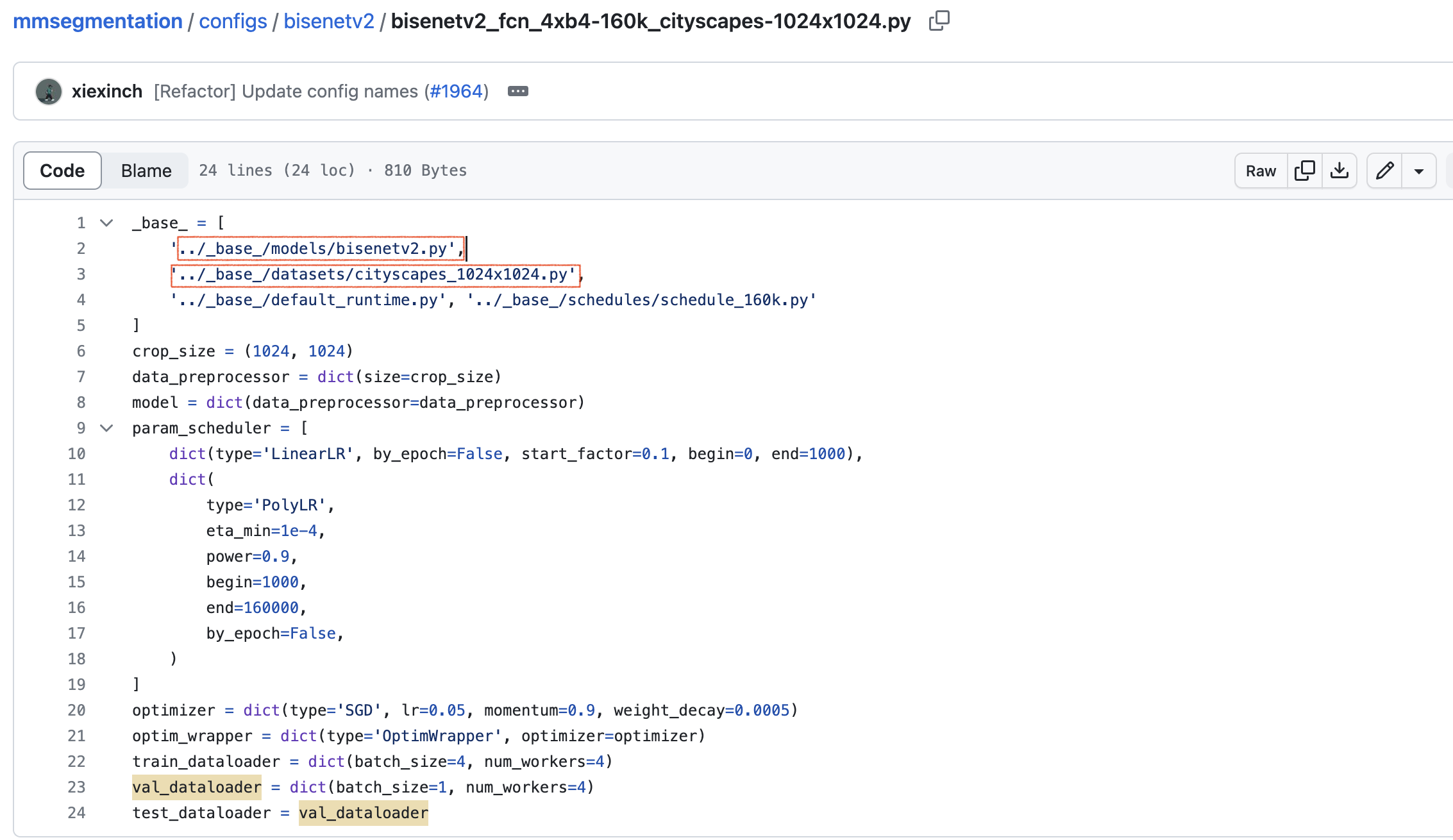
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
|
from matplotlib import colors as mcolors
import random
random.seed(124)
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive', 'tab:cyan', 'black', 'indianred', 'brown', 'firebrick', 'maroon', 'darkred', 'red', 'sienna', 'chocolate', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'forestgreen', 'limegreen', 'darkgreen', 'green', 'lime', 'seagreen', 'mediumseagreen', 'darkslategray', 'darkslategrey', 'teal', 'darkcyan', 'dodgerblue', 'navy', 'darkblue', 'mediumblue', 'blue', 'slateblue', 'darkslateblue', 'mediumslateblue', 'mediumpurple', 'rebeccapurple', 'blueviolet', 'indigo', 'darkorchid', 'darkviolet', 'mediumorchid', 'purple', 'darkmagenta', 'fuchsia', 'magenta', 'orchid', 'mediumvioletred', 'deeppink', 'hotpink']
markers = [".",",","o","v","^","<",">","1","2","3","4","8","s","p","P","*","h","H","+","x","X","D","d","|","_",0,1,2,3,4,5,6,7,8,9,10,11]
linestyle = ['--', '-.', '-']
def get_line_arg():
'''
随机产生一种绘图线型
'''
line_arg = {}
line_arg['color'] = random.choice(colors)
# line_arg['marker'] = random.choice(markers)
line_arg['linestyle'] = random.choice(linestyle)
line_arg['linewidth'] = random.randint(1, 4)
# line_arg['markersize'] = random.randint(3, 5)
return line_arg
import pandas as pd
import matplotlib.pyplot as plt
# 类别列表
class_list = ['background', 'red', 'green', 'white', 'seed-black', 'seed-white']
# 日志文件路径
log_path = './work_dirs/ZihaoDataset-PSPNet/20230818_210528/20230818_210528.log'
with open(log_path, 'r') as f:
logs = f.read()
## 定义正则表达式
import re
import numpy as np
def transform_table_line(raw):
raw = list(map(lambda x: x.split('|'), raw))
raw = list(map(
lambda row: list(map(
lambda col: float(col.strip()),
row
)),
raw
))
return raw
x = range(500, 40500, 500)
metrics_json = {}
for each_class in class_list: # 遍历每个类别
re_pattern = r'\s+{}.*?\|(.*)?\|'.format(each_class) # 定义该类别的正则表达式
metrics_json[each_class] = {}
metrics_json[each_class]['re_pattern'] = re.compile(re_pattern)
# 匹配
for each_class in class_list: # 遍历每个类别
find_string = re.findall(metrics_json[each_class]['re_pattern'], logs) # 粗匹配
find_string = transform_table_line(find_string) # 精匹配
metrics_json[each_class]['metrics'] = find_string
print(metrics_json.keys())
# dict_keys(['background', 'red', 'green', 'white', 'seed-black', 'seed-white'])
# 查看某一类别的评估指标 IoU Acc Dice Fscore Precision Recall
each_class = 'red'
each_class_metrics = np.array(metrics_json[each_class]['metrics'])
plt.figure(figsize=(16, 8))
for idx, each_metric in enumerate(['IoU', 'Acc', 'Dice', 'Fscore', 'Precision', 'Recall']):
try:
plt.plot(x, each_class_metrics[:,idx], label=each_metric, **get_line_arg())
except:
pass
plt.tick_params(labelsize=20)
plt.ylim([0, 100])
plt.xlabel('step', fontsize=20)
plt.ylabel('Metrics', fontsize=20)
plt.title('类别 {} 训练过程中,在测试集上的评估指标'.format(each_class), fontsize=25)
plt.legend(fontsize=20)
plt.savefig('图表/类别 {} 训练过程评估指标.pdf'.format(each_class), dpi=120, bbox_inches='tight')
plt.show()
# 注意x的元素个数,应和metrics_json[each_class]['metrics']元素个数一致,绘图才能成功
# 查看每个类别的评估指标 IoU Acc Dice Fscore Precision Recall
for each_class in class_list: # 遍历每个类别
each_class_metrics = np.array(metrics_json[each_class]['metrics'])
plt.figure(figsize=(16, 8))
for idx, each_metric in enumerate(['IoU', 'Acc', 'Dice', 'Fscore', 'Precision', 'Recall']):
try:
plt.plot(x, each_class_metrics[:,idx], label=each_metric, **get_line_arg())
except:
pass
plt.tick_params(labelsize=20)
plt.ylim([0, 100])
plt.xlabel('step', fontsize=20)
plt.ylabel('Metrics', fontsize=20)
plt.title('图表/类别 {} 训练过程中,在测试集上的评估指标'.format(each_class), fontsize=25)
plt.legend(fontsize=20)
# plt.savefig('类别 {} 训练过程评估指标.pdf'.format(each_class), dpi=120, bbox_inches='tight')
plt.show()
|