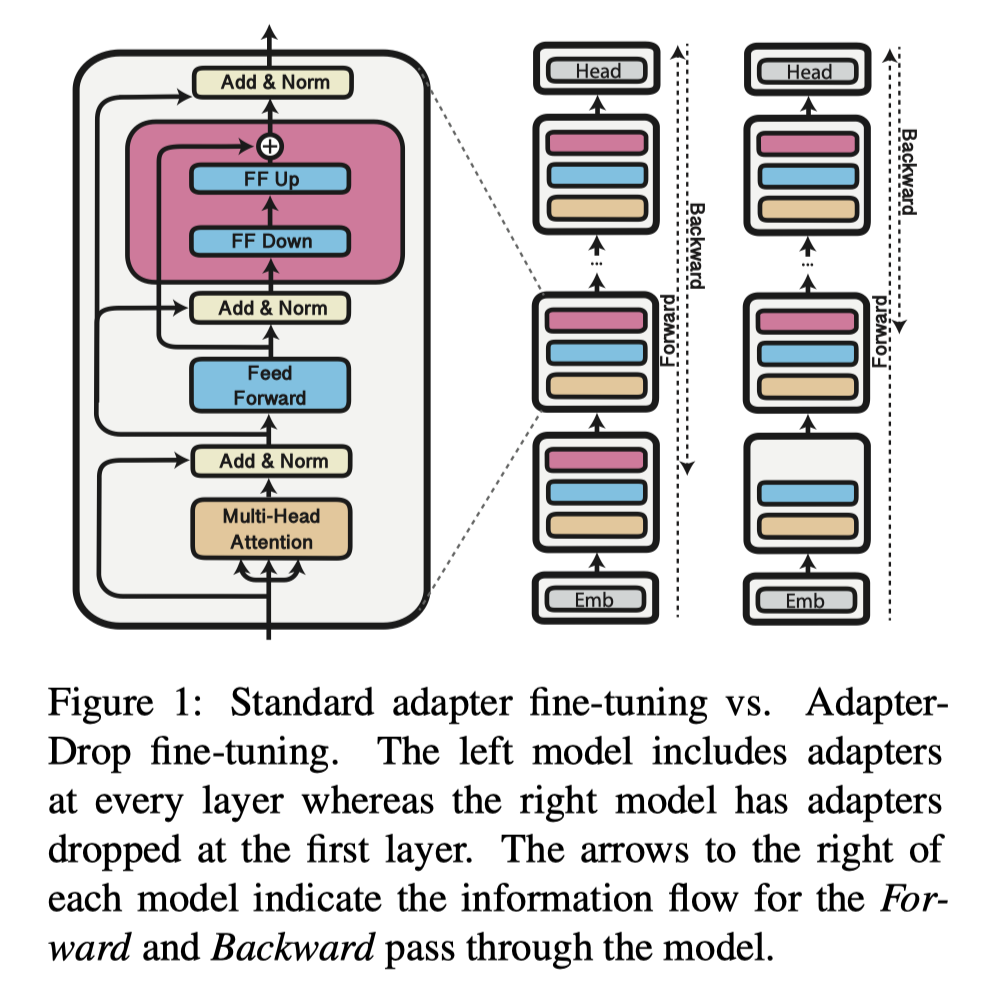
实验表明,从较低的 Transformer 层中删除Adapter可以显着提高多任务设置中的推理速度。 例如,将前五个Transformer层中的Adapter丢弃,在对 8 个任务进行推理时,速度提高了 39%。并且即使有多个丢弃层,AdapterDrop 也能保持良好的结果。
除此之外,作者还研究了Adapter Fusion中的Adapter进行剪枝后的效果。

通过实验表明可以移除 AdapterFusion 中的大多数Adapter而不影响任务性能。使用剩余的两个Adapter,实现了与具有八个Adapter的完整 AdapterFusion 模型相当的结果,并将推理速度提高了 68%。
作者建议在实际部署这些模型之前执行 AdaperFusion 剪枝。 这是一种简单而有效的技术,即使在完全保持性能的情况下也能实现效率提升。
总之,AdapterDrop 通过从较低的 Transformer 层删除可变数量的Adaper来提升推理速度。 当对多个任务执行推理时,动态地减少了运行时的计算开销,并在很大程度上保持了任务性能。
方法效果
BitFit
技术原理
论文:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
论文链接:https://arxiv.org/pdf/2106.10199.pdf
Bitfit是一种稀疏微调的方法,它冻结了大部分transformer-encoder参数,只更新bias参数跟特定任务的分类层参数。涉及到的bias参数有attention模块中计算query,key,value跟合并多个attention结果时涉及到的bias,MLP层中的bias,Layernormalization层的bias参数。方法的技术原理非常简单,且需要微调的参数量极小。
方法效果
使用$BERT_{LARGE}$进行全量微调,以及一些对比的高效微调方法,在不同的任务数据集上进行了实验。可以看到仅微调bias的Bitfit方法也能达到略低于3.6%参数的Adapter和使用0.5%参数的Diff-Prune方法的水平,而需要微调的参数量只有0.08%。
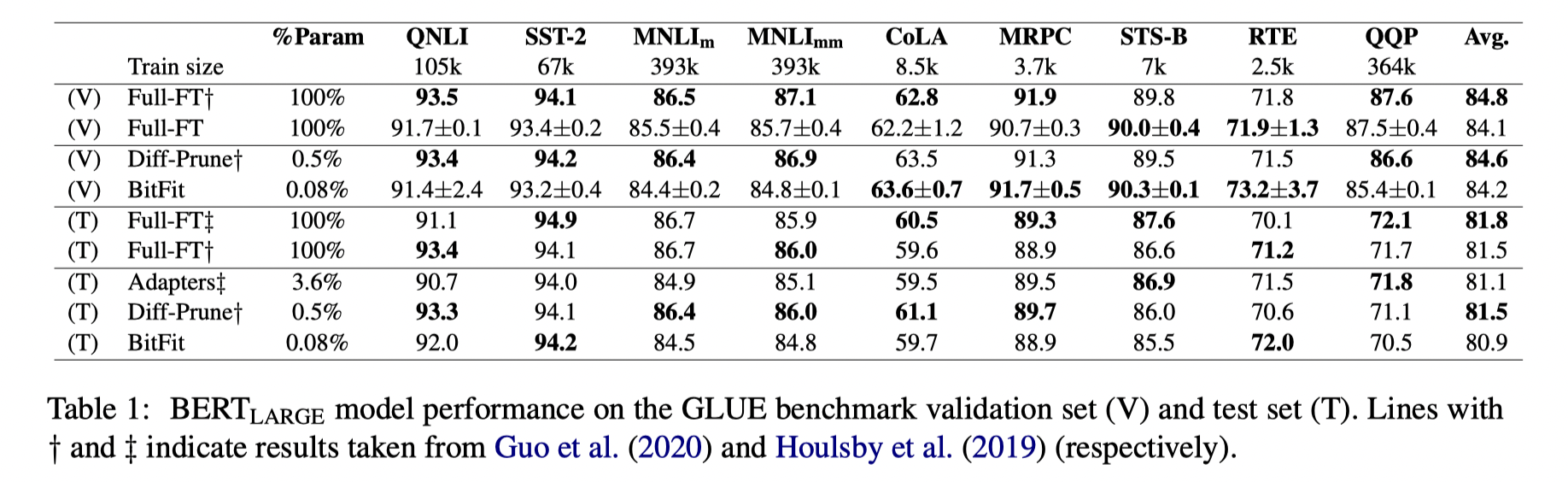
而且通过消融实验也可以看出,bias参数的变化并不是在所有结构的部分都比较大。从结果来看,计算query和FFN层的bias参数变化最为明显,只更新这一部分参数也能达到较为不错的效果。
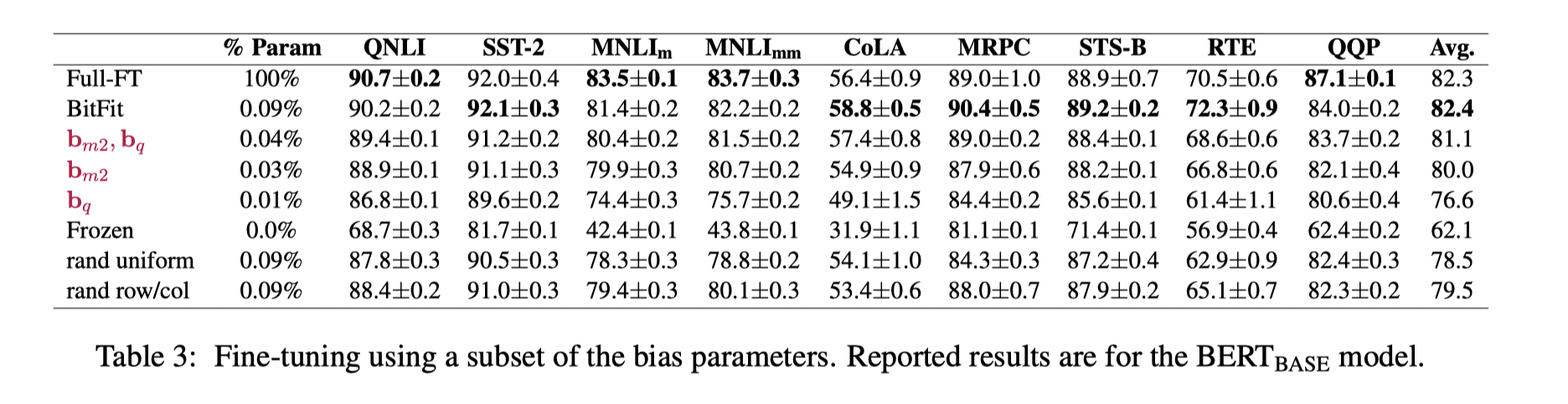
Bitfit只引入了0.03%~0.09%的参数,达到了较好的微调效果,其参数量比其他model tuning的方法少了将近10倍,缺点是更新bias参数依旧需要根据不同的任务保存不同模型的副本。
Prefix Tuning
技术原理
论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation
论文链接:https://arxiv.org/pdf/2101.00190.pdf
Prefix Tuning是一种优化前缀提示的微调方法。与前文对模型参数的微调不同,前缀微调的方法对原本预训练的模型没有任何改动(前缀部分参数不会包含在模型里,但依旧算是模型的部分权重,只不过与原模型分离),其目标是通过微调输入的向量参数来改变模型的生成行为。前缀被添加到输入文本的开头,并且通过调整前缀的内容和长度,可以引导模型生成符合用户意图的输出。但是直接更新前缀表示通常会对模型产生较大的负面影响,所以该方法优化了输入向量参数,即前缀的表示,以控制模型的生成结果。
正如下图表示,对于原有的Transformer预训练模型不需要进行改动,而是针对不同的任务训练不同的前缀提示。
为了实现这个目标,文中使用了多层感知机(MLP)来将前缀与模型输入进行连接。通过训练MLP的参数,可以将前缀映射到与模型输入相同的维度,并且学习前缀和输入之间的复杂映射关系。这样还解决了前缀的长度可能与模型预期的输入长度不匹配的问题,通过使用MLP可以将前缀映射到与模型输入相同的维度。

Prefix Tuning与构造Prompt比较相似,构造Prompt是人为的,较不稳定,不同的Prompt可能会产生极大的差异。而Prefix可以视为隐藏式的Prompt,且该Prompt是可以训练的!
方法效果
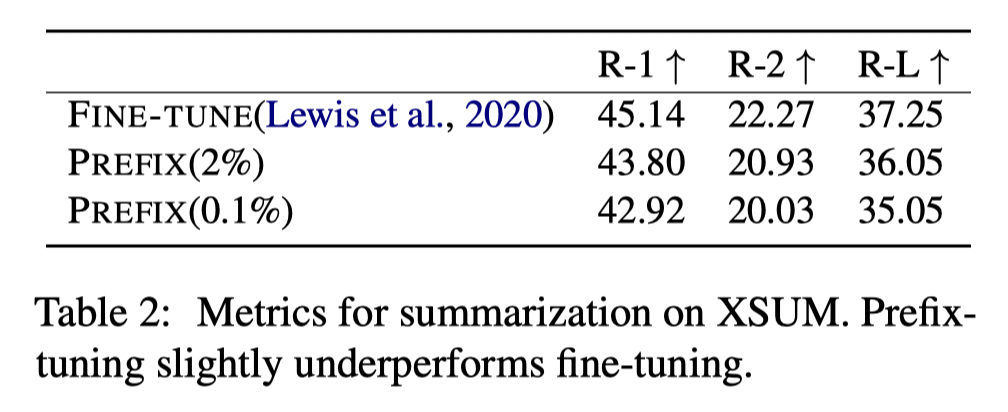
使用$GPT-2_{MEDIUM}$和$GPT-2_{LARGE}$作为基础模型进行全量微调和一些常用的高效微调方法,在不同任务上都进行了实验。可以看到在很多任务上的微调效果都很不错,引入额外的参数为0.1%,该部分参数不在模型内部。

通过消融实验证明,在部分实验上仅仅对Embedding层添加前缀表现力不够,性能将会远不如Full Fine-Tuning,因此在每个Layer都增加了一个可训练的提示前缀,尽量逼近全量微调的效果,参数量上涨为2%。
论文还对不同的前缀提示长度做了消融研究,发现提示的长度越长,MLP进行转化的效果越好,当然这种增长并不是线性的,随着前缀变长,增长的幅度会越来越小。
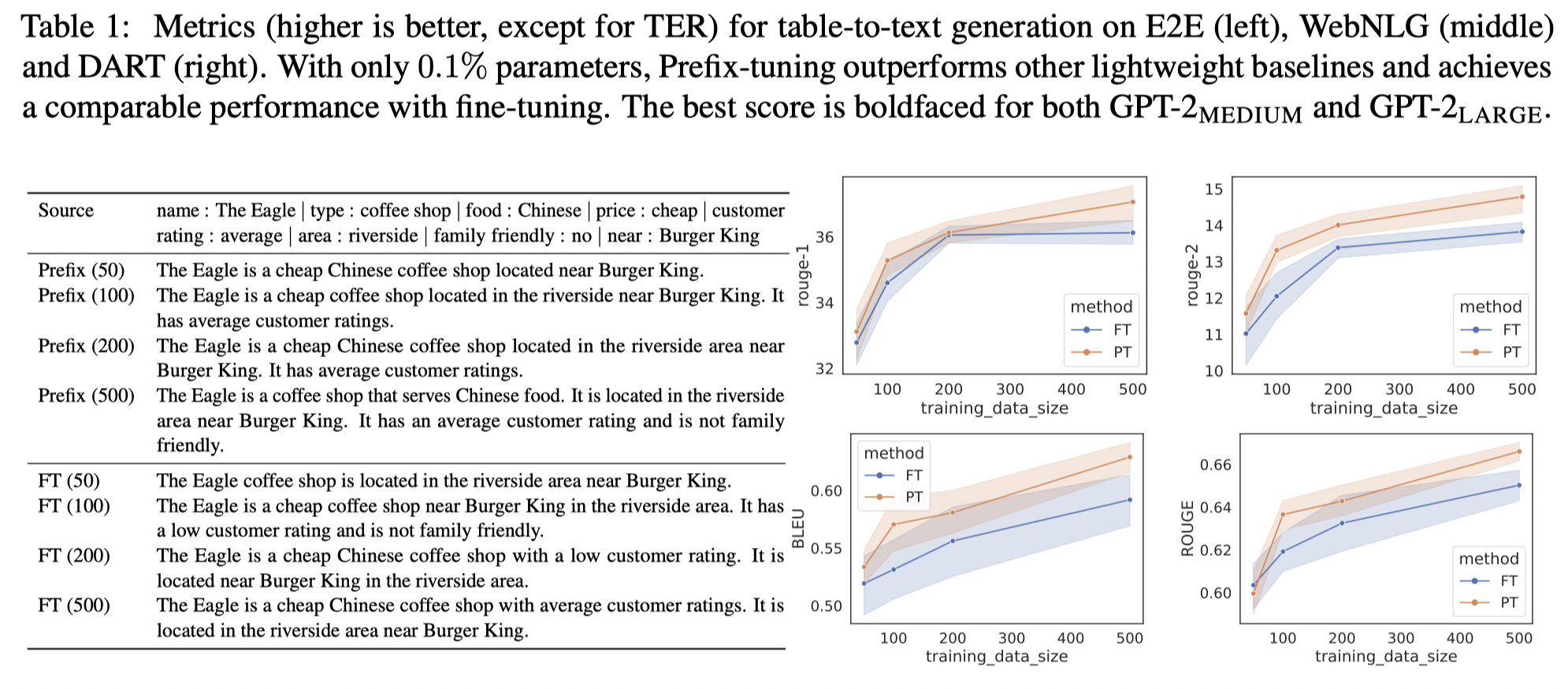
Prefix Tuning通过引入可训练的前缀参数和转化的MLP参数达到全量微调的效果,对原来的预训练参数没有任何改变。严格来说,它还是属于模型调优的范畴,只是这种方法不需要对不同的任务保存模型权重副本,只需要保存不同任务前缀提示和MLP转化的参数。
Prompt Tuning
技术原理
论文:The Power of Scale for Parameter-Efficient Prompt Tuning
论文链接:https://arxiv.org/pdf/2104.08691.pdf
Prompt Tuning可以视为Prefix Tuning的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,只在输入层加入prompt tokens,并且不需要加入MLP来调整难以训练的问题。Prompt Tuning可以实现多任务混合推理,因为在模型层面并没有发生任何改变,相当于只需要根据令牌提示来指定我们想要完成的任务。与Prefix Tuning最大的不同是它对模型层面完全没有改变,即时调优(没有中间层前缀或特定任务的输出层)就足以与模型调优竞争。

方法效果
与全量微调,以及模型高效调优相比,在参数量较低的情况下,Prompt Tuning的方法不如它们。随着模型参数的不断提升,Prompt Tuning能够达到全量微调的效果。
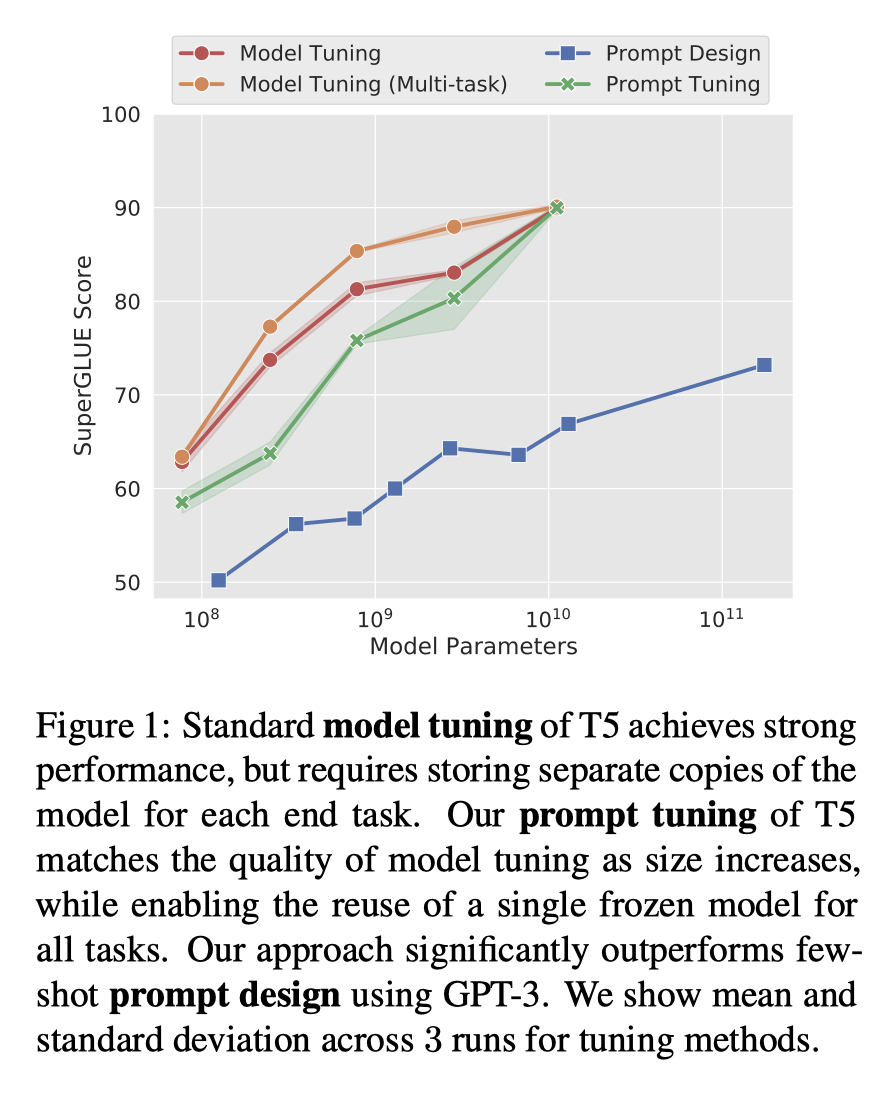
此外,Prompt Tuning 还提出了 Prompt Ensembling,也就是在一个批次(Batch)里同时训练同一个任务的不同 prompt(即采用多种不同方式询问同一个问题),这样相当于训练了不同模型,比模型集成的成本小多了。

Prompt Tuning简化了Prefix Tuning的运行方式,并实现了多任务推理、以及多任务集成训练,在模型层面没有进行任何的改动。
P-Tuning
技术原理
论文:GPT Understands, Too
论文链接:https://www.sciencedirect.com/science/article/pii/S2666651023000141
作者指出大模型的Prompt构造方式回严重影响下游任务的效果。比如,更改一个提示中的一个单词可能回导致性能的大幅下降,甚至变动位置都会产生比较大的波动。因此作者提出了一种P-Tuning的方法,一种连续可微的virtual token。
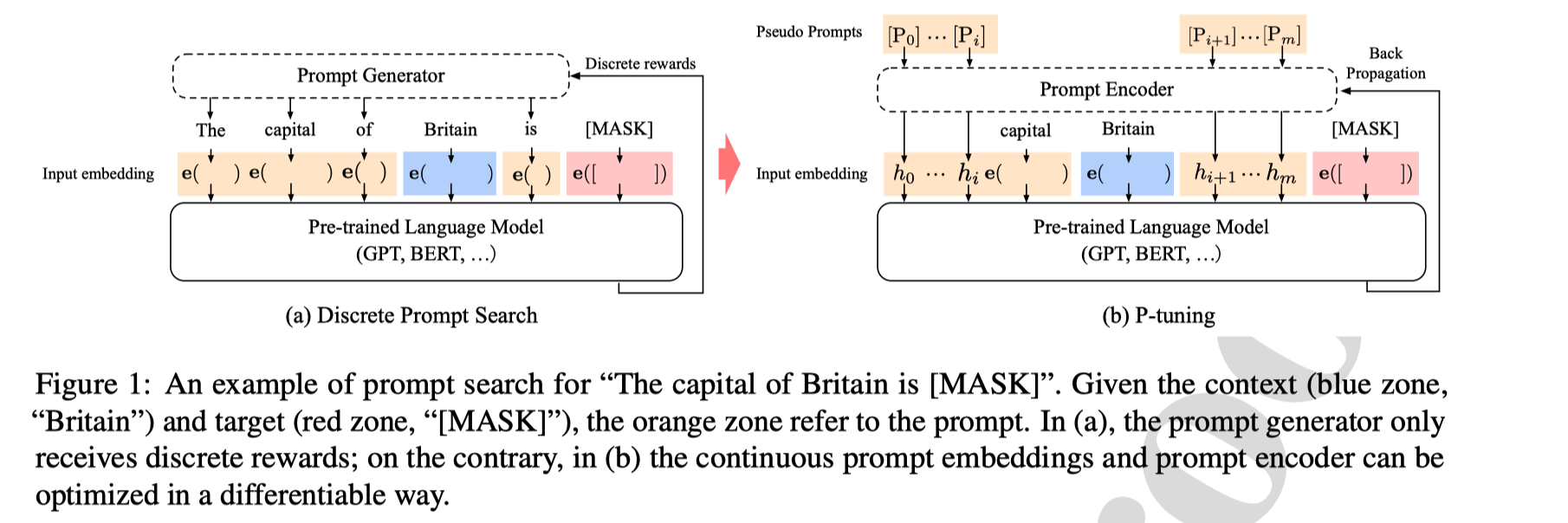
该方法将Prompt转化为可以学习的Embedding层,并利用MLP+LSTM的方式对Prompt Embedding进行处理。相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。
方法效果

从对比实验证实看出,P-Tuning获得了与全参数一致的效果。甚至在某些任务上优于全参数微调。
P-Tuning v2
技术原理
论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
论文链接:https://arxiv.org/pdf/2110.07602.pdf
与P-Tuning相比,该方法在每一层都加入了Prompt tokens作为输入,而不是仅仅加在输入层,这带来了2个好处:
- 更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。

方法效果

论文中展示了P-tuning v2在不同模型规模下的表现。对于简单的NLU任务,如SST-2(单句分类),Prompt Tuning和P-Tuning在较小的规模下没有显示出明显的劣势。但是当涉及到复杂的挑战时,如:自然语言推理(RTE)和多选题回答(BoolQ),它们的性能会非常差。相反,P-Tuning v2在较小规模的所有任务中都与微调的性能相匹配。并且,P-tuning v2在RTE中的表现明显优于微调,特别是在BERT中。
清华大学的团队发布的两种参数高效Prompt微调方法P-Tuning、P-Tuning v2,可以简单的将P-Tuning认为是针对Prompt Tuning的改进,P-Tuning v2认为是针对Prefix Tuning的改进。
LoRA
技术原理
论文:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
论文链接:https://arxiv.org/pdf/2106.09685.pdf%C2%A0
作者指出Adapter系列方法的缺点:在实际的推理场景下,由于其顺序的推理的性质,Batch为1的情况会增加很多延迟;指出可训练提示微调的方法的缺点:性能在可训练参数中的非单一变化(只有在参数量达到一定程度时,才能媲美全量微调)。LoRA提出了大语言模型的低秩矩阵的方法,没有在推理时带来额外的延迟。
具体的方法:在涉及到矩阵相乘的模块,在原始的PLM(Pretrained Large Model)旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的本征秩(intrinsic rank)。
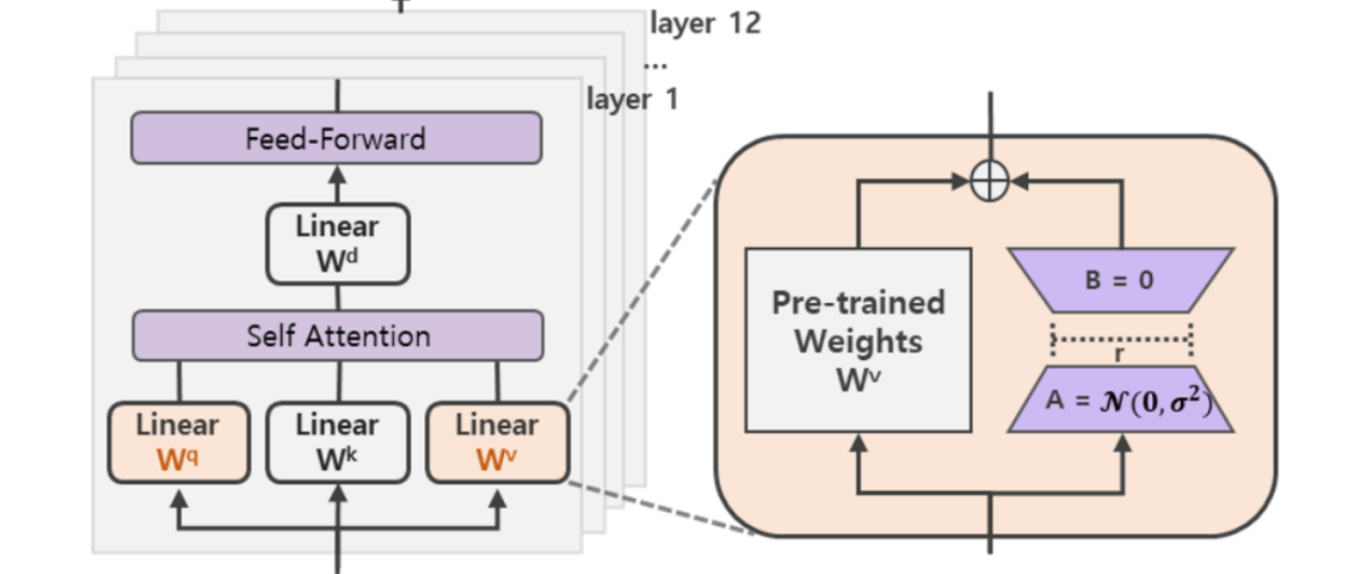
可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,其中,r«d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多。

在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数A和B,将PLM跟新增的通路两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的),即h=Wx+BAx。第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0从而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,对于推理来说,不会增加额外的计算资源。
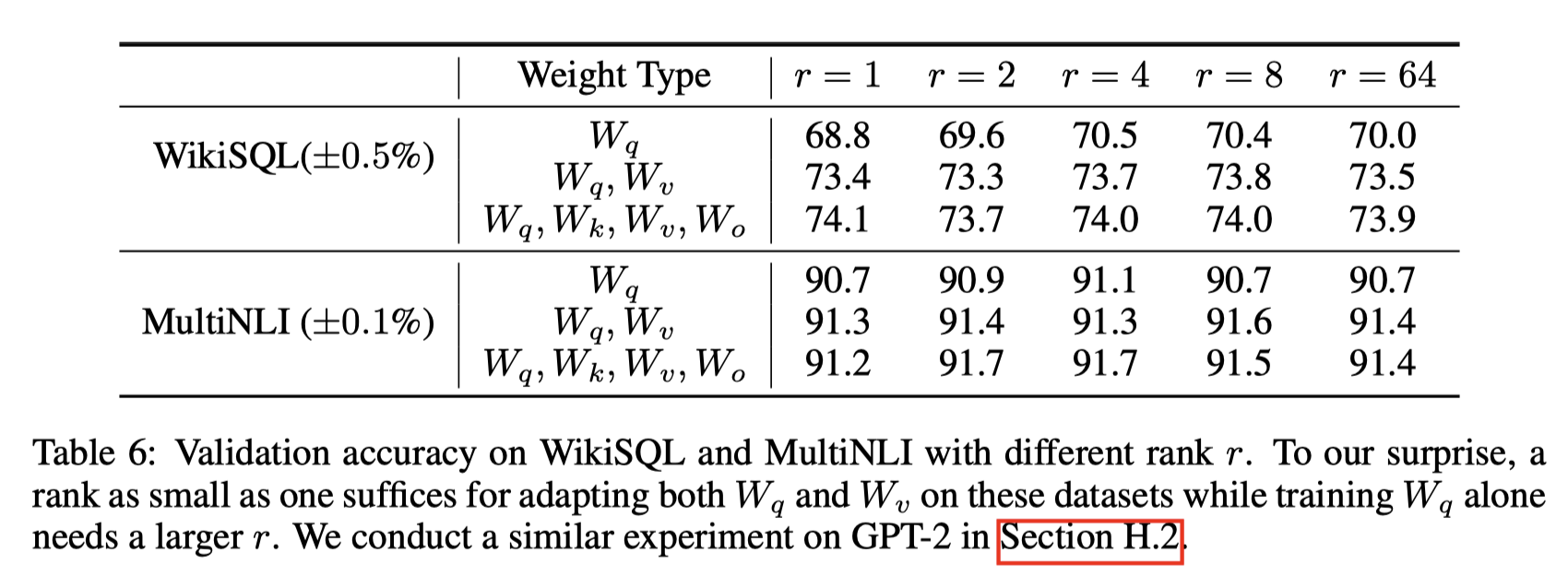
此外,Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果。
实验还发现,保证权重矩阵的种类的数量比起增加隐藏层维度r更为重要,增加r并不一定能覆盖更加有意义的子空间。

关于秩$r$的选择,通常情况下为4,8,16即可。
方法效果
众多数据集上LoRA在只训练极少量参数的前提下,最终在性能上能和全量微调匹配,甚至在某些任务上优于全量微调。
AdaLoRA
技术原理
论文:ADAPTIVE BUDGET ALLOCATION FOR PARAMETEREFFICIENT FINE-TUNING
论文链接:https://arxiv.org/pdf/2303.10512.pdf
AdaLoRA是对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵。具体做法如下:
- 调整增量矩分配。AdaLoRA将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
- 以奇异值分解的形式对增量更新进行参数化,并根据重要性指标裁剪掉不重要的奇异值,同时保留奇异向量。由于对一个大矩阵进行精确SVD分解的计算消耗非常大,这种方法通过减少它们的参数预算来加速计算,同时,保留未来恢复的可能性并稳定训练。
- 在训练损失中添加了额外的惩罚项,以规范奇异矩阵P和Q的正交性,从而避免SVD的大量计算并稳定训练。
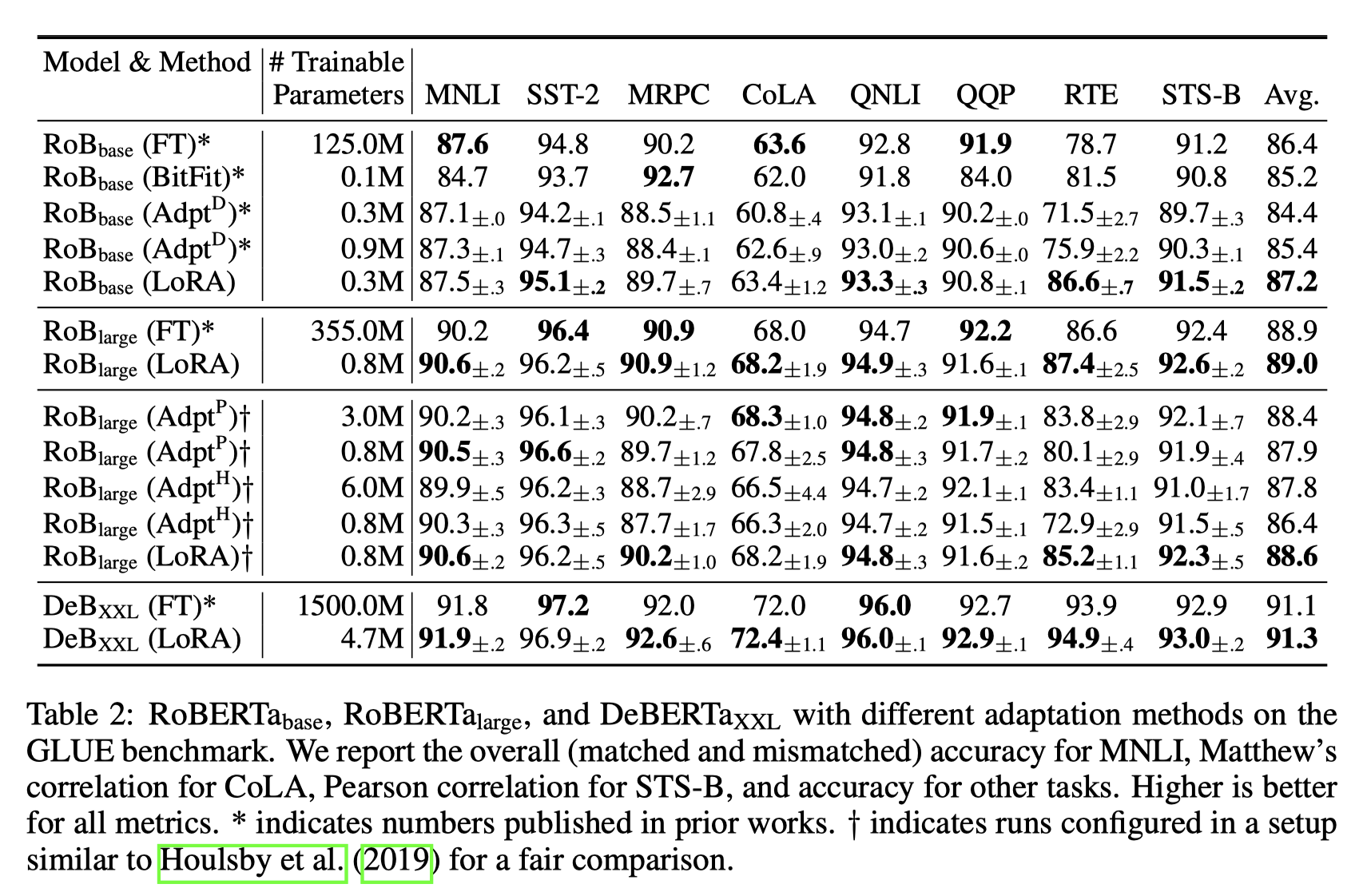
方法效果
通过实验证明,AdaLoRA 实现了在所有预算、所有数据集上与现有方法相比,性能更好或相当的水平。 例如,当参数预算为 0.3M 时,AdaLoRA 在RTE数据集上,比表现最佳的基线(Baseline)高 1.8%。
QLoRA
技术原理
论文: QLORA: Efficient Finetuning of Quantized LLMs
论文链接:https://arxiv.org/pdf/2305.14314.pdf
微调大型语言模型 (LLM) 是提高其性能以及添加所需或删除不需要的行为的一种非常有效的方法。然而,微调非常大的模型非常昂贵;以 LLaMA 65B 参数模型为例,常规的 16 bit微调需要超过 780 GB 的 GPU 内存。
虽然最近的量化方法可以减少 LLM 的内存占用,但此类技术仅适用于推理场景。
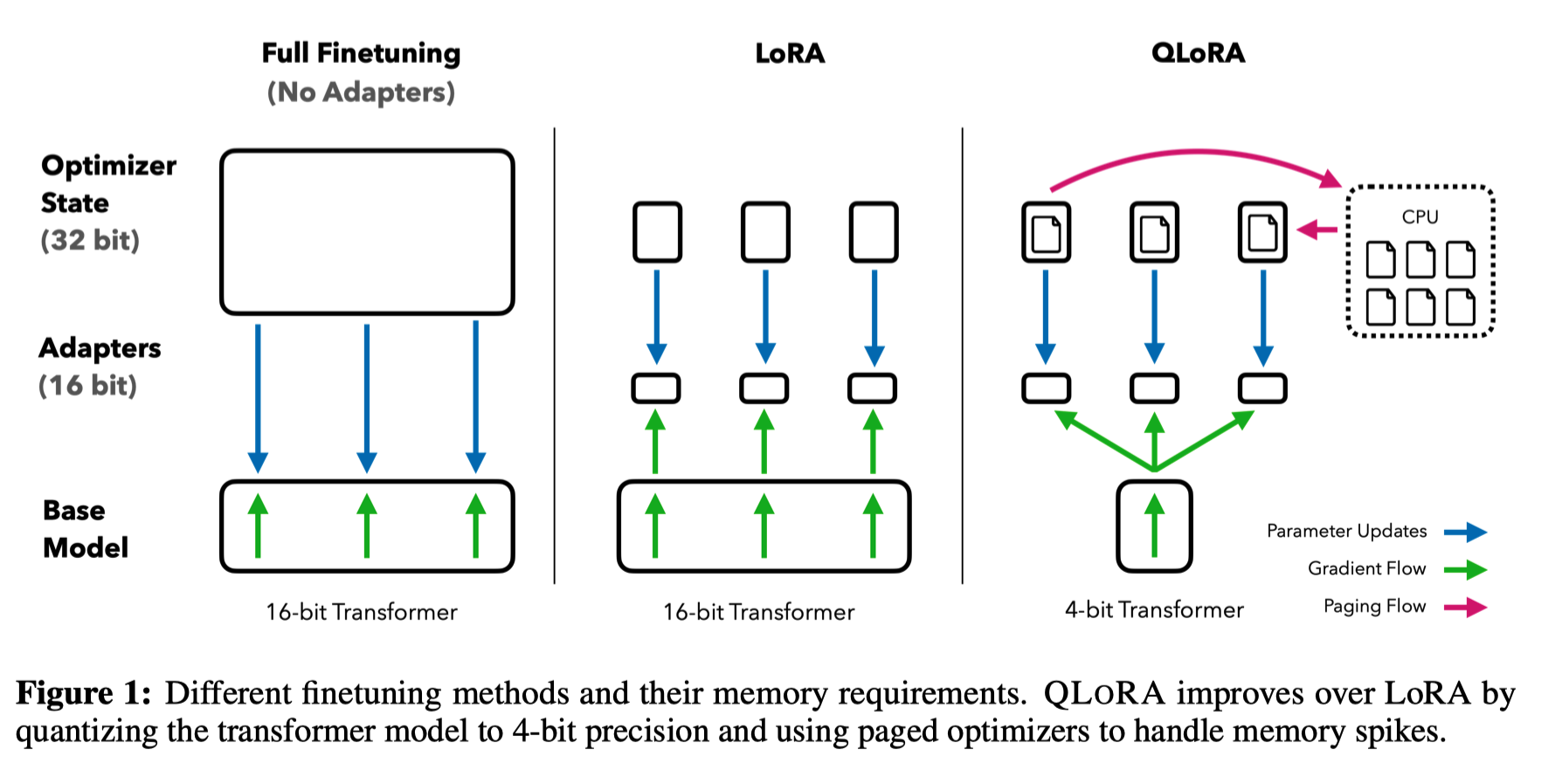
基于此,作者提出了QLoRA,并首次证明了可以在不降低任何性能的情况下微调量化为 4 bit的模型。
- 4bit NormalFloat(NF4):该数据类型对正态分布数据产生比4bit整数和4bit浮点数更好的效果
- 双量化:对第一次量化后的那些常量再进行一次量化,减少存储空间。
- 分页优化器:使用NVIDIA统一内存特性,该特性可以在在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理。该功能的工作方式类似于 CPU 内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,然后在 GPU 内存不足时将其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。
方法效果
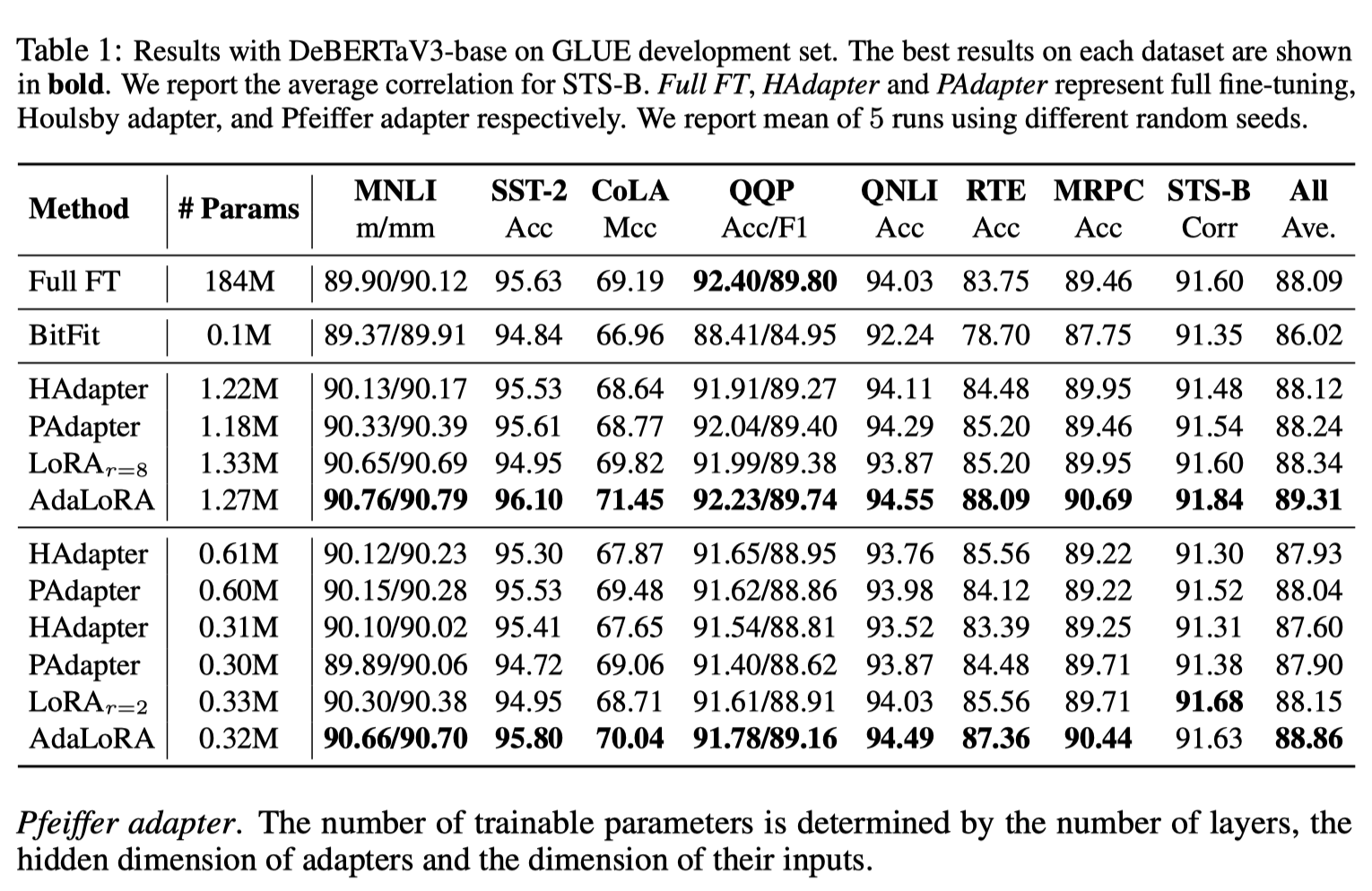
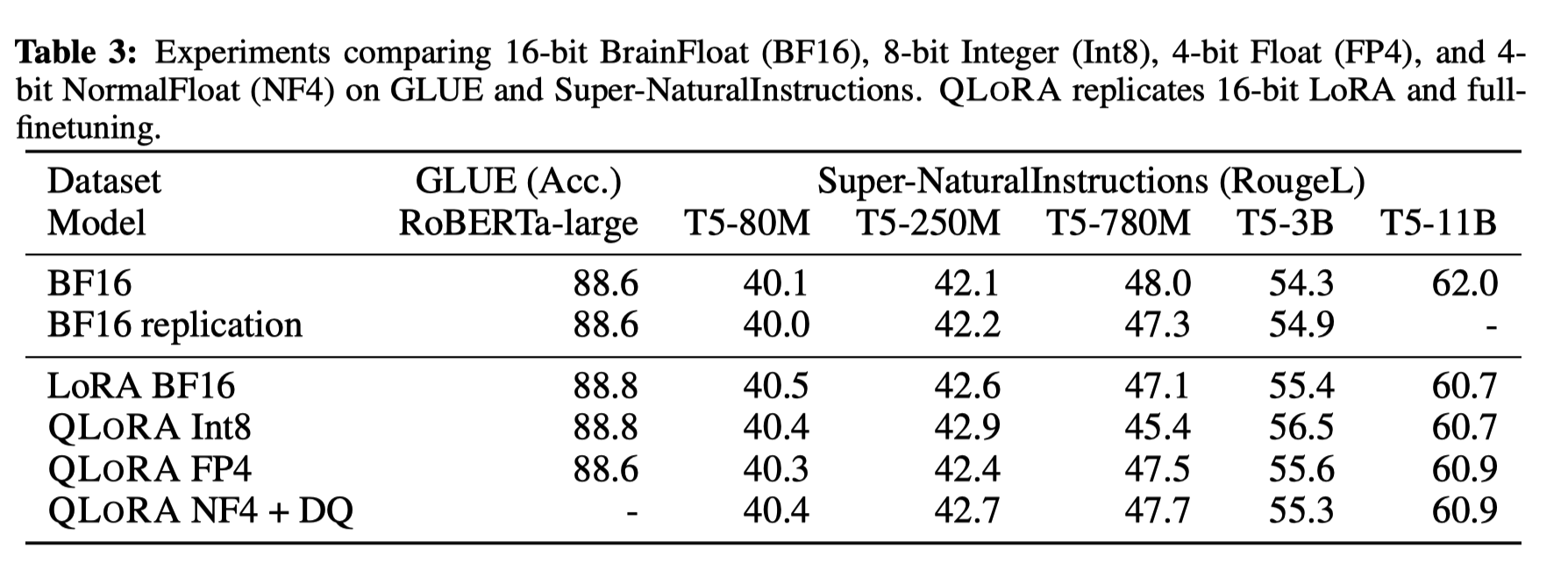
实验证明,无论是使用16bit、8bit还是4bit的适配器方法,都能够复制16bit全参数微调的基准性能。这说明,尽管量化过程中会存在性能损失,但通过适配器微调,完全可以恢复这些性能。
总结
大模型高效微调的两个方向:
- 方向一:添加小型网络模块:将小型网络模块添加到PLMs中,保持基础模型保持不变的情况下仅针对每个任务微调这些模块,可以用于所有任务。这样,只需引入和更新少量任务特定的参数,就可以适配下游的任务,大大提高了预训练模型的实用性。如:Adapter tuning、Prefix tuning、Prompt Tuning等,这类方法虽然大大减少了内存消耗。但是这些方法存在一些问题,比如:Adapter tuning引入了推理延时;Prefix tuning或Prompt tuning直接优化Prefix和Prompt是非单调的,比较难收敛,并且消耗了输入的token。
- 方向二:下游任务增量更新:对预训练权重的增量更新进行建模,而无需修改模型架构,即W=W0+△W。比如:Diff pruning、LoRA等, 此类方法可以达到与完全微调几乎相当的性能,但是也存在一些问题,比如:Diff pruning需要底层实现来加速非结构化稀疏矩阵的计算,不能直接使用现有的框架,训练过程中需要存储完整的∆W矩阵,相比于全量微调并没有降低计算成本。 LoRA则需要预先指定每个增量矩阵的本征秩 r 相同,忽略了在微调预训练模型时,权重矩阵的重要性在不同模块和层之间存在显著差异,并且只训练了Attention,没有训练FFN,事实上FFN更重要。
最后修改于 2023-10-25

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。