CUDA编程实战
Hello GPU
编写第一个gpu程序
一般来说,CUDA程序是.cu结尾的程序!
hello-gpu.cu:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#include <stdio.h>
void cpu() {
printf("hello cpu\n");
}
__global__ void gpu() {
printf("hello gpu\n");
}
int main() {
cpu();
gpu<<<1, 1>>>();
// 等待cpu和gpu同步
cudaDeviceSynchronize();
}
|
__global__:
- __global__关键字代表以下函数将在GPU山运行并全局可调用。
- 通过我们将在cpu上执行的代码称为主机代码,而在GPU上运行的代码称为设备代码。
- 注意返回类型为void。使用__global__关键字定义的函数需要返回void类型。
gpu«<1, 1»>():
- 通常,当调用要在GPU上运行的函数时,我们将这种函数称为
已启动的核函数。
- 启动核函数之前必须提供执行的配置,在向核函数传递任何预期参数之前使用
<<<...>>>语法完成配置。
- 程序员可通过执行配置为核函数启动指定线程层次结构,从而定义
线程组(也称为线程块)的数量,以及要在每个线程块中执行的线程数量。这里就代表正在使用包含1线程(第二个配置参数)的1线程块(第一个配置参数)启动核函数。
cudaDeviceSynchronize():
- 与大部分c/c++代码不同,核函数启动方式为异步:CPU代码将继续执行而无需等待核函数完成启动。
- 调用CUDA运行时提供的函数cudaDeviceSynchronize将导致主机(cpu)代码暂停,直至设备(GPU)代码执行完成,才能在cpu上恢复执行。
使用nvcc编译、链接、执行
1
|
nvcc -o hello-gpu hello-gpu.cu -run
|
看到
说明你编译、链接、执行成功。
网格、块、线程
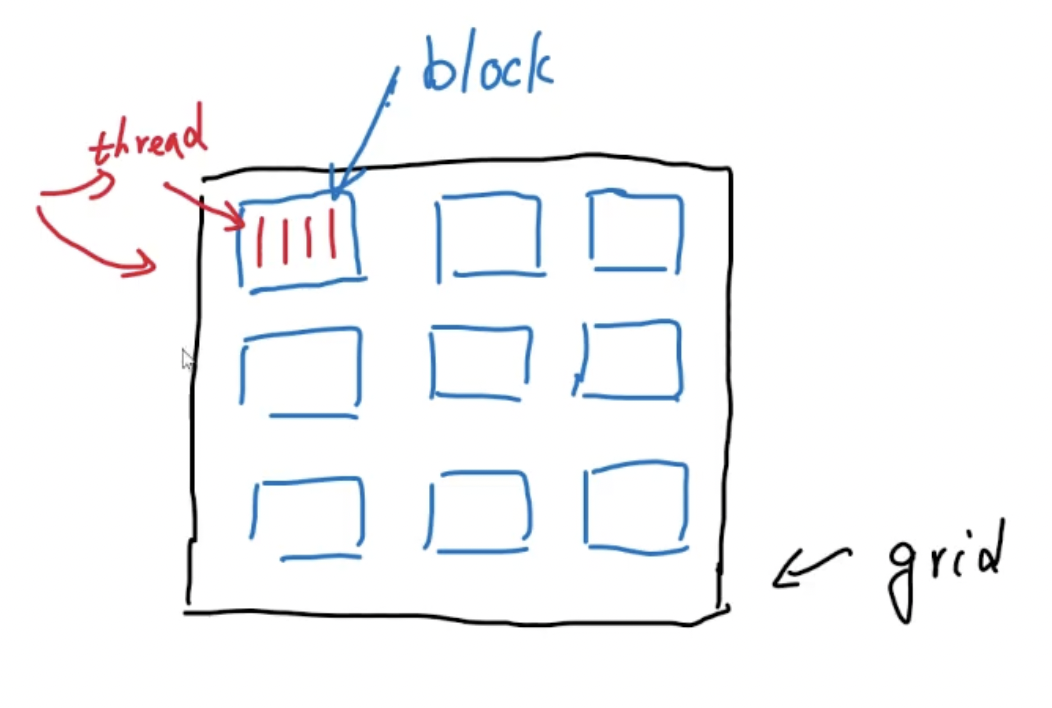
注意,上述结构并不是硬件结构,而是软件逻辑概念!
一个GPU中有多个线程块,每个线程块中含有不同的线程,每个线程能执行一个程序。多个线程块组成一个网格。在实际的编程中,一个Block可以最多放1024个线程。
如何使用CUDA编程语言来表示这些含义
- gridDim.x 表示网格的线程块个数
- blockIdx.x 表示当前块的索引
- blockDim.x 表示块的线程数
- threadIdx.x 表示当前中线程的索引
假设执行performWork<<<2, 4>>>()代表线程块个数为2,块中的线程数为4
将我们的hello-gpu.cu文件修改执行一下,改成了gpu<<<2, 4>>>(),打印的结果为1个cpu和8个gpu。说明gpu的程序同时有8个线程一起执行了它。
我现在需要指定某个块中的某个CUDA线程来执行它,则需要通过两个索引值来判断:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#include <stdio.h>
void cpu() {
printf("hello cpu\n");
}
__global__ void gpu() {
if (blockIdx.x == 0 && threadIdx.x == 0)
printf("hello gpu\n");
}
int main() {
cpu();
gpu<<<1, 1>>>();
// 等待cpu和gpu同步
cudaDeviceSynchronize();
}
|
执行的结果变为了一个cpu和一个gpu。
显而易见,在GPU上执行循环的复杂度由原来的O(n)变成了O(1)。
题外话,CPU也能并发线程,那为什么CPU不好:其实CPU在软件层面上能同时开20个或者30个等线程,但这都是通过操作系统调度时间切片做到的,但实际上从物理的层面上只能同时跑8个线程,通过4个ALU同时跑4个线程,通过寄存器复制实现超线程扩展到8个。
显存分配
如何区分每个线程id
通过计算blockIdx.x * blockDim.x + threadIdx.x的值区分不同的线程id。
cpu分配内存/gpu分配显存
1
2
3
4
5
6
7
8
9
10
11
12
|
//cpu
int N = 2 << 20;
size_t size = N * sizeof(int);
int *a;
a = (int *)malloc(size);//分配内存
free(a);
//gpu
int N = 2 << 20;
size_t size = N * sizeof(int);
int *a;
cudaMallocManaged(&a, size);
cudaFree(a);
|
需要注意的是cudaMallocManaged()分配的是统一内存,既可以被cpu使用,也可以被gpu使用。
通过一个例子来学习显存分配:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
#include <stdio.h>
#include <stdlib.h>
void cpu(int *a, int N) {
for (int i = 0; i < N; i++) {
a[i] = i;
}
}
__global__ void gpu(int *a, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
A[i] *= 2;
}
}
bool check(int *a, int N) {
for (int i = 0; i < N; i++) {
if (a[i] != i * 2) return false;
}
return true;
}
int main() {
const int N = 100;
size_t size = N * sizeof(int);
int * a;
//分配通用内存
cudaMallocManaged(&a, size);
cpu(a, N); // cpu进行操作
size_t threads = 256;//线程块中线程的个数
size_t blocks = (N + threads - 1) / threads; //向上取整计算
gpu<<<blocks, threads>>>(a, N); //gpu进行操作
cudaDeviceSynchronize(); //cpu和gpu同步(如果不进行同步check必然为error)
check(a, N) ? printf("ok") : printf("error");
/* 最后输出的结果为ok */
cudaFree(a);
}
|
通用内存既可以被cpu调用也可以被gpu调用。
跨步循环
当需要并行的过程远大于线程数,便可以使用跨步循环,跨了多少步,同一个线程就运行了多少次:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
#include <stdio.h>
#include <stdlib.h>
void cpu(int *a, int N) {
for (int i = 0; i < N; i++) {
a[i] = i;
}
}
__global__ void gpu(int *a, int N) {
int threadi = blockIdx.x * blockDim.x + threadIdx.x;
int stride = gripDim.x * blockDim.x;
for (int i = threadi; i < N; i += stride) {
a[i] *= 2;
}
}
bool check(int *a, int N) {
for (int i = 0; i < N; i++) {
if (a[i] != i * 2) return false;
}
return true;
}
int main() {
const int N = 100;
size_t size = N * sizeof(int);
int * a;
//分配通用内存
cudaMallocManaged(&a, size);
cpu(a, N); // cpu进行操作
size_t threads = 256;//线程块中线程的个数
size_t blocks = 1;
gpu<<<blocks, threads>>>(a, N); //gpu进行操作
cudaDeviceSynchronize(); //cpu和gpu同步(如果不进行同步check必然为error)
check(a, N) ? printf("ok") : printf("error");
cudaFree(a);
}
|
异常处理
普通函数异常处理
假设一个分配内存的函数出现了错误,我们可以用cuda内置的cudaError_t类型来返回是否错误。
1
2
3
4
5
|
cudaError_t err;
err = cudaMallocManaged(&a, size);
if (err != cudaSuccess) {
printf("Error: %s\n", cudaGetErrirString(err));
}
|
Kernel函数的异常处理
核函数的没有返回值,这需要如何处理,cuda也专门提供了cudaGetLastError()函数来返回是否错误:
1
2
3
4
5
|
gpu<<<blocks, threads>>>(a, N);
err = cudaGetLastError();
if (err != cudaSuccess) {
printf("Error: %s\n", cudaGetErrirString(err));
}
|
在实际的c++编程中,我们通常会将其写成一个inline函数统一使用:
1
2
3
4
5
6
7
|
inline cudaError_t checkCuda(cudaError_t result) {
if (result != cudaSuccess) {
fprintf(stderr, "CUDA runtime error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
|
那么这段程序的调用方法就显而易见了:
1
2
|
checkCuda(cudaGetLastError());
checkCuda(cudaMallocManaged(&a, size));
|
inline函数和普通函数的区别
普通函数:
- 普通函数定义通常放在头文件(.h)中,实现放在源文件(.cpp)中。
- 每次函数调用时,程序会跳转到函数的地址执行函数体中的代码。
- 普通函数适合处理较大的代码块和复杂的逻辑。
inline函数:
inline关键字用于建议编译器将函数调用处的代码替换为函数体中的代码,而不是通过跳转执行函数。inline函数通常定义放在头文件中,并且在同一编译单元内直接展开函数调用。- 适用于短小的、频繁调用的函数,比如简单的getter和setter函数,以避免函数调用的开销。
区别总结:
inline函数是对编译器的建议,而不是强制要求。编译器有权忽略inline关键字。- 普通函数一般用于处理复杂的逻辑,而
inline函数用于短小的频繁调用的代码块,以节省函数调用开销。
inline函数在编译时展开代码,而普通函数是跳转执行函数体中的代码。
需要注意的是,如果函数体较大或者在多个地方调用,编译器可能会忽略inline关键字,将其当作普通函数处理。此外,过度使用inline可能导致代码膨胀,增加代码段的大小,反而可能影响性能。**因此,inline应谨慎使用,最好只用于短小的、频繁调用的函数。**编译器在优化方面通常会自动处理函数的内联,不需要手动添加inline关键字。
矩阵加法
分别通过cpu和gpu实现矩阵的加法运算
matrix.cu:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
#include <stdio.h>
#define N 64
__global__ void gpu(int *a, int *b, int *c_gpu) {
int r = blockDim.x * blockIdx.x + threadIdx.x;
int c = blockDim.y * blockIdx.y + threadIdx.y;
if (r < N && c < N) {
c_gpu[r * N + c] = a[r * N + c] + b[r * N + c];
}
}
void cpu(int *a, int *b, int *c_cpu) {
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
c_cpu[r * N + c] = a[r * N + c] + b[r * N + c];
}
}
}
bool check(int *a, int *b, int *c_cpu, int *c_gpu) {
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
if (c_cpu[r * N + c] != c_gpu[r * N + c]) return false;
}
}
return true;
}
int main() {
int *a, *b, *c_cpu, *c_gpu;
size_t size = N * N * sizeof(int);
//分配globalmemory
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c_cpu, size);
cudaMallocManaged(&c_gpu, size);
//初始化
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
a[r * N + c] = r;
b[r * N + c] = c;
c_cpu[r * N + c] = 0;
c_gpu[r * N + c] = 0;
}
}
dim3 threads(16, 16, 1);
dim3 blocks((N + threads.x - 1) / threads.x, N + threads.y - 1) / threads.y, 1);
gpu<<<blocks, threads>>>(a, b, c_gpu);
//同步到cpu上
cudaDeviceSynchronize();
cpu(a, b, c_cpu);
check(a, b, c_cpu, c_gpu) ? printf("ok!\n") : printf("error!\n");
cudaFree(a);
cudaFree(b);
cudaFree(c_cpu);
cudaFree(c_gpu);
}
|
CUDA性能分析
安装NVIDIA Nsight Systems
- 进入官网,下载
Nsight Systems的Linux CLI的.deb版本

1
|
$ sudo dpkg -i NsightSystems-linux-cli-public-2023.2.1.122-3259852.deb
|
1
2
|
#application是程序,application-arguments是程序参数
$ nsys [global-options] profile [options] <application> [application-arguments]
|
参数的选择如下图所示:

1
|
$ nsys profile --stats=true matrix
|

可以看到我们的程序的大部分时间都花在了显存分配这件事上,那么我们优化的目标就是让GPU计算的时间占总时间的比重更大,那么程序的效率就会越高。
GPU属性
GPU内部有许多称为SM的流多处理器,一个SM有多个流处理器,GPU在执行Kernel函数的时候,会让SM去处理Block。
SM会在一个名为WARP的线程块内创建、管理、调度和执行32个线程的线程组。所以线程数选32的倍数最佳!!
GPU信息获取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#include <stdio.h>
int main() {
int id;
cudaGetDevice(&id);
cudaDeviceProp props;
cudaGetDeviceProperties(&props, id);
printf("Device id: %d\n \
SM_num: %d\n \
capability major: %d\n \
capability minor: %d\n \
warp size: %d\n"\
, id, props.multiProcessorCount, props.major, props.minor, props.warp);
}
|
编译运行后得到结果:
1
2
3
4
5
|
Device id: 0
SM_num: 28
capability major: 8
capability minor: 6
warp size: 32
|
查询我的显卡(RTX3060)的流处理器总共有3564个,那么一个SM(流多处理器)的流处理器个数为128个。
显存分配(2)
前面我们使用的显存分配方式为cudaMallocManaged()方法,这种方法第一时间分配的其实并不是显存,而是统一内存(UM)。分配UM时,内存尚未驻留在主机(Host)上或设备(Device)上。主机或者设备尝试访问内存时会发生缺页中断,此时主机或者设备才会批量迁移所需要的数据。也就是说CPU和GPU访问该内存都会发生上述的事件。
如果分配的内存既被CPU调用,又被GPU调用,那么便可以使用这种分配方式。
我们使用CUDA性能分析工具对前面hello-gpu的程序块进行分析:
1
|
$ nsys profile --stats=true hello-gpu
|
得到的部分信息如下:

可以看到有HtoD和DtoH,这是由缺页触发的。
如何避免缺页触发内存拷贝?
我们可以通过cudaMemPrefetchAsync函数将托管内存异步预取到GPU设备上或CPU。那么在代码上该如何操作(在前面matrix.cu上进行修改):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
#include <stdio.h>
#define N 64
__global__ void gpu(int *a, int *b, int *c_gpu) {
int r = blockDim.x * blockIdx.x + threadIdx.x;
int c = blockDim.y * blockIdx.y + threadIdx.y;
if (r < N && c < N) {
c_gpu[r * N + c] = a[r * N + c] + b[r * N + c];
}
}
void cpu(int *a, int *b, int *c_cpu) {
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
c_cpu[r * N + c] = a[r * N + c] + b[r * N + c];
}
}
}
bool check(int *a, int *b, int *c_cpu, int *c_gpu) {
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
if (c_cpu[r * N + c] != c_gpu[r * N + c]) return false;
}
}
return true;
}
int main() {
int *a, *b, *c_cpu, *c_gpu;
size_t size = N * N * sizeof(int);
//分配globalmemory
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c_cpu, size);
cudaMallocManaged(&c_gpu, size);
//初始化
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
a[r * N + c] = r;
b[r * N + c] = c;
c_cpu[r * N + c] = 0;
c_gpu[r * N + c] = 0;
}
}
//在GPU访问统一内存之前进行预取,防止发生缺页影响性能
int id;
cudaGetDevice(&id);
cudaMemPrefetchAsync(a, size, id);
cudaMemPrefetchAsync(b, size, id);
cudaMemPrefetchAsync(c_gpu, size, id);
dim3 threads(16, 16, 1);
dim3 blocks((N + threads.x - 1) / threads.x, N + threads.y - 1) / threads.y, 1);
gpu<<<blocks, threads>>>(a, b, c_gpu);
//数据同步到CPU之前将GPU的内存预取到CPU上
//同步到cpu上
cudaDeviceSynchronize();
cpu(a, b, c_cpu);
check(a, b, c_cpu, c_gpu) ? printf("ok!\n") : printf("error!\n");
cudaFree(a);
cudaFree(b);
cudaFree(c_cpu);
cudaFree(c_gpu);
}
|
对旧的matrix.cu和新的matrix.cu分别进行编译并进行性能分析:
旧的matrix.cu:

新的matrix.cu:

明显可以看到内存拷贝的开销变少了。无论是Host->Device还是Device->Host。
显存分配(3)
那么CUDA编程中除了分配统一内存,是否可以直接分配GPU显存,或者CPU锁页内存。
cudaMalloc命令将直接为处于活动状态的GPU分配显存。这可以防止出现所有GPU分页错误,而代价是主机代码将无法访问该命令返回的指针。cudaMallocHost命令将直接为CPU分配内存。该命令可以"固定"内存(pinned memory)或"锁页"内存(page-locked memory)。它允许将内存异步拷贝至GPU或从GPU异步拷贝至内存。固定内存过多则会干扰CPU性能。释放固定内存时,应使用cudaFreeHost命令。- 无论是从主机到设备还是设备到主机,
cudaMemcpy命令均可拷贝(而非传输)内存。
我们将之前的matrix.cu再次改写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
#include <stdio.h>
#include <assert>
#define N 64
__global__ void gpu(int *a_gpu, int *b_gpu, int *c_gpu) {
int r = blockDim.x * blockIdx.x + threadIdx.x;
int c = blockDim.y * blockIdx.y + threadIdx.y;
if (r < N && c < N) {
c_gpu[r * N + c] = a_gpu[r * N + c] + b_gpu[r * N + c];
}
}
void cpu(int *a_cpu, int *b_cpu, int *c_cpu) {
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
c_cpu[r * N + c] = a_cpu[r * N + c] + b_cpu[r * N + c];
}
}
}
bool check(int *c_cpu, int *c_gpu) {
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
if (c_cpu[r * N + c] != c_gpu[r * N + c]) return false;
}
}
return true;
}
inline cudaError_t checkCuda(cudaError_t result) {
if (result != cudaSuccess) {
fprintf(stderr, "CUDA runtime error: %s\n", cudaGetErrorString(result));
assert(result == cudaSuccess);
}
return result;
}
int main() {
int *a_cpu, *b_cpu, *a_gpu, *b_gpu, *c_gpu2cpu, *c_cpu, *c_gpu;
size_t size = N * N * sizeof(int);
//分配memory
cudaMallocHost(&a_cpu, size);
cudaMallocHost(&b_cpu, size);
cudaMallocHost(&c_cpu, size);
cudaMallocHost(&c_gpu2cpu, size);
cudaMalloc(&a_gpu, size);
cudaMalloc(&b_gpu, size);
cudaMalloc(&c_gpu, size);
//初始化
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
a_cpu[r * N + c] = r;
b_cpu[r * N + c] = c;
c_cpu[r * N + c] = 0;
c_gpu2cpu[r * N + c] = 0;
//c_gpu[r * N + c] = 0; 不能直接访问GPU
}
}
cpu(a_cpu, b_cpu, c_cpu);
dim3 threads(16, 16, 1);
dim3 blocks((N + threads.x - 1) / threads.x, N + threads.y - 1) / threads.y, 1);
//理论上的内存拷贝,但其实不需要,因为锁页内存在CUDA中不会被映射到硬盘上,但可以直接被GPU调用
cudaMemcpy(a_gpu, a_cpu, size, cudaMemcpyHostToDevice);
cudaMemcpy(b_gpu, b_cpu, size, cudaMemcpyHostToDevice);
gpu<<<blocks, threads>>>(a_gpu, b_gpu, c_gpu);
//同步到cpu上
cudaDeviceSynchronize();
cudaMemcpy(c_gpu2cpu, c_cpu, size, cudaMemcpyDeviceToHost);
check(c_cpu, c_gpu) ? printf("ok!\n") : printf("error!\n");
cudaFreeHost(a_cpu);
cudaFreeHost(b_cpu);
cudaFreeHost(c_cpu);
cudaFreeHost(c_gpu2cpu);
cudaFree(c_gpu);
cudaFree(a_gpu);
cudaFree(b_gpu);
}
|
为什么GPU可以直接调用cudaMallocHost分配的锁页内存?
在CUDA编程中,使用cudaMallocHost函数分配的内存是锁页内存,这意味着该内存页不会被交换到磁盘上,从而提高了访问速度。此外,锁页内存还可以直接与GPU内存进行数据传输,而不需要通过PCIe总线,从而进一步提高了数据传输速度。
在CUDA编程中,GPU可以直接使用cudaMallocHost分配的锁页内存,是因为这些内存页已经被固定在物理内存中,并且可以直接映射到GPU的地址空间中。因此,在Kernel函数中可以直接访问这些内存页,而不需要进行额外的数据传输或者拷贝操作。
需要注意的是,在使用锁页内存时需要小心,因为它们会占用较多的系统内存,并且可能会导致系统变慢或者崩溃。因此,在使用锁页内存时需要谨慎考虑内存使用量,并且及时释放不再需要的内存。
CUDA流
在CUDA编程中,流是按照顺序执行的一系列命令构成。在CUDA应用程序中,核函数的执行以及一些内存传输均在CUDA流中进行。
CUDA流行为的几项规则:
- 在给定流中所有操作回按序执行。
- 就不同非默认流中的操作而言,无法保证会按彼此之间的任何特定顺序执行
- 默认流具有阻断能力,它会等待其他已在运行的所有流完成当前操作后才运行,但其自身运行完毕之前,也会阻碍其他流的运行。
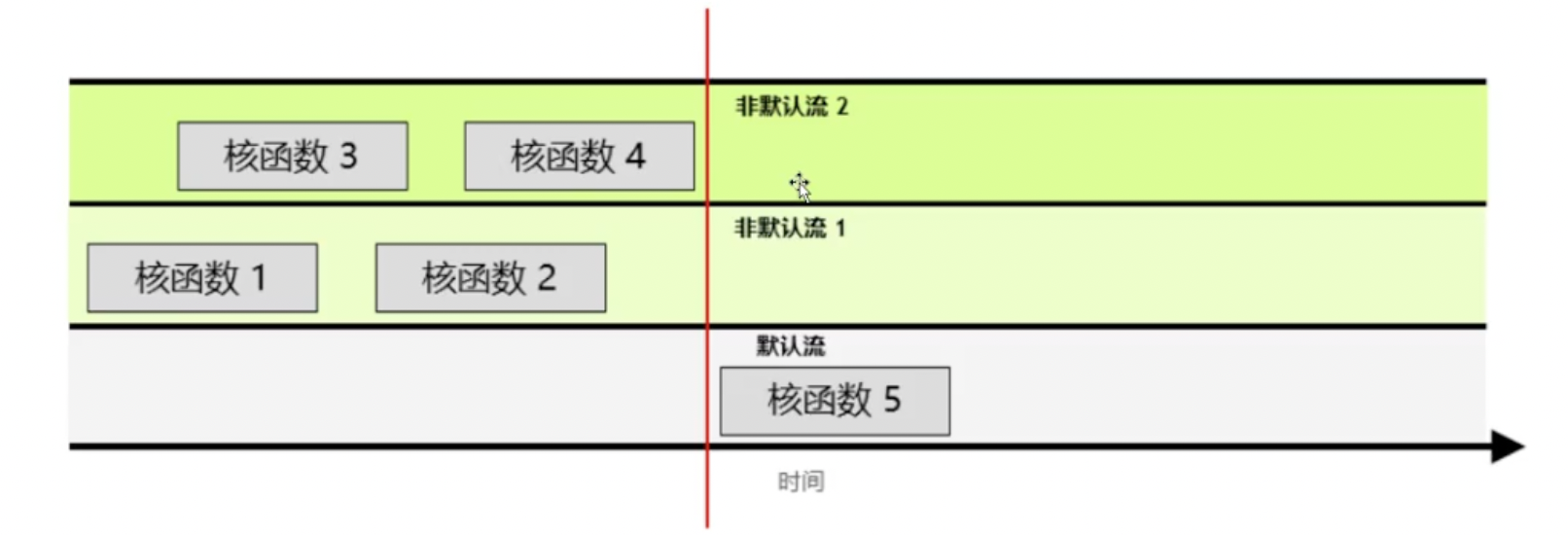
CUDA流如何创建,运行机制是什么?
用NVIDIA官方的例程来解释一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
#include <stdio.h>
const int N = 1 << 20;
__global__ void kernel(float *x, int n) {
int tid = threadIdx.x + blockIdx.x + blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] += sqrt(pow(3.14159, i));
}
}
int main() {
const int num_streams = 8;
cudaStream_t streams[num_streams];
float *data[num_streams];
for (int i = 0; i < num_streams; i++) {
cudaStreamCreate(&streams[i]);
cudaMalloc(&data[i], N * sizeof(float));
//launch one worker kernel per stream
kernel<<<1, 64, 0, streams[i]>>>(data[i], N);
//launch a dummy kernel
kernel<<<1, 1>>>(0, 0);
}
cudaDeviceReset();
return 0;
}
|
上面的kernel<<<1, 1>>>代表使用默认流,如果没有这句话,那么上面的每次计算几乎是并行的,因为每个Kernel函数执行的时间较长,不是默认流的情况下,新的流不断执行Kernel函数,而上一个Kernel函数还没有执行完,就会出现类似于流水线并行的方式。
如果有这个虚拟的默认流程序,就会将所有的Kernel函数分割成按序进行。因为在非默认流有函数运行时,默认流程序会等待;在默认流执行函数时,非默认流的程序必须等待。
通过流实现内存分配
cudaMemcpyAsync可以从主机到设备或从设备到主机异步复制内存。
与核函数的执行类似,cudaMemcpyAsync在默认情况下仅相对主机是异步的。默认情况下,它在默认流中执行,因此对于GPU上发生的其他CUDA操作而言,它是阻塞操作。
cudaMemcpyAsync函数将默认流作为可选的第5个参数。通过向其传递非默认流,可以将内存传输与其他默认流中发生的其他CUDA操作并发。
1
2
3
4
5
6
7
|
cudaStream_t stream;
cudaStreamCreate(&stream);
cudaMemcpyAsync(&device_array[segmentOffset],
&host_array[segmentOffset],
segmentSize,
cudaMemcpyHostToDevice,
stream);
|
将matrix_cudamalloc.cu修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
|
#include <stdio.h>
#include <assert.h>
#define N 10000
__global__ void gpu(int *a_gpu, int *b_gpu, int *c_gpu) {
int r = blockDim.x * blockIdx.x + threadIdx.x;
int c = blockDim.y * blockIdx.y + threadIdx.y;
if (r < N && c < N) {
c_gpu[r * N + c] = a_gpu[r * N + c] + b_gpu[r * N + c];
}
}
void cpu(int *a, int *b, int *c_cpu) {
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
c_cpu[r * N + c] = a[r * N + c] + b[r * N + c];
}
}
}
bool check(int *c_cpu, int *c_gpu) {
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
if (c_cpu[r * N + c] != c_gpu[r * N + c]) {
return false;
}
}
}
return true;
}
inline cudaError_t checkCuda(cudaError_t result) {
if (result != cudaSuccess) {
fprintf(stderr, "CUDA runtime error: %s\n", cudaGetErrorString(result));
assert(result != cudaSuccess);
}
return result;
}
int main() {
int *a_cpu, *b_cpu, *a_gpu, *b_gpu, *c_cpu, *c_gpu, *c_gpu2cpu;
size_t size = N * N * sizeof(int);
cudaMallocHost(&a_cpu, size);
cudaMallocHost(&b_cpu, size);
cudaMallocHost(&c_cpu, size);
cudaMallocHost(&c_gpu2cpu, size);
cudaMalloc(&a_gpu, size);
cudaMalloc(&b_gpu, size);
cudaMalloc(&c_gpu, size);
//初始化
for (int r = 0; r < N; r++) {
for (int c = 0; c < N; c++) {
a_cpu[r * N + c] = r;
b_cpu[r * N + c] = c;
c_cpu[r * N + c] = 0;
// c_gpu[r * N + c] = 0;
c_gpu2cpu[r * N + c] = 0;
}
}
cpu(a_cpu, b_cpu, c_cpu);
dim3 threads(16, 16, 1);
dim3 blocks((N + threads.x - 1) / threads.x, (N + threads.y - 1) / threads.y, 1);
cudaStream_t s1, s2, s3;
cudaStreamCreate(&s1);
cudaStreamCreate(&s2);
cudaStreamCreate(&s3);
//操纵GPU之前需要拷贝内存(新显卡不需要这项操作也是可以的)
cudaMemcpyAsync(a_gpu, a_cpu, size, cudaMemcpyHostToDevice, s1);
cudaMemcpyAsync(b_gpu, b_cpu, size, cudaMemcpyHostToDevice, s2);
gpu<<<blocks, threads>>>(a_gpu, b_gpu, c_gpu);
checkCuda(cudaGetLastError());
cudaMemcpyAsync(c_gpu2cpu, c_gpu, size, cudaMemcpyDeviceToHost, s3);
//将数据同步到我们的cpu上
cudaDeviceSynchronize();
check(c_cpu, c_gpu2cpu) ? printf("ok\n") : printf("error\n");
cudaStreamDestroy(s1);
cudaStreamDestroy(s2);
cudaFreeHost(a_cpu);
cudaFreeHost(b_cpu);
cudaFreeHost(c_cpu);
cudaFreeHost(c_gpu2cpu);
cudaFree(a_gpu);
cudaFree(b_gpu);
cudaFree(c_gpu);
}
|
可以看到我们将内存拷贝的过程交给了流,通过CUDA性能分析工具分析了程序。单向的内存拷贝不会进行重叠,也就是说同一时间主机向设备或者设备向主机只能进行一次内存拷贝。
CUDA共享内存
共享内存其实所谓的shared memory,其能为同一个线程块内所有线程共享。共享内存是一种稀缺资源,若线程位于分配内存的线程块之外,则无法访问共享内存,且此类内存在核函数执行完毕之后就会立即被释放。共享内存带宽远高于全局内存(global memory),有助于优化性能。
程序计时
CUDA编程有专门用于计时的程序:
1
2
3
4
5
6
7
8
9
|
cudaEvent_t startEvent, stopEvent;
cudaEventCreate(&startEvent);
cudaEventCreate(&stopEvent);
cudaEventRecord(startEvent, 0);
... //中间夹需要计算时间的程序
cudaEventRecord(stopEvent, 0);
//由于这个cudaEvent这个操作是异步的,所以需要Synchronize一下
cudaEventSynchronize(stopEvent);
cudaEventElapsedTime(&ms, startEvent, stopEvent);
|
共享内存使用
我们使用一个矩阵转置的例子来学习一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
/* CUDA程序:矩阵转置实现 */
#include <stdio.h>
#define TILE_DIM 32 //假设每次能操纵的矩阵小块的宽和高为32
#define BLOCK_SIZE 8
#define MX 2048
#define MY 2048
__global__ void transpose(float* outputdata, float* inputdata) {
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int w = gridDim.x * TILE_DIM;
if (x >= MX || y >= MY) return;
for (int i = 0; i < TILE_DIM; i += BLOCK_SIZE) {
outputdata[x * w + y + i] = inputdata[(y + i) * w + x];
}
}
bool check(float *c_cpu, float *c_gpu) {
for (int r = 0; r < MX; r++) {
for (int c = 0; c < MY; c++) {
if (c_cpu[r * MX + c] != c_gpu[r * MY + c]) {
return false;
}
}
}
return true;
}
int main() {
size_t size = MX * MY * sizeof(float);
float *H_idata, *H_odata, *D_idata, *D_odata, *res;
float ms; //用于记录程序计算使用的时间
cudaMallocHost(&H_idata, size);
cudaMallocHost(&H_odata, size);
cudaMallocHost(&res, size);
cudaMalloc(&D_idata, size);
cudaMalloc(&D_odata, size);
dim3 threads(TILE_DIM, BLOCK_SIZE, 1); // 给定线程数为TILE_DIM * BLOCK_SIZE
dim3 blocks((MX + TILE_DIM - 1) / threads.x, (MY + TILE_DIM - 1) / threads.y, 1);
for (int i = 0; i < MX; i++) {
for (int j = 0; j < MY; j++) {
H_idata[i * MY + j] = i * MY + j;
res[i * MY + j] = j * MY + i;
}
}
cudaEvent_t startEvent, stopEvent;
cudaEventCreate(&startEvent);
cudaEventCreate(&stopEvent);
cudaEventRecord(startEvent, 0);
cudaMemcpy(D_idata, H_idata, size, cudaMemcpyHostToDevice);
cudaMemcpy(D_odata, H_odata, size, cudaMemcpyHostToDevice);
// 开始计时
cudaEventRecord(startEvent, 0);
for (int i = 0; i < 100; i++) {
transpose<<<blocks, threads>>>(D_odata, D_idata);
}
// 停止计时
cudaEventRecord(stopEvent, 0);
// 异步操作等待同步
cudaEventSynchronize(stopEvent);
cudaEventElapsedTime(&ms, startEvent, stopEvent);
//打印计算信息
printf("%25s%25s\n", "Routine", "Bandwidth (GB/s)");
printf("%20.2f\n", 2 * MX * MY * sizeof(float) * 1e-6 * 100 / ms);
cudaMemcpy(H_odata, D_odata, size, cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
check(res, H_odata) ? printf("ok") : printf("error");
cudaFreeHost(H_idata);
cudaFreeHost(H_odata);
cudaFree(D_idata);
cudaFree(D_odata);
}
|
得到的带宽(global memory)计算出来为90GB/s左右。
接下来,我们要使用shared memory来优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
|
/* CUDA程序:矩阵转置实现 */
#include <stdio.h>
#define TILE_DIM 32 //假设每次能操纵的矩阵小块的宽和高为32
#define BLOCK_SIZE 8
#define MX 2048
#define MY 2048
__global__ void transpose2(float* outputdata, float* inputdata) {
// 一个block内部的share memory有32个存储块
__shared__ float title[TILE_DIM][TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int w = gridDim.x * TILE_DIM;
if (x >= MX || y >= MY) return;
for (int i = 0; i < TILE_DIM; i += BLOCK_SIZE) {
title[threadIdx.y + i][threadIdx.x] = inputdata[(y + i) * w + x];
}
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x;
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int i = 0; i < TILE_DIM; i += BLOCK_SIZE) {
outputdata[(y + i) * w + x] = title[threadIdx.x][threadIdx.y + i];
}
}
bool check(float *c_cpu, float *c_gpu) {
for (int r = 0; r < MX; r++) {
for (int c = 0; c < MY; c++) {
if (c_cpu[r * MX + c] != c_gpu[r * MY + c]) {
return false;
}
}
}
return true;
}
int main() {
size_t size = MX * MY * sizeof(float);
float *H_idata, *H_odata, *D_idata, *D_odata, *res;
float ms; //用于记录程序计算使用的时间
cudaMallocHost(&H_idata, size);
cudaMallocHost(&H_odata, size);
cudaMallocHost(&res, size);
cudaMalloc(&D_idata, size);
cudaMalloc(&D_odata, size);
dim3 threads(TILE_DIM, BLOCK_SIZE, 1); // 给定线程数为TILE_DIM * BLOCK_SIZE
dim3 blocks((MX + TILE_DIM - 1) / threads.x, (MY + TILE_DIM - 1) / threads.y, 1);
for (int i = 0; i < MX; i++) {
for (int j = 0; j < MY; j++) {
H_idata[i * MY + j] = i * MY + j;
res[i * MY + j] = j * MY + i;
}
}
cudaEvent_t startEvent, stopEvent;
cudaEventCreate(&startEvent);
cudaEventCreate(&stopEvent);
cudaEventRecord(startEvent, 0);
cudaMemcpy(D_idata, H_idata, size, cudaMemcpyHostToDevice);
cudaMemcpy(D_odata, H_odata, size, cudaMemcpyHostToDevice);
// 开始计时
cudaEventRecord(startEvent, 0);
for (int i = 0; i < 100; i++) {
transpose2<<<blocks, threads>>>(D_odata, D_idata);
}
// 停止计时
cudaEventRecord(stopEvent, 0);
// 异步操作等待同步
cudaEventSynchronize(stopEvent);
cudaEventElapsedTime(&ms, startEvent, stopEvent);
//打印计算信息
printf("%25s%25s\n", "Routine", "Bandwidth (GB/s)");
printf("%25s", "native transpose");
printf("%20.2f\n", 2 * MX * MY * sizeof(float) * 1e-6 * 100 / ms);
cudaMemcpy(H_odata, D_odata, size, cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
check(res, H_odata) ? printf("ok") : printf("error");
cudaFreeHost(H_idata);
cudaFreeHost(H_odata);
cudaFree(D_idata);
cudaFree(D_odata);
}
|
带宽(shared memory)来到了250GB/s左右。
优化分析
-
在这个优化后的CUDA程序中,使用了GPU的共享内存来实现矩阵转置操作。共享内存是每个block共享的内存空间,在block内的线程可以高效地进行数据交换和共享,从而提高并行计算效率。优化后的transpose2函数中,首先定义了一个大小为TILE_DIM x TILE_DIM的共享内存数组title,它用于暂存每个线程所需要的数据块。然后,将输入矩阵中的数据加载到共享内存中,其中每个线程负责加载一个数据块。接着,使用__syncthreads()进行同步,保证所有线程都已经加载完毕,然后再将共享内存中的数据写回到输出矩阵中,实现矩阵转置操作。这种优化的思路是将数据块加载到共享内存中,以减少对全局内存的访问次数,从而提高访存效率。由于共享内存的访问速度相比全局内存更快,且共享内存是block级别的,因此可以在一个block内高效地进行数据交换和共享,从而减少数据冗余和重复计算。
-
1.在优化后的transpose2函数中,交换坐标是为了实现矩阵转置的正确性。由于共享内存中的数据是以“行优先”方式存储的,而输出矩阵需要以“列优先”方式存储,因此在将共享内存中的数据写回到输出矩阵时,需要进行坐标的交换。具体来说,原始的输入矩阵在全局内存中是按照行优先的方式存储的,即以连续的行数据存储。而共享内存title中加载的数据也是以行优先的方式存储的,因为每个线程在加载数据时是按照每一行的数据块来加载的。在共享内存中,title[threadIdx.y][threadIdx.x]保存的就是inputdata[(y + threadIdx.y) * w + x + threadIdx.x]的值,其中threadIdx.y表示行索引偏移,threadIdx.x表示列索引偏移。但是,输出矩阵需要以列优先的方式存储,即以连续的列数据存储。因此,我们在写回输出矩阵时需要将共享内存中的行数据按列的方式重新排列。为了实现这个转置过程,我们交换了x和y的值,并且在写回输出矩阵时,通过outputdata[(y + i) * w + x]将共享内存中的行数据转置为输出矩阵的列数据。
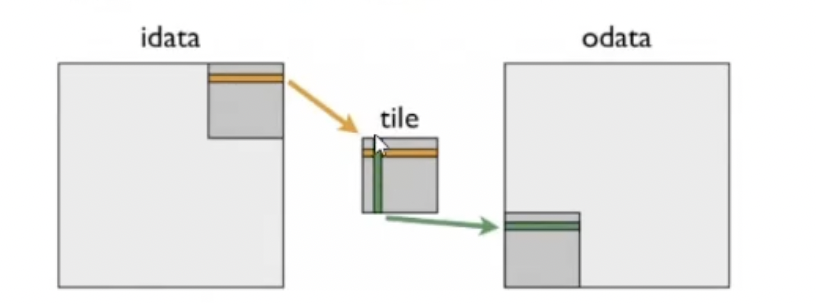
for each block in grid:
load data from global memory to shared memory (row-major order)
synchronize threads in the block
transpose data in shared memory (row-major to column-major)
write data back from shared memory to global memory (column-major order)
这样,通过对共享内存中的数据进行转置,就能够实现矩阵的正确转置操作。这种方式减少了全局内存的访问次数,并且通过共享内存的高速缓存和块内线程的并行计算,提高了整体矩阵转置的性能。
存储块冲突(bank confilict)
共享内存一共有32个存储块,且内存读写可以同时运行。当并行线程尝试访问同一存储块内的内存时,我们将这种情况称为存储块冲突,该冲突将导致操作的顺序化。
使用Padding避免存储体冲突,见下图:
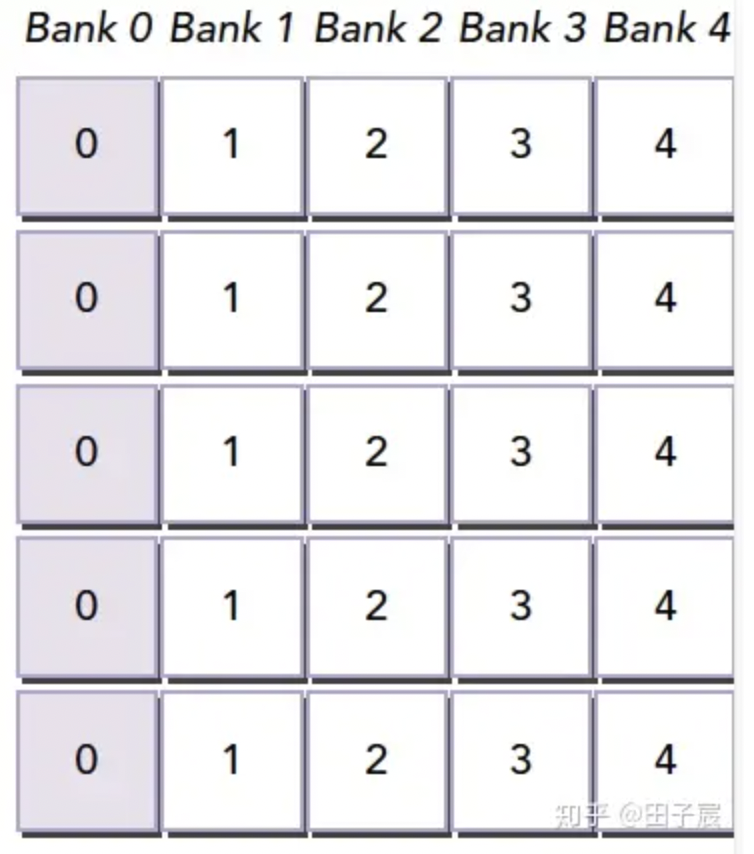
——>
 原来假设为4个bank,现在填充数组的时候多填充一位,但由于bank是按顺序读取,那么棕色的部分就会占位,但不会产生作用。所以Bank读取时不会产生冲突。
原来假设为4个bank,现在填充数组的时候多填充一位,但由于bank是按顺序读取,那么棕色的部分就会占位,但不会产生作用。所以Bank读取时不会产生冲突。
最后修改于 2023-08-01

本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。