VOC分割数据集制作
VOC格式的分割数据集的制作
VOC格式数据集制作
Labelme安装
一般来说,Labelme标图软件包比较通用,可以直接安装在anaconda的base环境,在Terminal或者anaconda prompt中输入:
|
|
如果安装不流畅,或者因为网络原因下载不下来可以换源:
- pip换源:加
-i https://pypi.tuna.tsinghua.edu.cn/simple, 这里加的清华源 - conda焕源:
1 2 3 4 5 6 7# 加的都是中科大的镜像源 conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/ conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/ conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/ conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
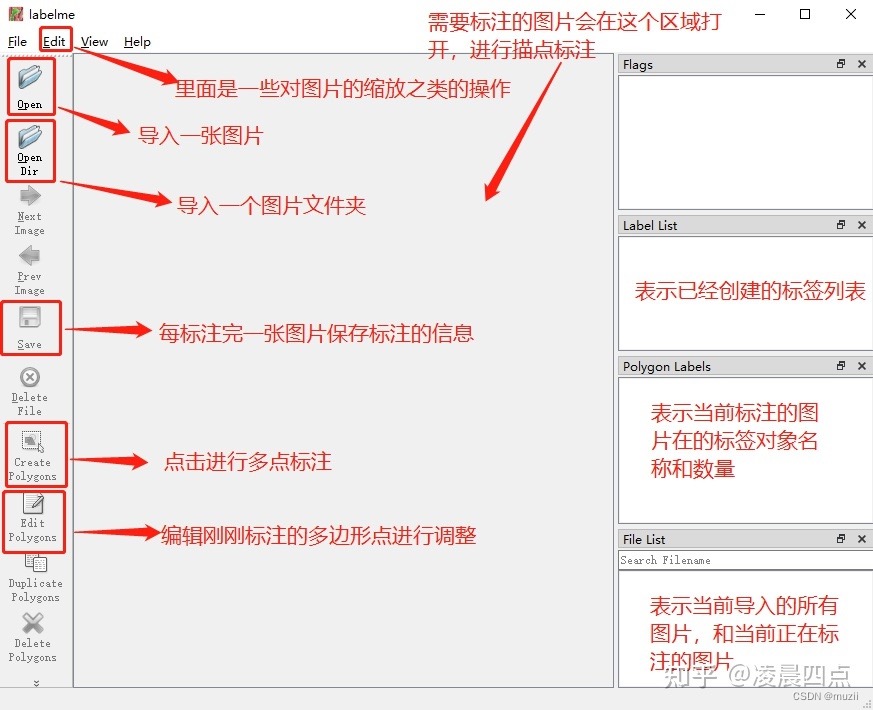
标图
放一张网上找的图:
json文件转标签
利用第三方Github库
Github地址(使用说明):https://github.com/veraposeidon/labelme2Datasets
利用脚本调用Labelme自带的工具
- 首先利用
ctrl+F或者搜索在anaconda文件夹中找到Labelme所在环境的json_to_dataset.py文件。 - 因为labelme无法提前知道我们标记的像素分类综述,所以需要修改其中的代码并保存:
|
|
- 编写脚本
json_to_data.py调用labelme,非常重要的事就是必须将包含json文件的文件夹重新复制一个样本来操作,防止脚本编写错误导致数据丢失:
|
|
- 编写脚本对转好的文件夹进行复制和转移操作:
|
|
- 通过上述操作,已经将原图和标签分别放入了
JPEG和PNG文件夹,然后按照以下布局将图片放好,以VOC2012的分割数据集格式进行举例:
-- Orange_Navel_1.5k
|
-- --VOC2007
|
-- -- -- ImageSets
|
-- -- -- -- Segmentation
-- -- -- JPEGImages
放原图
-- -- -- SegmentationClass
放标签
- 最后一步,编写脚本划分训练集和验证集(该脚本需要和Orange_Navel_1.5k在同一级别目录下):
|
|
运行之后就能在Segmentation文件夹下找到4个.txt文件,分别是test.txt、train.txt、trainval.txt、val.txt,记录了哪些图片是训练集,哪些图片是验证集。
制作完成
将文件夹压缩,并改名,数据集就制作完成了。
最后修改于 2023-03-02

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。