分割模型量化技术
本文主要介绍的内容如下:
- 提高网络推理效率的基本技术
- 轻量化实时分割网络常用的架构
- 知识蒸馏
文中涉及的部分代码全部使用Pytorch框架实现。
本文的大部分内容来自于综述文章(On Efficient Real-Time Semantic Segmentation: A Survey)
提高网络推理效率的基本技术
本节将从以下几个方面来介绍:
- 采样技术
- 高效卷积技术
- 残差连接/跳过连接
- 轻量化骨干网络
采样技术
采样技术是减少推理延迟最常用的手段,采样分为上采样和下采样。
下采样可以用来降低图像的分辨率,在大型网络中广泛使用,来增加深层卷积核的接受场。通常在网络早期对图像进行下采样可以显著减少网络的推理延迟,在深层网络进行下采样也可以更好地提取高分辨率的细节。
常用的下采样方式有两种,一是使用最大池化层,二是使用步进卷积:
- 最大池化将图像分为若干个池化子区域,在每个区域中取最大的像素值。
- 步进卷积则通过调整步幅大小来调整图片的大小: 根据输入图像的大小$W\times W$,卷积核的大小$F\times F$,步长$S$,填充的数量$P$来计算输出图像的大小
$$W_{out} = \lvert\frac{W - F + 2P}{S}\rvert+1$$
|
|
上采样的主要目的是为了重建输入分辨率的图像,上采样的方法主要有三种:
- 最近邻插值
- 双线性插值
- 转置卷积
从上到下计算代价越来越贵,采样效果也越来越好。
|
|
高效卷积技术
高效卷积技术通常是标准卷积的变体,使得在相同参数量的情况下计算量更小,卷积网络中通常使用的高效卷积有5种:
- 深度可分离卷积
- 分组卷积
- 非对称卷积
- 瓶颈块
- 空洞/扩张卷积
深度可分离卷积是由深度卷积和逐点卷积组合而成,逐点卷积也叫$1\times 1$卷积。我们可以使用标准卷积做一个对比来理解。
标准$3\times 3$卷积
深度可分离卷积 = 深度卷积 + $1\times 1$卷积

分组卷积的原理是将输入和输出通道拆分为g组,输出滤波器仅应用于属于相应组的输入通道,参数量和操作都减少了g倍。分组卷积的一个缺点是组与组之前缺陷信息共享,CVPR 2018 paper(ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices)通过通道洗牌操作解决了这个问题。
分组卷积

非对称卷积或叫分解卷积,将$k\times k$卷积重构为$k\times 1$和$1\times k$卷积。
非对称卷积

瓶颈块最初来自于CVPR 2016 paper(Deep Residual Learning for Image Recognition),在模块的输入使用$1\times 1$卷积来减少特征映射通道的数量,中间使用大尺寸的卷积和大量的特征通道进行计算,在模块的输出又使用$1\times 1$卷积来减少特通道的数量。
瓶颈块

扩张卷积最初来自于CVPR 2015 paper(Modeling Local and Global Deformations in Deep Learning: Epitomic Convolution),其通过在更大的输入窗口上稀疏应用权重内核,在不增加内核大小的情况下启用更大的接收场,其使用膨胀率d决定稀疏应用的程度。
扩张卷积

下表展示了它们的计算量:

实现代码如下:
|
|
残差连接/跳过连接
剩余连接和跳过连接允许网络中的数据绕过某些操作,有多种用途。第一种就是改善反向传播期间的梯度流,最典型的是在CVPR 2016 paper(Deep Residual Learning for Image Recognition)提出的残差瓶颈块,使网络的结构能够更深而提高性能;第二种就是对分割网络早期特征的重用,最典型的是在MICCAI 2015 paper(U-Net: Convolutional Networks for Biomedical Image Segmentation)提出的skip connection,将早期提取的特征用于上采样阶段的图像重建。
轻量化骨干网络
随着CNN的发展,网络的深度越来越大,参数量越来越大,但这在实际的应用中是不现实的。骨干网络是由分类网络去掉分类头实现的,一般用于对大型数据的预训练(ImageNet-1k),本地的分割网络则载入预训练得到的参数,用于加速网络的训练和解决分割数据集不足问题的瓶颈。
常用的CNN轻量化骨干网络有ResNet系列,Shufflenet系列,Mobilenet系列(V1,V2),EfficientNet系列。
但随着近年来transformer的出现,超大型网络超过了传统的CNN网络,同样的也生出了较为轻量的transformer轻量化骨干网络。
-
CVPR 2022 paper(MetaFormer is Actually What You Need for Vision):提出了Poolformer的结构,只使用了池化和通道MLP,抛弃了大型transformer网络中的自注意力结构,一共提供了5个不同大小的骨干网络(
S12,S24,S36,M36,M48),注意的是S系列在不同stage输出的通道数都为[64, 128, 320, 512], M系列在不同stage输出的通道数都为[96, 192, 384, 768],不同的每个stage的block数量。
-
NeurIPS 2022 paper(EfficientFormer: Vision Transformers at MobileNet Speed):提出了EfficientFormer的结构,在网络的早期(前2.5个stage)使用了池化和逐点卷积,在网络后期(后1.5个stage)使用传统的自注意力Transformer Block,一共提供了三个不同大小的骨干网络(
L1,L2,L3),这里的三个版本在不同的stage的通道数和block数量都不同。 实现了在延迟比较低的情况下,依旧具有较高的分类性能,并且在下游检测任务(COCO2017)和分割任务(ADE20K)上也超过了PoolFormer!
实现了在延迟比较低的情况下,依旧具有较高的分类性能,并且在下游检测任务(COCO2017)和分割任务(ADE20K)上也超过了PoolFormer!


-
arxiv preprint 2022年底(估计2023年被某个顶会录用) paper(Rethinking Vision Transformers for MobileNet Size and Speed)同年,该作者又对自己的网络进行了改进提出了EfficientFormerV2,以更小的计算代价达到了先前的分类性能,提供了4个版本(
S0,S1,S2,L)。

轻量化实时分割网络
轻量化分割网络主要有四种架构:
- 编码器和解码器架构
- 多分支架构
- 元学习
- 快速注意力机制
编码器和解码器架构
-
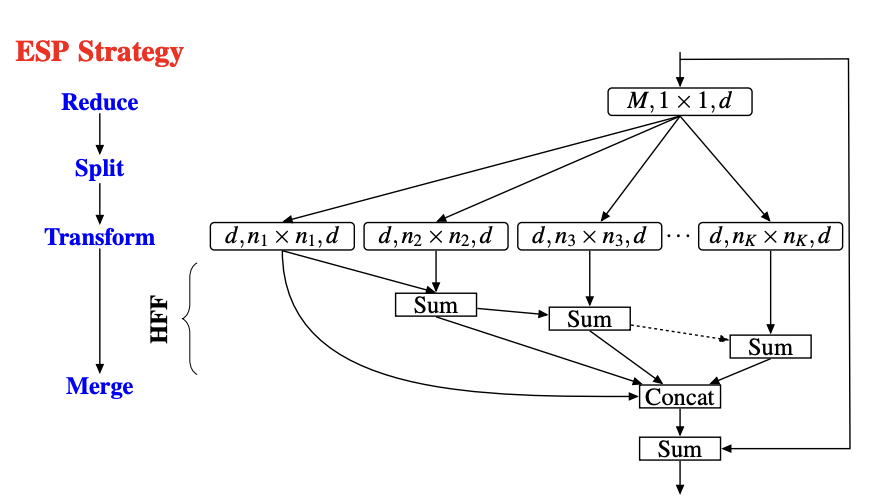
ECCV 2018 paper(ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation):ESPNet提出了高效的金字塔模块,使用$1\times 1$卷积来减少输入维度,然后使用具有不同膨胀率的并行卷积来增加接收场。为了避免因不同膨胀率而导致的网格工件,输出按层次求和,结果串联,最后通过剩余连接添加到输入中。
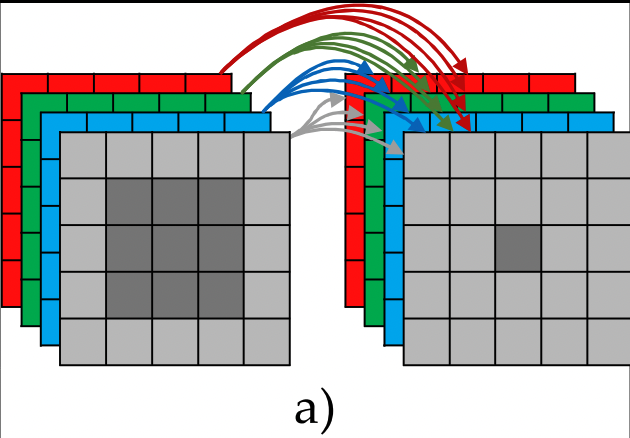
 ESPNet整体结构如下,其整体结构与UNet相似。在网络的早期使用极少滤波器的卷积层下采样,并使用相同尺寸的图像进行拼接,然后通过skip connection来重建分辨率。
ESPNet整体结构如下,其整体结构与UNet相似。在网络的早期使用极少滤波器的卷积层下采样,并使用相同尺寸的图像进行拼接,然后通过skip connection来重建分辨率。

-
VCIP 2017 paper(LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation):LinkNet同样使用标准的编码器和解码器架构,不过参数量相较UNet少了很多,以ResNet-18作为骨干网络。

-
CVPR 2019 paper(In Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images):首先改文章结合UNet和PSPNet的结构,再通过选取较为轻量的骨干网络以及简化上采样的步骤,组合出了一个基础模型SwiftNetRN-18。
 为了增加接收场,该作者取消了金字塔的模块并使用班分辨率的特征提取达到了比金字塔池化模块更好的效果。并证明了小模型在数据量足够的情况下,从头开始训练也能达到预训练的效果。
为了增加接收场,该作者取消了金字塔的模块并使用班分辨率的特征提取达到了比金字塔池化模块更好的效果。并证明了小模型在数据量足够的情况下,从头开始训练也能达到预训练的效果。

-
arxiv 2019 paper(Fast-SCNN: Fast Semantic Segmentation Network):Fast-SCNN网络结构结合了双分支网络和多分辨率输入的两种网络的特点,在特征提取的中间阶段分为两个分支,这样双分支共享特征提取前期的权重。一个分支提取局部信息,另一个分支提取全局特征,最后直接进行双线性插值恢复输入分辨率。注意在特征提取前期使用普通卷积,在通道数较多时使用深度可分离卷积和瓶颈块来减少计算量。

多分支架构
-
ECCV 2018 paper(ICNet for Real-Time Semantic Segmentation on High-Resolution Images):ICNet首先通过低分辨率图像首先通过完整的语义感知网络,以获得粗略的预测地图。然后提出了级联特征融合单元和级联标签引导策略,以整合中高分辨率特征,从而逐步细化粗糙的语义图。
 从图中可以看出,在图像较小时采用多次卷积并使用较大的深度,大尺寸的图像则则将卷积的stage减少,使用低分辨率监督的结果放入更高的分辨率进行fusion。
从图中可以看出,在图像较小时采用多次卷积并使用较大的深度,大尺寸的图像则则将卷积的stage减少,使用低分辨率监督的结果放入更高的分辨率进行fusion。 -
arxiv 2018 paper(Contextnet: Exploring context and detail for semantic segmentation in real-time):其提出的ContextNet以两个分支结合为基础,一个分支输入全分辨率,提取空间特征,另一个分支为小分辨率的输入,提取局部特征。其中使用的瓶颈块和深度可分离卷积结构与Fast-SCNN类似,Fast—SCNN也是改进自此网络,将低分辨率的输入直接变为特征提取的低分辨率特征,这样既可以重用特征提取参数,又可以更好提取语义信息。

“元学习”技术
“元学习”并不是一个专有名词,这里用来泛指所学函数直接影响手头任务所用架构的技术。实时语义分割领域的大多数元学习示例都属于神经架构搜索(NAS)的范畴,这是一种自动化设计神经网络架构过程的方法。
- arxiv 2020 paper(Fasterseg: Searching for faster real-time semantic segmentation):FasterSeg使用基于强化学习的神经搜索架构(NAS),在保持下采样8倍的主干不变的同时,对网络的其余结构进行自动搜索,生成FastSeg模型。
 通过最后的网络搜索,形成了一个多分支结合的网络,并且在网络的后期使用了大量的缩放卷积。
通过最后的网络搜索,形成了一个多分支结合的网络,并且在网络的后期使用了大量的缩放卷积。

快速注意力机制
- IEEE Robotics and Automation Letters(二区) 2021 paper(Real-time Semantic Segmentation with Fast Attention):FANet的网络是基于编码器和解码器架构的,其结构相似于UNet,它在skip connection之前加入了一个快速注意力机制,极少量地增加计算量。它使用了ResNet-18和ResNet-34的骨干网络创立了两个版本FANet-18和FANet-34两个版本。

知识蒸馏
本节内容主要介绍知识蒸馏的类型,原理,方式,最后会介绍一两种具体的蒸馏方法。
本节内容大部分基于来自于综述文章(Knowledge Distillation: A Survey)
知识蒸馏最重要的就是知识,这里的知识其实就是数据的目标分布。早期的知识蒸馏技术里,student学习的是teacher的logits(对于分类任务而言,一般将进softmax之前的scores叫做logits,softmax输出的概率分布叫soft labels,当然了,后者也有叫logits的)。
 后来为了改善知识蒸馏的效果,各路大佬开始花式开发各种特征用于学习,整体大致可以分为三类,
后来为了改善知识蒸馏的效果,各路大佬开始花式开发各种特征用于学习,整体大致可以分为三类,基于响应的知识(response-based knowledge), 基于特征的知识(feature-based knowledge)和基于关系的蒸馏(relation-based knowledge)。
基于响应的知识
响应一般是指教师模型的最后一层的响应,其主要思想是让学生模仿老师的预测。分类任务里最常用的基于响应的知识就是软标签,即softmax输出的概率分布,一般使用KL发散作为损失函数,公式如下:
$$p(z_i, T) = \frac{\text{exp}(z_i/T)}{\sum_{j}\text{exp}(z_j/T)}$$

基于特征的知识
基于特征的知识其实就是中间层的输出,自从2015年的Fitnets之后,出现了很多花式利用各种中间层特征进行蒸馏的研究。这里重点提一下中间层匹配涉及到的一个层间匹配问题,对于离线蒸馏而言,student可能层数会小一些,如何将teacher的层与student的层进行对应或匹配就是个关键问题。大多数情况下,层间匹配只能靠经验或者实验。另外,中间层的特征维度可能会不匹配,需要根据情况进行投影或者说变换。

基于关系的知识
这种知识一般是指的是图形知识,它表示在任意两个特征图之间的数据内关系,通常使用特征图之间的相似度计算来衡量。

蒸馏方法
知识蒸馏的方法可以分为离线蒸馏,在线蒸馏和自蒸馏三种。

-
离线蒸馏:从图中可以看出,离线蒸馏的第一步就是选取一个性能表现较好的模型在数据集上预训练。第二步将训练好之后的权值在学生训练阶段载入,并锁定参数,只在特征输出和结果输出上让学生模型学习其数据分布,学生模型出了学习标签提供的数据分布还要学习老师模型处理数据的方法。需要注意的是在学生模型训练的时候,教师模型必须使用验证模式并锁定特征输出部分的权值,防止蒸馏损失函数对教师模型的反向传播。**如果学生模型既要使用骨干网络预训练,又要使用知识蒸馏(特别是特征蒸馏),需要先锁住预训练权重锁住训练一会儿再解开,防止早期过多损失的反向传播破坏了预训练的效果。**由于离线蒸馏比较容易实现,大多数蒸馏都采用这种方式。
-
在线蒸馏:顾名思义,就是学生和老师同时开始从头训练,也可以有额外骨干网络预训练的帮助。但是这种训练方式会带来很多的问题,比如模型大小不一,学生和老师的训练速度不同。又比如学生和老师的模型同时载入,还需要计算特征图之间的关系损失,这会使GPU的内存负担变得非常大。还有可能存在的问题是学生网络和教师网络结构差距较大,学生学习了教师早期的知识,并陷入了一个局部分布变得难以训练。由于这种方式训练难度较大,所以相关的工作比较少。
-
自蒸馏:自蒸馏就是自己又是老师又是学生,这就比较励志了😄。常见的方式就是网络的低层学习高层,后期学习前期等。相当于一个人经历了许多,改掉了以前自己的坏毛病亦或是一个人在后期发现了早期经历了却没有悟出的道理!(自己瞎扯,🐶保命)
知识蒸馏论文解读
-
CVPR 2019 paper(Knowledge Adaptation for Efficient Semantic Segmentation):该文提出了一种知识适应的方法,教师网络和学生网络是独立的,蒸馏的位置在两个网络的输出位置。第一步,教师网络通过自动编码器将知识压缩为紧凑的格式来让学生学习。第二步,学生网络通过
Feature Adapter来捕获教师网络的远程依赖关系。
-
CVPR 2019 paper(A Comprehensive Overhaul of Feature Distillation):该文使用的是知识蒸馏中的特征蒸馏方法。首先介绍了特征蒸馏的一般范式:根据不同的特征蒸馏方法,改变教师变换T,学生变换S,教师与学生的距离d。
 该文设计了与其他论文的不同的教师变换,学生变换,距离函数,以及改变了蒸馏特征的位置。
该文设计了与其他论文的不同的教师变换,学生变换,距离函数,以及改变了蒸馏特征的位置。-
教师变换:Margin ReLU $$\sigma_m(x) = \text{max}(x, m)$$

-
学生变换:$1\times 1$卷积
-
蒸馏的损失函数:将老师与学生的距离作为损失函数,并将
partial L2距离函数对教师转换和学生转换做蒸馏。 $$L_{distill}=d_p(\sigma_{m_c}(F_t),r(F_s))$$ $$d_p(T,S)=\sum_i^{W HC}\left{\begin{matrix}0,\quad \text{if}\quad S_i\leqslant T_i \leqslant 0\(T_i-S_i)^2\quad \text{otherwise}\end{matrix}\right.$$ -
特征蒸馏的具体位置:该文认为如果在卷积后面跟着的BN和ReLU之后做特征蒸馏,会损失部分从老师的特征分布带过来的信息。所以他们将进行蒸馏的位置改变到了每个stage的末尾卷积后和ReLU激活函数前。因为使用离线蒸馏,教师模型的参数是最优目标分布,参数是不动的,且载入GPU时使用验证模式,所以Batch Normalization可以忽略。

-
-
CVPR 2019 paper(Structured Knowledge Distillation for Semantic Segmentation):本文专门针对语义分割网络提出了解决方案,结合特征蒸馏,输出像素蒸馏,对抗性学习蒸馏组成了一个结构化蒸馏的方法。

- 基于关系的特征蒸馏:该文章提出了一种计算特征图相似度的
Pair-wise loss,首先通过池化来控制特征图输出的大小,然后计算特征图之间的相似度来计算损失。 $$l_{pa}(S)=\frac{1}{(W^{’}\times H^{’})^2}\sum_{i\varepsilon R}\sum_{j\varepsilon R}(a_{ij}^s-a_{ij}^t)^2$$ 其中$a_{ij}$代表两个像素之间的相似性, $$a_{ij}=f_i^{\top}f_j/(|f_i |_2|f_j |_2 )$$ 实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36def similarity(feat): feat = feat.float() tmp = L2(feat).detach() feat = feat/tmp feat = feat.reshape(feat.shape[0],feat.shape[1],-1) return torch.einsum('icm,icn->imn', [feat, feat]) def sim_dis_compute(f_S, f_T): sim_err = ((similarity(f_T) - similarity(f_S))**2)/((f_T.shape[-1]*f_T.shape[-2])**2)/f_T.shape[0] sim_dis = sim_err.sum() return sim_dis # pairwise feature loss class CriterionPairWiseforWholeFeatAfterPool(nn.Module): def __init__(self, scale, feat_ind): """ inter pair-wise loss from inter feature maps scale 代表最大池化层的子区域占原特征图大小的比例。 比如2*2的子区域,特诊图大小为56*56,scale就应该等于28/56。 """ super(CriterionPairWiseforWholeFeatAfterPool, self).__init__() self.criterion = sim_dis_compute self.feat_ind = feat_ind self.scale = scale def forward(self, preds_S, preds_T): feat_S = preds_S[self.feat_ind] feat_T = preds_T[self.feat_ind] feat_T.detach() total_w, total_h = feat_T.shape[2], feat_T.shape[3] patch_w, patch_h = int(total_w*self.scale), int(total_h*self.scale) maxpool = nn.MaxPool2d(kernel_size=(patch_w, patch_h), stride=(patch_w, patch_h), padding=0, ceil_mode=True) # change loss = self.criterion(maxpool(feat_S), maxpool(feat_T)) return loss- 输出像素蒸馏:
Pixel-wise Loss借鉴了图像分类任务中使用的软标签的方法,使用教师模型产生的类改成来作为训练学生模型的软目标。 $$l_{pi}(S) = \frac{1}{W^{’}\times H^{’}}\sum_{i\varepsilon R}\text{KL}(q_i^s|q_i^t)$$ 其中$\text{KL}$代表两个概率之间的Kullback-Leibler发散。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20# Pixel loss class CriterionPixelWise(nn.Module): """ reduce参数是计算CE loss每个mini batch的和平均 """ def __init__(self, ignore_index=255, use_weight=True, reduce=True): super(CriterionPixelWise, self).__init__() self.ignore_index = ignore_index self.criterion = torch.nn.CrossEntropyLoss(ignore_index=ignore_index, reduce=reduce) if not reduce: print("disabled the reduce.") def forward(self, preds_S, preds_T): preds_T.detach() assert preds_S.shape == preds_T.shape,'the output dim of teacher and student differ' N,C,W,H = preds_S.shape softmax_pred_T = F.softmax(preds_T.permute(0,2,3,1).contiguous().view(-1,C), dim=1) logsoftmax = nn.LogSoftmax(dim=1) loss = (torch.sum( - softmax_pred_T * logsoftmax(preds_S.permute(0,2,3,1).contiguous().view(-1,C))))/W/H return loss- 对抗性学习蒸馏:
Holistic distillation采用条件生成对抗学习来制定整体蒸馏问题。紧凑型网被视为以输入RGB图像I为条件的生成器,而预测的分割图$Q^s$被视为假样本。我们预计$Q^s$与$Q^t$相似,$Q^t$是教师预测的分割图,并尽可能被视为真实样本。Wasserstein distance用于评估真实分布和假分布之间的差异,写成如下: $$l_{ho}(S,D) = E_{Q^s\sim p_s(Q^s)}[D(Q^s|I)] - E_{Q^t\sim p_t(Q^t)}[D(Q^t|I)]$$ 其中$E$是期望运算符,$D$是嵌入网络,作为GAN中的鉴别器,将Q和I一起投影成整体嵌入分数。梯度惩罚满足了利普希茨的要求。
- 基于关系的特征蒸馏:该文章提出了一种计算特征图相似度的
所以结构化蒸馏的损失函数为: $$l(S,D) = l_{mc}(S) + \lambda_1(l_{pi}(S) + l_{pa}(S)) - \lambda_2l_{ho}(S,D)$$ 其中$pi$代表输出像素损失,$pa$代表成对特征相似度损失,$ho$代表对抗性学习蒸馏损失。总体的训练被分为两步:
1.训练GAN鉴别器,训练鉴别器等同于最小化$ho$损失,为学生网络的假样本提供低嵌入分数。
2.训练紧凑分割网络,最大限度减少与与紧凑分割网络相关的多类交叉熵损失和蒸馏损失。
- arxiv 2022 paper(Normalized Feature Distillation for Semantic Segmentation):该文通过对先前特征蒸馏的方法进行思考,认为虽然对学生和老师的特征不进行转换不能使学生的特征分布与老师相似(下图的b中的Navie代表与没有进行转换的蒸馏中学生模型的特征分布和老师模型特征的CKA相似性),但认为注意力图,格拉米矩阵和成对相似性等转换方法都是知识损失的,所以他们提出了一种简单的归一化特征蒸馏,具体的特征损失函数如下:
 $$L_{nfd} = D(Norm(F_t), Norm(F_s))$$
其中$Norm$代表归一化,$D$代表$L_2$距离:
$$\hat{F} = \frac{1}{\sigma}(F-u)$$
$u$和$\sigma$分别代表特征的均值和标准差。
$$L_{nfd} = D(Norm(F_t), Norm(F_s))$$
其中$Norm$代表归一化,$D$代表$L_2$距离:
$$\hat{F} = \frac{1}{\sigma}(F-u)$$
$u$和$\sigma$分别代表特征的均值和标准差。
最后它的总损失表达式如下: $$L = L_{gt} + \lambda_1L_{kd} + \lambda_2L_{nfd}$$ 其中$\lambda_1$设为10和$\lambda_2$设为0.7。
最后在实验结果和消融实验部分,蒸馏的提升到了之前没有的高度,也证明了在(W,H)维度进行归一化蒸馏的效果是最好的。(SKD即是上一篇文章Structured Knowledge Distillation for Semantic Segmentation)


最后修改于 2023-03-21

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。