亚信图像算法实习笔记
授权书区域识别项目:2023.7.24~2023.8.20
修改Linux服务器文件权限问题
- 给文件所有者和同组用户赋予读写权限,其他用户只有读权限:
1
|
$ chmod -R 755 directory
|
请注意,修改文件或目录的权限需要有足够的权限进行操作。只有文件或目录的所有者或超级用户(root)才能更改权限。
Docker配置深度学习环境
第一步,安装Docker
- 如果没有安装docker,则使用官方提供的脚本进行安装:
1
|
$ curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
|
Docker镜像加速
- 在
/etc/docker/daemon.json中写入如下内容,如果没有该文件则新建:
1
|
{"registry-mirrors":["https://XXX.mirror.aliyuncs.com/"]}
|
1
2
|
$ sudo systemctl daemon-reload
$ sudo systemctl restart docker
|
从Docker Hub下载镜像
- 进入Docker Hub,因为我使用的是pytorch的训练框架,搜索
torch1.9.0-cuda11.1-cudnn8
- 点击左边的
tags,复制拉取镜像的脚本,在服务器的命令行上运行
运行Docker容器
1
|
$ docker run -it mindest/torch1.9.0-cuda11.1-cudnn8:bevt /bin/bash
|
参数说明:
-i:交互式操作
-t:终端
mindest/torch1.9.0-cuda11.1-cudnn8:bevt:镜像名称:镜像标签
bin/bash:放在镜像后面的是命令,这里我们希望有个交互式 Shell,因此用的是bin/bash。/bin/bash的作用是表示载入容器后运行bash ,docker中必须要保持一个进程的运行,要不然整个容器启动后就会马上kill itself,这个/bin/bash就表示启动容器后启动bash。
在容器内安装所需要的包,并更新镜像
- 安装需要的包,直接使用
pip install和conda install
- 更新镜像:容器是动态的,镜像是静态的。我们在容器里更新了Python包,为了以后可以持久地使用,还需要使用
commit将容器打包为镜像。
1
|
$ docker commit -m="update packages" -a="XXX" bb8967093b48 XXX/torch1.9.0-cuda11.1-cudnn8:bevt
|
各个参数说明:
-m: 提交的描述信息-a: 指定镜像作者bb8967093b48:容器 IDXXX/mypymarl:v1: 指定要创建的目标镜像名(作者名/镜像名:标签)
在本地使用容器运行代码
- 首先我们需要创建一个本地的Ubuntu系统和docker容器共享的文件夹:
1
2
|
$ sudo mkdir /data
$ sudo docker run -v /data:/data -itd caixj/pytorch:v1
|
1
|
$ docker attach 500ad76de1cf
|
安装nvdia-cuda
Docker 默认是不支持在容器内 GPU 加速的,NVIDIA 官方做了个工具箱来支持容器内 GPU 加速运算,这大大方便了深度学习开发者。这里直接根据官方教程安装即可。
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
安装完nvidia-cuda之后,再创建容器时加上--gpus all,即可在容器内调用cuda,即
1
|
$ sudo docker run -v /data:/data -itd --gpus all caixj/pytorch:v1 /bin/bash
|
然后跟上述步骤相同,进入容器,然后运行代码就ok。
1
2
3
|
$ docker save -o <your_file_name.tar> <image id>
# 根据测试的反馈来说,最好不用image id进行save
$ docker save -o <your_file_name.tar> <image name:version>
|
1
2
3
4
|
$ docker load < your_file.tar.gz
# 或者
$ docker load --input your_file.tar
# 它的images的名字会变为your_file:latest
|
1
|
$ docker exec -it 容器id /bin/bash
|
- 使用
docker exec命令进入容器后,再使用exit命令退出容器,容器仍将保持运行,而docker attach进入使用exit退出后容器会停止运行
Docker常用命令
1
|
docker search XXX/image
|
1
|
docker pull XXX/images:tag
|
1
|
docker rmi XXX/images:ta
|
1
|
docker run -it image:tag /bin/bash
|
1
|
docker attach container_ID
|
1
|
docker start container_ID
|
1
|
docker stop container_ID
|
1
|
docker restart container_I
|
1
|
docker rm [container id]
|
1
|
docker system prune --force --all --volumes
|
目标检测检测框原理
YOLOv4检测头原理
检测头由一个常规的$3\times 3$卷积接上一个$1\times 1$卷积组成。假设输入图像为$416\times 416$,最后得到的特征图的大小为(B, 75, 26, 26),这里的分类数为20。
那么通道数75是如何得到的呢?
75 = 3 * (5 + 分类数) = 3 * (4 + 1 + 20)= 75
在$26\times 26$的特征层中,会预先标定三个先验框,YOLOv4网络的预测结果只会判定先验框内部是否包含物体和这个物体的种类以及对先验框进行调整,获得一个新的预测框。
所以上面的3代表每一个特征图上的三个先验框。4 + 1中的4代表了先验框的调整参数,1的内容代表先验框内部是否包含物体,num_classes个通道分别代表属于该类的概率。
先验框详解与解码
先看先验框的解码代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
|
class DecodeBox():
def __init__(self, anchors, num_classes, input_shape, anchors_mask = [[6,7,8], [3,4,5], [0,1,2]]):
super(DecodeBox, self).__init__()
self.anchors = anchors
self.num_classes = num_classes
self.bbox_attrs = 5 + num_classes
self.input_shape = input_shape
#-----------------------------------------------------------#
# 13x13的特征层对应的anchor是[81,82],[135,169],[344,319]
# 26x26的特征层对应的anchor是[10,14],[23,27],[37,58]
#-----------------------------------------------------------#
self.anchors_mask = anchors_mask
def decode_box(self, inputs):
outputs = []
for i, input in enumerate(inputs):
#-----------------------------------------------#
# 输入的input一共有三个,他们的shape分别是
# batch_size, 255, 13, 13
# batch_size, 255, 26, 26
#-----------------------------------------------#
batch_size = input.size(0)
input_height = input.size(2)
input_width = input.size(3)
#-----------------------------------------------#
# 输入为416x416时
# stride_h = stride_w = 32、16、8
#-----------------------------------------------#
stride_h = self.input_shape[0] / input_height
stride_w = self.input_shape[1] / input_width
#-------------------------------------------------#
# 此时获得的scaled_anchors大小是相对于特征层的
#-------------------------------------------------#
scaled_anchors = [(anchor_width / stride_w, anchor_height / stride_h) for anchor_width, anchor_height in self.anchors[self.anchors_mask[i]]]
#-----------------------------------------------#
# 输入的input一共有三个,他们的shape分别是
# batch_size, 3, 13, 13, 85
# batch_size, 3, 26, 26, 85
#-----------------------------------------------#
prediction = input.view(batch_size, len(self.anchors_mask[i]),
self.bbox_attrs, input_height, input_width).permute(0, 1, 3, 4, 2).contiguous()
#-----------------------------------------------#
# 先验框的中心位置的调整参数
#-----------------------------------------------#
x = torch.sigmoid(prediction[..., 0])
y = torch.sigmoid(prediction[..., 1])
#-----------------------------------------------#
# 先验框的宽高调整参数
#-----------------------------------------------#
w = prediction[..., 2]
h = prediction[..., 3]
#-----------------------------------------------#
# 获得置信度,是否有物体
#-----------------------------------------------#
conf = torch.sigmoid(prediction[..., 4])
#-----------------------------------------------#
# 种类置信度
#-----------------------------------------------#
pred_cls = torch.sigmoid(prediction[..., 5:])
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
#----------------------------------------------------------#
# 生成网格,先验框中心,网格左上角
# batch_size,3,13,13
#----------------------------------------------------------#
grid_x = torch.linspace(0, input_width - 1, input_width).repeat(input_height, 1).repeat(
batch_size * len(self.anchors_mask[i]), 1, 1).view(x.shape).type(FloatTensor)
grid_y = torch.linspace(0, input_height - 1, input_height).repeat(input_width, 1).t().repeat(
batch_size * len(self.anchors_mask[i]), 1, 1).view(y.shape).type(FloatTensor)
#----------------------------------------------------------#
# 按照网格格式生成先验框的宽高
# batch_size,3,13,13
#----------------------------------------------------------#
anchor_w = FloatTensor(scaled_anchors).index_select(1, LongTensor([0]))
anchor_h = FloatTensor(scaled_anchors).index_select(1, LongTensor([1]))
anchor_w = anchor_w.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(w.shape)
anchor_h = anchor_h.repeat(batch_size, 1).repeat(1, 1, input_height * input_width).view(h.shape)
#----------------------------------------------------------#
# 利用预测结果对先验框进行调整
# 首先调整先验框的中心,从先验框中心向右下角偏移
# 再调整先验框的宽高。
#----------------------------------------------------------#
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x.data + grid_x
pred_boxes[..., 1] = y.data + grid_y
pred_boxes[..., 2] = torch.exp(w.data) * anchor_w
pred_boxes[..., 3] = torch.exp(h.data) * anchor_h
#----------------------------------------------------------#
# 将输出结果归一化成小数的形式
#----------------------------------------------------------#
_scale = torch.Tensor([input_width, input_height, input_width, input_height]).type(FloatTensor)
output = torch.cat((pred_boxes.view(batch_size, -1, 4) / _scale,
conf.view(batch_size, -1, 1), pred_cls.view(batch_size, -1, self.num_classes)), -1)
outputs.append(output.data)
return outputs
|
下面展示了一个具体图片的先验框调整过程:
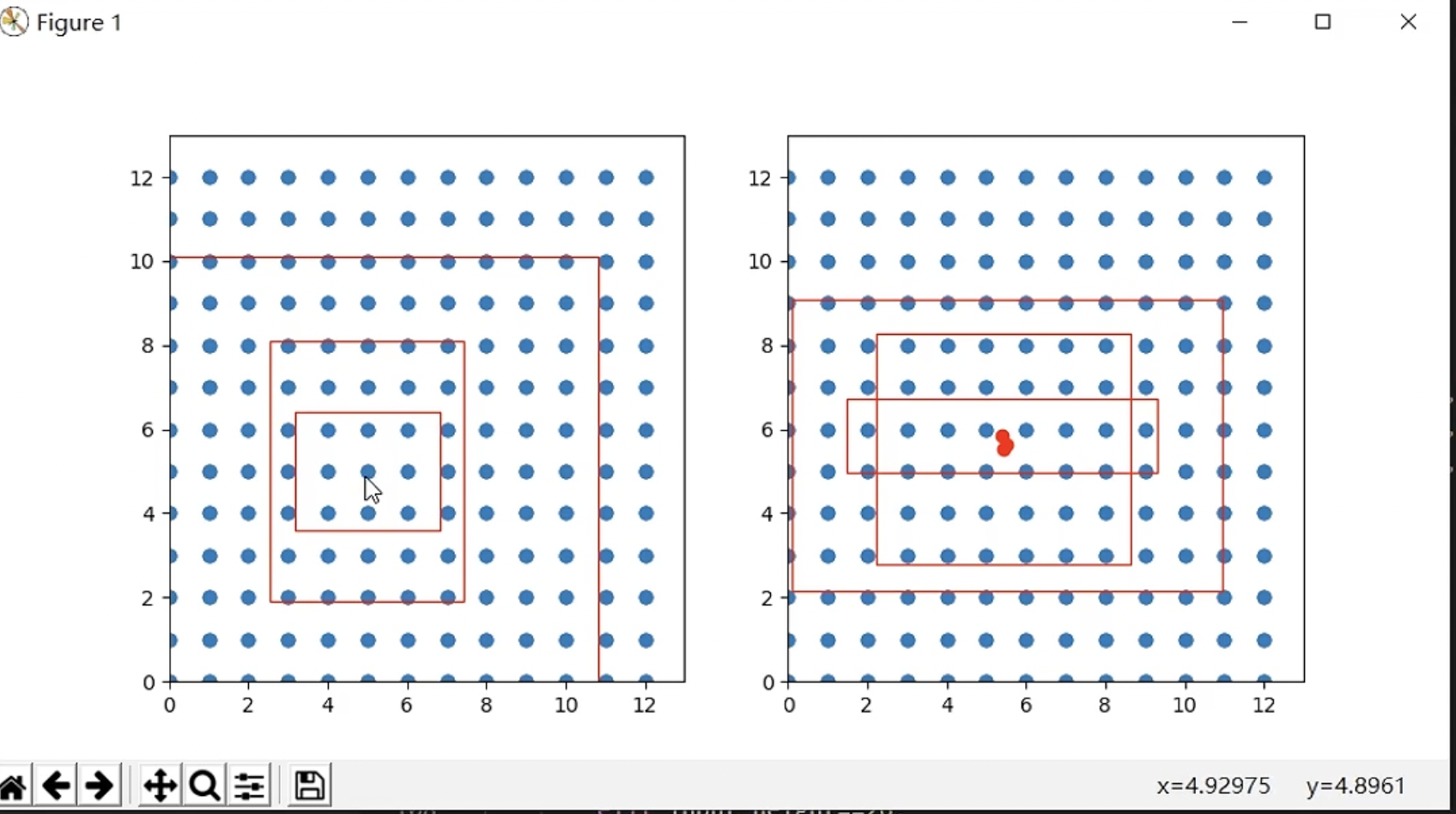
可以看到原本的三个先验框的中心点是相同的,调整之后,先验框的中心点发生了偏移。
YOLOv4的预测过程
计算输入图片的宽高 ——> 将图片转化为RGB图片 ——> 给图片增加灰条,实现不失真的resize ——> 归一化转置后,添加上Batch维度 ——> 将图片输入网络进行预测(需要转为tensor)——> 对输出特征层进行解码 ——> 对预测框进行堆叠,进行非极大抑制
其中非极大抑制过程:取出每一种类的粉最大的框,把它和其他的框进行一个交并比的计算,如果该值大于设置的阈值,则保留这个框。
VOC检测数据集的格式
该格式的主体目录为:
1
2
3
4
5
|
- 数据集名称
-|- VOC2007
-|-|- ImageSets(文件夹里面放训练集,验证集,测试集,以txt的形式呈现)
-|-|- JPEGImages(文件夹里面放原图)
-|-|- Annotations(文件夹里面放标签的信息,以xml文件形式存在)
|
其中Annotations中对应JPEGImages里面每张图片对应一个xml文件,放一个xml文件的格式示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
<annotation>
<folder>VOC2007</folder>
<filename>ed27edc6-cec1-11ed-96cf-58961d2b4192.jpg</filename>
<size>
<width>1000</width>
<height>750</height>
<depth>3</depth>
</size>
<object>
<name>class1</name>
<bndbox>
<xmin>899</xmin>
<ymin>29</ymin>
<xmax>923</xmax>
<ymax>286</ymax>
</bndbox>
</object>
<object>
<name>class2</name>
<bndbox>
<xmin>814</xmin>
<ymin>69</ymin>
<xmax>840</xmax>
<ymax>319</ymax>
</bndbox>
</object>
<object>
<name>class3</name>
<bndbox>
<xmin>745</xmin>
<ymin>60</ymin>
<xmax>761</xmax>
<ymax>195</ymax>
</bndbox>
</object>
<object>
<name>class4</name>
<bndbox>
<xmin>741</xmin>
<ymin>307</ymin>
<xmax>759</xmax>
<ymax>520</ymax>
</bndbox>
</object>
<object>
<name>class5</name>
<bndbox>
<xmin>693</xmin>
<ymin>61</ymin>
<xmax>710</xmax>
<ymax>211</ymax>
</bndbox>
</object>
<object>
<name>class6</name>
<bndbox>
<xmin>511</xmin>
<ymin>51</ymin>
<xmax>613</xmax>
<ymax>579</ymax>
</bndbox>
</object>
<object>
<name>class7</name>
<bndbox>
<xmin>93</xmin>
<ymin>304</ymin>
<xmax>114</xmax>
<ymax>544</ymax>
</bndbox>
</object>
</annotation>
|
其中我们需要的信息只有
通过聚类算法对特定数据集进行先验框的调整
先验框的检测和边框预测都是在 YOLOv4 模型中的头部检测模块中进行的,YOLOv4 模型在设计时没有对 Head 进行改进,使用的仍然是 YOLO_Head 检测头。设定的这些先验框尺寸就是经过聚类算法 K-means 聚类而来的,其中的 K的取值,一般是随机确定一个初始点,然后在距离这个点最远的距离为第二个点,以此类推可以确定多个点。假设K的取值为 2,包括了手机和烟头两种目标类型。
这里设定的先验框会根据网格内是否存在目标对先验框进行维持的微调。映射到本文中的YOLOv4 检测算法中,在生成网格后,在每个网格中生成三个不同尺寸的预测框,这三个预测框会对出租车司机违规行为数据中的手机和烟头目标进行微调得到真实框,并通过先验框和真实框求出它们之间的 IOU (交并比),通过交并比来判断出更真实的检测框。
远程使用服务器上的Tensorboard
本机操作系统:MacOS 12
服务器系统:Ubuntu
如何远程使用TensorBoard
- 连接ssh时,将服务器的6006端口重定向到自己的机器上
1
|
$ ssh -L 16006:127.0.0.1:6006 username@remote_server_ip
|
或者
1
|
$ ssh -L 8008:localhost:6006 username@remote_server_ip
|
- 在服务器上使用6006端口正常启动tensorboard:
1
|
$ tensorboard --logdir=xxx --port=6006
|
授权书特定区域检测思路
授权书的需求如下:
给定一张移动公司的授权书模版,需要将代表不同区域的位置给分割出来,然后交给文字OCR进行识别。
由于文字OCR已经做好了,给我的需求就是将该图上这些区域给分割出来。
难点解析
- 1.该需求只对特定的信息区域进行检测。
- 2.对于特定文字区域来说,对于整张图片来说,语义信息与其他文字区域相似;且在这些区域中,存在手写体和打印体。区域在拖片中的位置是不固定的,也就是说授权书的摆放位置是不固定的(横竖摆放都存在)。
- 3.对检测的准确率要求较高,也就是Precsion较高,因为检测不准,那么就会漏文字。
解决思路
- 1.针对语义信息不足的问题,拟采用分两阶段检测的方法进行。第一阶段检测带文字属性字段和属性信息的联合区域的检测。
第二阶段将除了检测到的区域像素全部置0(加mask)。再对我们的属性信息部分区域进行检测。将难度较高的任务分为两个更简单的任务的组合。
- 2.yolo系列算法集成较好,使用起来成本不会特别高。(众所周知,改进结构的效果是有限的,我们不是在科研,能解决问题就行)。
- 3.对于分类的问题,第一阶段应该进行分类。首先不同的类之间在图片中的位置信息不同,周围的文字分布信息也不同。根据这个点可以比较好分类。如果将所有区域分为1类,则很难找到它们联合的特征与其他文本区域特征的区别。
- 4.对于第二阶段的检测,应该注重准确率,目前想法分为1类。因为它们的特征比较明显,要么有下划线(红框区域中),要么与其他文本区域有明显的界限。
YOLO格式标签——>VOC检测格式
YOLO数据集格式:
1
2
3
4
5
6
7
8
9
|
# images下面的train和val放图片,labels下面的train和val下面放标签(txt文件格式)
- dataset
-- score
--- images
---- train
---- val
--- labels
---- train
---- val
|
YOLO格式的检测标签较为简单,例子:
1
2
3
4
5
6
7
8
9
10
|
# 从左到右分别代表:
# 类别 检测框的中心x坐标 检测框的中心y坐标 检测框的高 检测框的宽
# 上面提及的坐标都已经归一化,归一化的标准是按照原始影像大小进行归一化
0 0.915000 0.234667 0.034000 0.381333
1 0.813000 0.280667 0.034000 0.329333
2 0.721000 0.238667 0.026000 0.229333
3 0.725000 0.624667 0.034000 0.294667
4 0.661500 0.246667 0.025000 0.234667
5 0.505500 0.498000 0.131000 0.726667
6 0.045000 0.646667 0.040000 0.330667
|
那么如何将该格式转化为VOC格式的检测数据(.xml文件)呢?这涉及部分数学计算。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
import os
import cv2
import xml.etree.ElementTree as ET
import xml.dom.minidom as minidom
def yolo_to_voc(yolo_annotation, image_path, new_label_folder):
os.makedirs(new_label_folder, exist_ok=True)
class_names = ['class1', 'class2', 'class3', 'class4', 'class5', 'class6', 'class7'] # Replace with your class names
image = cv2.imread(image_path)
height, width, _ = image.shape
root = ET.Element("annotation")
folder = ET.SubElement(root, "folder")
folder.text = "VOC2007"
filename = ET.SubElement(root, "filename")
filename.text = os.path.basename(image_path)
size = ET.SubElement(root, "size")
width_elem = ET.SubElement(size, "width")
width_elem.text = str(width)
height_elem = ET.SubElement(size, "height")
height_elem.text = str(height)
depth_elem = ET.SubElement(size, "depth")
depth_elem.text = str(3) # Assuming 3-channel images
for line in yolo_annotation:
class_id, x_center, y_center, w, h = map(float, line.split())
class_name = class_names[int(class_id)]
x_min = int((x_center - w / 2) * width)
y_min = int((y_center - h / 2) * height)
x_max = int((x_center + w / 2) * width)
y_max = int((y_center + h / 2) * height)
object_elem = ET.SubElement(root, "object")
name_elem = ET.SubElement(object_elem, "name")
name_elem.text = class_name
bbox = ET.SubElement(object_elem, "bndbox")
xmin_elem = ET.SubElement(bbox, "xmin")
xmin_elem.text = str(x_min)
ymin_elem = ET.SubElement(bbox, "ymin")
ymin_elem.text = str(y_min)
xmax_elem = ET.SubElement(bbox, "xmax")
xmax_elem.text = str(x_max)
ymax_elem = ET.SubElement(bbox, "ymax")
ymax_elem.text = str(y_max)
xml_path = os.path.join(new_label_folder, os.path.basename(image_path).replace('.jpg', '.xml'))
# 保存新的XML文件,并使用xml.dom.minidom进行格式化
xml_string = ET.tostring(root, encoding="utf-8")
dom = minidom.parseString(xml_string)
pretty_xml_string = dom.toprettyxml(indent=" ")
# 去掉XML声明
pretty_xml_string = '\n'.join([line for line in pretty_xml_string.split('\n') if not line.strip().startswith('<?xml')])
with open(xml_path, "w", encoding="utf-8") as f:
f.write(pretty_xml_string)
# Replace with the actual paths to your YOLO annotation files and image folder
yolo_annotation_dir = "授权书标注/label"
image_folder = "授权书标注/biaozhu1"
new_label_folder = "授权书标注/voc_label"
if not os.path.exists(image_folder):
raise ValueError("Image folder does not exist.")
yolo_annotation_files = os.listdir(yolo_annotation_dir)
for yolo_file in yolo_annotation_files:
yolo_file_path = os.path.join(yolo_annotation_dir, yolo_file)
with open(yolo_file_path, 'r') as f:
yolo_lines = f.readlines()
image_name = os.path.splitext(yolo_file)[0] + ".jpg"
image_path = os.path.join(image_folder, image_name)
if not os.path.exists(image_path):
raise ValueError(f"Image '{image_name}' not found in the image folder.")
yolo_to_voc(yolo_lines, image_path, new_label_folder)
|
YOLOv8专用框架
YOLOv8官方的代码库非常完善,官方提供了命令行(CLI)和Python接口,封装地相当好。
YOLOv8官方代码库
YOLOv8官方文档
环境准备
环境准备其实非常简单,准备一个能使用CUDA和cuDNN的环境就好。由于我们使用的是其封装好的接口,不是优化源代码,所以我们只需要下载一个ultralytics的包就ok了:
1
|
$ pip install ultralytics
|
如果需要使用docker,它也在Docker-Hub上集成好了镜像:https://hub.docker.com/r/ultralytics/ultralytics,也支持Gradient,Colab,Kaggle平台使用,对白嫖党也很友好。
数据准备
YOLOv8使用的是yolo格式的数据集。因为我使用的是其检测的分支,所以我们准备一个检测的数据集。数据集的文件组织方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
- 数据集名称
-- dataset
--- score
---- images
----- train
...//放置图片
----- val
...//放置图片
---- labels
----- train
...//放置txt标签文件
----- val
...//放置txt标签文件
|
编写一个关于数据集的yaml文件,data.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
train: ./YOLO_Authorize_letter/dataset/score/images/train # train images
val: ./YOLO_Authorize_letter/dataset/score/images/val # val images
# test: # test images (optional)
# Classes 注意这里的类别和标签的类别要对应
names:
0: class1
1: class2
2: class3
3: class4
4: class5
5: class6
6: class7
|
使用官方提供的模型yaml文件,yolov8.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 7 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
|
使用该文件需要注意的是:nc需要根据自己数据集的分类数进行改变,与上面的data.yaml的类别需要对应。
训练准备
新建一个YOLOv8根目录,将数据集以及上述两个文件放置在根目录上,运行官方给的训练示例:
1
|
$ yolo train data=coco128.yaml model=yolov8m.yaml epochs=10 lr0=0.01
|
需要注意的是虽然我们的文件是yolov8.yaml,我们使用yolov8n.yaml会直接进行解析,非常方便。
但简单的参数调整不足以使用,我们要获取全局的参数调整,可以使用下面这种方式:
这时可以看到根目录出现了一个default_copy.yaml文件
1
|
$ yolo cfg='default_copy.yaml'
|
训练结果会在根目录下的runs/detect/train文件夹下,如果是第二次启动训练则会在runs/detect/train2文件夹下。也可以通过终端提示的命令在TensorBoard查看,如果是服务器上,就需要使用服务器端口映射的服务,在上文有讲。
用训练得到的模型进行预测
我们仍然可以使用CLI的方式运行,只需要修改mode的model以及predict那一栏的参数。但我并不推荐这种方式,因为我们通常的目的并不是单纯检测,而是为了检测出后获取坐标进行后续操作。
所以我们使用python接口的方式,官方给的小示例:
1
2
3
4
5
6
|
from ultralytics import YOLO
model = YOLO("runs/detect/train/weights/best.pt")
# accepts all formats - image/dir/Path/URL/video/PIL/ndarray. 0 for webcam
# source这里放存放需要预测图片的文件位置
results = model.predict(source="...", save=True)
|
需要注意的是predict中接受的参数还有很多,比如比较重要的有conf,代表我们保留预测框的置信度,imgsz代表模型推理的输入尺寸大小,默认为(640,640),line_width代表检测框的粗心,只能为int值。更多的参数设置参考官方文档
预测的结果会保存在runs/detect/predict,如果是第二次预测会保存在runs/detect/predict2,依次类推。
为了了解results的内容,将一张图片的预测的结果results输出一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
boxes: ultralytics.engine.results.Boxes object
keypoints: None
keys: ['boxes']
masks: None
names: {0: 'company_name', 1: 'signature', 2: 'authorized_name', 3: 'telephone_number', 4: 'id_number', 5: 'mobile_branch_name', 6: 'date'}
orig_img: array([[[ 94, 107, 123],
[ 93, 106, 122],
[ 92, 105, 121],
...,
[ 81, 102, 117],
[ 79, 100, 115],
[ 78, 99, 114]],
[[ 95, 108, 124],
[ 94, 107, 123],
[ 93, 106, 122],
...,
[ 77, 98, 113],
[ 77, 98, 113],
[ 78, 99, 114]],
[[ 95, 108, 124],
[ 95, 108, 124],
[ 94, 107, 123],
...,
[ 76, 97, 112],
[ 76, 97, 112],
[ 78, 99, 114]],
...,
[[100, 120, 138],
[100, 120, 138],
[ 99, 119, 137],
...,
[115, 135, 153],
[113, 133, 151],
[114, 134, 152]],
[[101, 118, 137],
[101, 118, 137],
[101, 118, 137],
...,
[116, 136, 154],
[115, 135, 153],
[114, 134, 152]],
[[100, 117, 136],
[100, 117, 136],
[100, 117, 136],
...,
[118, 138, 156],
[117, 137, 155],
[113, 133, 151]]], dtype=uint8)
orig_shape: (3648, 2736)
path: '/data/caixj/ultralytics-main/test_imgs/ed257e76-cec1-11ed-b87c-58961d2b4192.jpg'
probs: None
save_dir: None
speed: {'preprocess': 3.3495426177978516, 'inference': 32.27806091308594, 'postprocess': 1.6703605651855469}]
|
结合官方文档,发现我们需要的检测框的坐标信息在boxes对象中。boxes对象的属性信息如下:
boxes.xyxy # 检测框的绝对值坐标,分别是min_x,min_y,max_x,max_y
boxes.xywh # 检测框的绝对值坐标,分别是中心点坐标和宽高
boxes.xyxyn # 检测框的归一化坐标,分别是min_x,min_y,max_x,max_y
boxes.xywhn # 检测框的归一化坐标,分别是中心点坐标和宽高
boxes.conf # 检测框的置信分数
boxes.cls # 类别, (N, )
boxes.data # 原始目标框参数坐标 (x, y, w, h)、置信度以及类别, (N, 6) or boxes.boxes
为了完成我们切割区域的需求,我们来编写一个小的脚本进行批量操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
from ultralytics import YOLO
from PIL import Image
import cv2
import numpy as np
import os
def process_image_with_yolov8(image, detections, image_out):
# 获取原始图像的尺寸
height, width = image.shape[:2]
# 创建全黑遮罩,与原始图像尺寸相同
mask = np.zeros((height, width), dtype=np.uint8)
# 将检测到的区域设为非零值
for box in detections:
x_min, y_min, x_max, y_max = box[:4]
x_min, x_max = int(x_min * width), int(x_max * width)
y_min, y_max = int(y_min * height), int(y_max * height)
mask[y_min:y_max, x_min:x_max] = 255 # 设置为255,即白色,也可以设置为1
# 将原始图像与遮罩图像相乘,得到只有检测区域保持原始像素值,其他区域都变为0的图像
result_image = cv2.bitwise_and(image, image, mask=mask)
# 保存结果图
cv2.imwrite(image_out, result_image)
if __name__ == "__main__":
image_dir = "test_imgs"
images_process = "images_process"
model = YOLO("runs/detect/train/weights/best.pt")
# accepts all formats - image/dir/Path/URL/video/PIL/ndarray. 0 for webcam
results = model.predict(source=image_dir, save=False, conf=0.45, device=1, line_width=2) #
# print(results)
for i in range(len(results)):
# 读取results结果内的原始图像
# 最好不要通过cv2和PIL等重新读入,实测和预测框的结果会有偏差
image = results[i].orig_img
image_name = results[i].path.split('/')[-1]
image_out = os.path.join(images_process, image_name)
result = results[i].cpu().numpy()
# 获取归一化的坐标
detections = result.boxes.xyxyn
print("该张图像的检测框坐标分别为:")
print(detections)
process_image_with_yolov8(image, detections, image_out)
|
Log日志使用
log日志的级别
logging 模块定义了几个不同级别的日志,从高到低的顺序如下:
CRITICAL(最高级别):用于指示严重的错误,可能导致程序无法继续运行。ERROR:用于指示程序运行时的错误,但程序仍然可以继续运行。WARNING:用于表示警告信息,可能表明程序出现了一些意外情况,但仍然在正常运行。INFO:用于一般性的信息记录,用来追踪程序的执行状态。DEBUG(最低级别):用于调试目的,记录详细的调试信息,一般在开发和调试阶段使用。
这些日志级别的区别在于它们的严重程度和目的。你可以根据不同的场景和需求,选择适当的日志级别来记录信息。
如果你希望同时保存多个级别的日志,可以使用多个日志处理程序,每个处理程序负责处理一个特定级别的日志。以下是一个示例,展示了如何同时保存 DEBUG、INFO、WARNING、ERROR 和 CRITICAL 五个级别的日志。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
import os
import logging
from datetime import datetime
# 确保logs文件夹存在
if not os.path.exists('logs'):
os.makedirs('logs')
# 获取当前时间并格式化为字符串
current_time = datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
# 设置日志文件名
log_filename = os.path.join('logs', f'{current_time}-server.log')
# 配置日志
logging.basicConfig(filename=log_filename, level=logging.DEBUG,
format='%(asctime)s - %(levelname)s - %(message)s')
# 获取一个Logger实例
logger = logging.getLogger(__name__)
# 创建一个文件处理程序来保存所有级别的日志
file_handler = logging.FileHandler(log_filename)
file_handler.setLevel(logging.DEBUG)
# 创建一个控制台处理程序来输出INFO级别以上的日志到控制台
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# 创建一个格式化器
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
console_handler.setFormatter(formatter)
# 将处理程序添加到Logger实例
logger.addHandler(file_handler)
logger.addHandler(console_handler)
def process_data(data):
try:
# ... 一些处理逻辑
# 记录日志
logger.debug("Debug message: %s", data)
logger.info("Info message: %s", data)
logger.warning("Warning message: %s", data)
logger.error("Error message: %s", data)
logger.critical("Critical message: %s", data)
return "Data processed successfully."
except Exception as e:
# 记录异常日志
logger.exception("An exception occurred: %s", str(e))
return "An error occurred."
if __name__ == '__main__':
data = "Some data to process"
result = process_data(data)
print(result)
|
在上述示例中,我们创建了一个文件处理程序 file_handler 来保存所有级别的日志,并将它添加到 Logger 实例中。同时,我们创建了一个控制台处理程序 console_handler 来输出 INFO 级别以上的日志到控制台,并将它也添加到 Logger 实例中。这样,你就可以同时保存 DEBUG、INFO、WARNING、ERROR 和 CRITICAL 五个级别的日志,并且在控制台上输出一部分级别的信息。
接口的封装
该部分由于涉及公司的代码,只讲思路。通常打包需要两个文件,一个是包含环境变量的镜像文件,另一个则是项目的源代码包。
工程的标准:
- 一般需要将可以设置的参数文件统一集成到一个配置文件中。如果配置参数过多,还可以分文件存储,一般放在
config文件夹下。
- 模型参数权重则一般放在一个专门的
models或者checkpoints文件夹下面
- 使用onnx,tensorrt推理,是不需要模型文件的。如果直接用pytorch推理,一般需要一个模型文件,以及一些前处理和后处理的文件。这里使用的是yolov8官方提供的推理包,则不需要模型文件了。
- 主函数不要集成太多的方法,尽量分文件写
- 程序中需要包含详细的日志记录,并需要自动保存在一个单独的文件夹中。一般使用
logs文件夹。
Linux下打包与解压
打包图片tar
tar 是Linux中最常用的打包压缩工具,该命令可以把一系列文件打包到一个大文件中,也可以把一个大文件恢复一系列文件。打包/解包的格式如下:
1
2
3
4
5
6
7
|
# 打包文件(打包文件的后缀名一般使用的是.tar)
tar -cvf 打包文件.tar 被打包的文件所在路径
# 一次可以打包多个文件
tar -cvf pkg.tar a.txt b.txt c.txt
# 解包文件
tar -xvf 打包文件.tar
|
tar选项说明:
| 选项 |
含义 |
| -c |
生成档案文件,创建打包文件 |
| -x |
解开档案文件 |
| -v |
列出归档接档的详细过程,显示进度 |
| -f |
指定档案文件,f后面一定是.tar 文件,必须放选项最后 |
tar与gzip相结合
tar 和 gzip 结合可以实现文件的打包压缩。tar 只负责打包,不负责压缩;gzip 负责压缩,压缩以后的扩展名为 xxx.tar.gz(由扩展名可以看出,这个压缩包经历了打包和压缩两个过程)。tar 命令中有一个 -z 选项可以调用 gzip,从而达到打包压缩一步到位的效果。基本命令格式如下:
1
2
3
4
5
6
7
8
9
10
|
# 压缩文件
tar -zcvf 压缩文件.tar.gz 被压缩的文件所在路径
# 一次可以压缩多个文件
tar -zcvf pkg.tar.gz a.txt b.txt c.txt
# 解压文件
tar -zxvf 压缩文件.tar.gz
# -C:解压文件到指定路径
tar -zxvf 压缩文件.tar.gz -C /usr
|
tar与bzip2相结合
使用方式和上面的gzip十分类似,tar 命令中有一个-j选项可以调用bzip2,从而可以方便的实现压缩和解压缩。命令格式如下:
1
2
3
4
5
6
7
8
|
# 压缩文件(将文件压缩成 xxx.tar.bz2格式)
tar -jcvf 压缩文件.tar.bz2 被压缩的文件所在路径
# 解压文件
tar -jxvf 压缩文件.tar.bz2
# 解压文件到指定路径
tar -jxvf 压缩文件.tar.bz2 -C /usr
|
Linux下不同格式软件包的安装(默认Ubuntu)
1
2
3
4
|
# 安装deb包
sudo dpkg -i 包名.deb
# 卸载deb包
sudo apt-get remove 包名
|
1
2
3
4
5
6
|
# 安装
rpm -i 包名.rpm
# 卸载
rpm -e 完整软件名
# 如果不知道完整名称使用命令
rpm -qa 部分包名*
|
1
2
3
4
5
|
# 加上可执行的权限
chmod +x 包名.bin
# 安装
./包名.bin
# 卸载:把安装的目录卸载即可
|
1
2
3
4
5
6
|
# 加上可执行的权限
chmod +x 包名.run
# 安装
./包名.run
# 卸载:进入安装目录,找到uninstall文件
./uninstall
|
1
2
3
4
|
# 根据类型解压文件,前面已经讲过了
tar -zxvf 包名.tar.gz
# 随后查看README文件或者其他说明文件再进行源码编译
...
|
Linux下的进程查看与销毁
PS命令:ps命令是一个相当强大地Linux进程查看命令,运用该命令可以确定有哪些进程正在运行和运行地状态、 进程是否结束、进程有没有僵死、哪些进程占用了过多地资源等。
-
参数:
-e显示所有进程,环境变量
-f全格式
-h不显示标题
-l长格式
-w宽输出
-a显示终端上地所有进程,包括其他用户地进程
-r只显示正在运行地进程
-x显示没有控制终端地进程
1
2
|
ps -ef | grep java //表示查看所有进程里CMD是java的进程信息
ps -aux | grep java //-aux显示所有状态
|
Top命令:top命令可以实时显示各个线程情况。要在top输出中开启线程查看,请调用top命令的“-H”选项,该选项会列出所有Linux线程。在top运行时,你也可以通过按“H”键将线程查看模式切换为开或关。
1
2
3
|
top // 查看整体情况,cpu,内存,进程等信息
top -Hp pid //查看进程相关的线程信息
也可以通过htop命令查看cpu,内存,进程等信息
|
Pstree命令:pgrep命令以名称为依据从运行进程队列中查找进程,并显示查找到的进程id。每一个进程ID以一个十进制数表示,通过一个分割字符串和下一个ID分开,默认的分割字符串是一个新行。对于每个属性选项,用户可以在命令行上指定一个以逗号分割的可能值的集合。
1
2
3
4
5
6
7
|
pstree -p // 显示当前所有进程的进程号和进程id
pstree -a // 显示所有进程的所有详细信息,遇到相同的进程名可以压缩显示
pstree -apnh //显示在运行的进程间的关系
pstree -u //显示用户名称
|
kill是最常用的杀死进程命令,需要配合ps命令先确认待杀死进程的进程号(pid)。
1
2
3
4
5
6
7
8
|
# 常规用法:kill <pid> // 杀死指定pid号的单个进程
$ kill -9 <pid> //强制杀死进程
$ killall <pname> //杀掉所有同名进程
$ pkill <pname> // 杀掉所有同名进程或指定用户的所有进程
# 比如有个tom用户离职了,需要清理掉其在Linux服务器上的所有进程,执行此命令即可。
$ pkill -u tony
|
Flask启动服务
启动服务的基本使用方法:
1
2
3
4
5
6
7
|
app = Flask(__name__)
@app.route('/post', methods=['POST','GET'])
def receive_request():
# 接收请求的逻辑
if __name__ == '__main__':
app.run(host=${IP}$, port=${port}$)
|
外部请求测试程序(图片base64数据请求):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
import os
import requests
import base64
import logging
import time
import sys
import json
import shutil
header = {"appId": "health_check", "token": "", "requestId": "80088208820",
"requestTime": "2021-03-16 23:15:00"}
def get_base64(img_path):
with open(img_path, 'rb') as img_obj:
base64_data = base64.b64encode(img_obj.read())
base64_str = str(base64_data, 'utf-8')
return base64_str
def check_health(path):
url = 'http://0.0.0.0:5000/post'
base64_str = get_base64(path)
request_data = json.dumps({"image": base64_str})
print(type(request_data))
start = time.time()
response = requests.post(url=url, data=request_data ,headers=header)
end = time.time()
time_cost = end - start
result = response.text.encode().decode("unicode_escape")
print(time_cost)
print(result)
return response.text
if __name__ == '__main__':
b = './test_imgs/img2.jpg'
print(check_health(b))
|
授权书检测部署华为昇腾计算平台:2023.8.14~2023.9.04
现在要求,将之前检测的服务是在有NVIDIA的生产平台上做在线推理,新的需求是做在华为的昇腾计算平台(昇腾910)上做在线推理或者离线推理。
在线推理和离线推理有什么区别呢?
-
- 在线推理依赖于网络框架,这种网络框架是包含训练和推理的网络框架,而离线推理有专门的定制推理框架。
-
- 在线推理没有针对特定的硬件做优化,也没有经过精度的调优。而离线推理特别讲究性能和时间长短的平衡,经常需要量化,或者其他加速手段。
由于YOLOv8集成了API,直接下载了ultralytics包就可以直接使用。而要在昇腾平台上运行,必须使用昇腾支持的模型格式,而模型本身不包含前处理和后处理,所以首先要了解官方对YOLOv8推理的全过程。
YOLOv8推理全过程
前处理
yolov8预设的图片输入是640x640大小的,所以我们需要将一般大小的图像resize成标准大小,但是单纯的只是用resize来操作的话有可能会造成图像的失真,所以使用了letterbox缩放。
具体的过程:将原图按比例resize成640大小,不足640大小的宽或者高使用灰条进行填充。
前处理的Python代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def resize_image(image, size, letterbox_image):
"""
对输入图像进行resize
Args:
size:目标尺寸
letterbox_image: bool 是否进行letterbox变换
Returns:指定尺寸的图像
"""
from PIL import Image
ih, iw, _ = image.shape
h, w = size
if letterbox_image:
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = cv2.resize(image, (nw, nh), interpolation=cv2.INTER_LINEAR)
# 生成画布
image_back = np.ones((h, w, 3), dtype=np.uint8) * 128
# 将image放在画布中心区域-letterbox
image_back[(h-nh)//2: (h-nh)//2 + nh, (w-nw)//2:(w-nw)//2+nw, :] = image
else:
image_back = image
return image_back # 返回图像和坐标原点
|
现在我们得到了(640$\times$640$\times$3)大小的图片,模型输入为(N,C,H,W),我们需要对其进行预处理操作
预处理
预处理器操作的Python代码:
1
2
3
4
5
|
def img2input(img):
img = cv2.cvtColor(img, cv.COLOR_BGR2RGB) # BGR转RGB
img = np.transpose(img, (2, 0, 1))
img = img/255 # 归一化像素值
return np.expand_dims(img, axis=0).astype(np.float32) # (1,3,640,640)
|
ONNXRuntime推理
虽然,我们最后使用的是.om离线模型作推理,但首先要了解整个推理过程,这里就使用依赖较少的ONNX模型作推理。
推理的Python代码:
1
2
3
4
5
6
|
sess = rt.InferenceSession('runs/detect/train49/weights/best.onnx')
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred = sess.run([label_name], {input_name: data})[0]
# 自己的模型使用yolov8微调,最后分类的类别数为7
# (bs, 11=7cls+4reg, 8400=3种尺度的特征图叠加), 这里的预测框的回归参数是xywh,而不是中心点到框边界的距离
|
模型得到的输出格式为(1$\times$11$\times$8400),11=边界框预测值 4+数据集类别 7, yolov8不另外对置信度预测, 而是采用类别里面最大的概率作为置信度score,8400是v8模型各尺度输出特征图叠加之后的结果(具体如何叠加可以看源码,一般推理不需要管)。本文对模型的输出进行如下操作,方便后处理:
1
2
3
4
5
6
7
8
9
10
11
|
def std_output(pred):
"""
将模型的预测结果中的最后四个元素提取出来,并计算它们的最大值,然后将这个最大值插入到原始预测结果的倒数第四个位 置。这样做的目的可能是为了在后处理阶段为每个样本添加一个置信度得分,以提供关于预测结果的可靠性的信息。
将(1,11,8400)处理成(8400, 12) 12= box:4 conf:1 cls:7
"""
pred = np.squeeze(pred) # 因为只是推理,所以没有Batch
pred = np.transpose(pred, (1, 0)) # 处理成(8400,11)
pred_class = pred[..., 4:] # 将维度2的第5个开始的所有值取到
pred_conf = np.max(pred_class, axis=-1) # 做一次取最大
pred = np.insert(pred, 4, pred_conf, axis=-1) # 然后插入到原来索引为4的位置
return pred #(8400,12)
|
得到输出(8400,12)。8400个特征图的cell,每个cell里面有4+1+7的输出值,对应4个预测框+1个置信度(最大类别概率)+7类别概率。
后处理:置信度过滤+NMS非极大抑制
接下来就对刚刚的(8400,12)进行后处理,先进行置信度过滤,再进行NMS非极大值抑制,本文将这两步筛选操作放在了一个函数中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
def nms(pred, conf_thres, iou_thres):
"""
非极大值抑制nms
Args:
pred: 模型输出特征图
conf_thres: 置信度阈值
iou_thres: iou阈值
Returns: 输出后的结果
"""
box = pred[pred[..., 4] > conf_thres] # 置信度筛选
cls_conf = box[..., 5:]
cls = []
for i in range(len(cls_conf)):
cls.append(int(np.argmax(cls_conf[i])))
total_cls = list(set(cls)) # 记录图像内共出现几种物体
output_box = []
# 每个预测类别分开考虑
for i in range(len(total_cls)):
clss = total_cls[i]
cls_box = []
temp = box[:, :6]
for j in range(len(cls)):
# 记录[x,y,w,h,conf(最大类别概率),class]值
if cls[j] == clss:
temp[j][5] = clss
cls_box.append(temp[j][:6])
# cls_box 里面是[x,y,w,h,conf(最大类别概率),class]
cls_box = np.array(cls_box)
sort_cls_box = sorted(cls_box, key=lambda x: -x[4]) # 将cls_box按置信度从大到小排序
# box_conf_sort = np.argsort(-box_conf)
# 得到置信度最大的预测框
max_conf_box = sort_cls_box[0]
output_box.append(max_conf_box)
sort_cls_box = np.delete(sort_cls_box, 0, 0)
# 对除max_conf_box外其他的框进行非极大值抑制
while len(sort_cls_box) > 0:
# 得到当前最大的框
max_conf_box = output_box[-1]
del_index = []
for j in range(len(sort_cls_box)):
current_box = sort_cls_box[j]
iou = get_iou(max_conf_box, current_box)
if iou > iou_thres:
# 筛选出与当前最大框Iou大于阈值的框的索引
del_index.append(j)
# 删除这些索引
sort_cls_box = np.delete(sort_cls_box, del_index, 0)
if len(sort_cls_box) > 0:
# 我认为这里需要将clas_box先按置信度排序, 才能每次取第一个
output_box.append(sort_cls_box[0])
sort_cls_box = np.delete(sort_cls_box, 0, 0)
return output_box
def xywh2xyxy(*box):
"""
将xywh转换为左上角点和左下角点
Args:
box:
Returns: x1y1x2y2
"""
ret = [box[0] - box[2] // 2, box[1] - box[3] // 2, \
box[0] + box[2] // 2, box[1] + box[3] // 2]
return ret
def get_inter(box1, box2):
"""
计算相交部分面积
Args:
box1: 第一个框
box2: 第二个狂
Returns: 相交部分的面积
"""
x1, y1, x2, y2 = xywh2xyxy(*box1)
x3, y3, x4, y4 = xywh2xyxy(*box2)
# 验证是否存在交集
if x1 >= x4 or x2 <= x3:
return 0
if y1 >= y4 or y2 <= y3:
return 0
# 将x1,x2,x3,x4排序,因为已经验证了两个框相交,所以x3-x2就是交集的宽
x_list = sorted([x1, x2, x3, x4])
x_inter = x_list[2] - x_list[1]
# 将y1,y2,y3,y4排序,因为已经验证了两个框相交,所以y3-y2就是交集的宽
y_list = sorted([y1, y2, y3, y4])
y_inter = y_list[2] - y_list[1]
# 计算交集的面积
inter = x_inter * y_inter
return inter
def get_iou(box1, box2):
"""
计算交并比: (A n B)/(A + B - A n B)
Args:
box1: 第一个框
box2: 第二个框
Returns: # 返回交并比的值
"""
box1_area = box1[2] * box1[3] # 计算第一个框的面积
box2_area = box2[2] * box2[3] # 计算第二个框的面积
inter_area = get_inter(box1, box2)
union = box1_area + box2_area - inter_area #(A n B)/(A + B - A n B)
iou = inter_area / union
return iou
|
筛选完之后得到的输出output_box格式为N * [x,y,w,h,conf(最大类别概率),class] , N是筛选后预测框的个数, 通过[x,y,w,h,conf(最大类别概率),class]这些数据我们就可以将预测框输出绘制在原图像上, 但是要注意,我们此时模型的输入是经过letterbox处理的,所以需要先将预测框的坐标转换回原坐标系的坐标:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def cod_trf(result, pre, after):
"""
因为预测框是在经过letterbox后的图像上做预测所以需要将预测框的坐标映射回原图像上
Args:
result: [x,y,w,h,conf(最大类别概率),class]
pre: 原尺寸图像
after: 经过letterbox处理后的图像
Returns: 坐标变换后的结果,并将xywh转换为左上角右下角坐标x1y1x2y2
"""
res = np.array(result)
x, y, w, h, conf, cls = res.transpose((1, 0)) # (12, 8400)
x1, y1, x2, y2 = xywh2xyxy(x, y, w, h) # 左上角点和右下角的点
h_pre, w_pre, _ = pre.shape
h_after, w_after, _ = after.shape
scale = max(w_pre/w_after, h_pre/h_after) # 缩放比例
h_pre, w_pre = h_pre/scale, w_pre/scale # 计算原图在等比例缩放后的尺寸
x_move, y_move = abs(w_pre-w_after)//2, abs(h_pre-h_after)//2 # 计算平移的量
ret_x1, ret_x2 = (x1 - x_move) * scale, (x2 - x_move) * scale
ret_y1, ret_y2 = (y1 - y_move) * scale, (y2 - y_move) * scale
ret = np.array([ret_x1, ret_y1, ret_x2, ret_y2, conf, cls]).transpose((1, 0))
return ret # x1y1x2y2
|
绘制预测框
输出的ret的格式为N * [x1,y1,x2,y2,conf(最大类别概率),class],接下来就可以进行最后一步操作了,对预测框进行绘制,但是为了美观需要注意将字体大小随着预测框的大小进行动态调整,以及字体显示不能超过边界。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def draw(res, image, cls):
"""
将预测框绘制在image上
Args:
res: 预测框数据
image: 原图
cls: 类别列表,类似["apple", "banana", "people"] 可以自己设计或者通过数据集的yaml文件获取
Returns:
"""
for r in res:
# 画框
image = cv2.rectangle(image, (int(r[0]), int(r[1])), (int(r[2]), int(r[3])), (255, 0, 0), 1)
# 表明类别
text = "{}:{}".format(cls[int(r[5])], \
round(float(r[4]), 2))
h, w = int(r[3]) - int(r[1]), int(r[2]) - int(r[0]) # 计算预测框的长宽
font_size = min(h/640, w/640) * 3 # 计算字体大小(随框大小调整)
image = cv2.putText(image, text, (max(10, int(r[0])), max(20, int(r[1]))), cv2.FONT_HERSHEY_COMPLEX, max(font_size, 0.3), (0, 0, 255), 1) # max()为了确保字体不过界
cv2.imshow("result", image)
cv2.waitKey()
cv2.destroyWindow("result")
|
YOLOv8导出ONNX模型
首先在服务器上进行导出,遵从官方的demo,写python脚本export.py:
1
2
3
4
5
6
7
8
|
from ultralytics import YOLO
# load a model
model = YOLO('runs/detect/train/weights/best.pt')
# export the model
model.export(format='onnx', half=False, simplify=True, opset=11)
# model.export(format='onnx', half=True, simplify=True, opset=11)
|
本来认为这是最简单的步骤了,结果报错了。报错原因:
1
|
$ RuntimeError: Exporting the operator silu to ONNX opset version 11 is not supported.
|
网上说的方法都是修改虚拟环境中torch的源码的SiLU的实现,结果我找到服务器的源码文件,竟然没有这个函数。
通过ultralytics查看版本信息:
1
2
3
4
5
6
|
$ python
# 进入python命名空间
$ import ultralytics
$ ultralytics.checks()
$ Ultralytics YOLOv8.0.145 🚀 Python-3.7.7 torch-1.7.1+cu101 CUDA:0 (Tesla T4, 15110MiB)
Setup complete ✅ (40 CPUs, 62.4 GB RAM, 1559.7/1697.2 GB disk)
|
怀疑pytorch版本过低,果断下载ultralytics官方提供的最新docker镜像,启动了之后,再次运行上述命令,得到信息:
$ Ultralytics YOLOv8.0.154 🚀 Python-3.10.11 torch-2.0.1 CUDA:0 (Tesla T4, 15110MiB)
Setup complete ✅ (40 CPUs, 62.4 GB RAM, 1559.7/1697.2 GB disk)
可以看到我们的pytorch版本已经变为了2.0.1,继续执行export.py,发现已经执行成功了,分别导出了fp32和fp16的模型,分别是98.76M和49.41M。
FTP文件传输
然后输入用户名和密码
查看文件使用ls,到达指定目录用cd
首先设定本地接收文件的目录位置
1
|
lcd /home/user/yourdirectoryname
|
如果你不指定下载目录,文件将会下载到你登录 FTP 时候的工作目录。
现在,我们可以使用命令 get 来下载文件,比如:
下载多个文件可以使用通配符及 mget 命令。例如,下面这个例子我打算下载所有以 .xls 结尾的文件。
使用put命令上传文件:
当文件不再当前本地目录下的时候,可以使用绝对路径:
同样,可以上传多个文件:
1
2
3
4
|
# 三选一
bye
exit
quit
|
om模型推理过程
项目目前准备先使用Python完成全过程,所以我们使用AscendCL提供的PyACLAPI来写一下模型推理的过程,前后处理与ONNX保持一致:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
|
##
##
## Created by caixj in 2023-08-24
##
##
import acl
import os
import numpy as np
import cv2
# error code
ACL_SUCCESS = 0
# rule for mem
ACL_MEM_MALLOC_HUGE_FIRST = 0
ACL_MEM_MALLOC_HUGE_ONLY = 1
ACL_MEM_MALLOC_NORMAL_ONLY = 2
# rule for memory copy
ACL_MEMCPY_HOST_TO_HOST = 0
ACL_MEMCPY_HOST_TO_DEVICE = 1
ACL_MEMCPY_DEVICE_TO_HOST = 2
ACL_MEMCPY_DEVICE_TO_DEVICE = 3
# numpy data type
NPY_FLOAT32 = 11
buffer_method = {
"in": acl.mdl.get_input_size_by_index,
"out": acl.mdl.get_output_size_by_index
}
def check_ret(message, ret):
if ret != ACL_SUCCESS:
raise Exception("{} failed ret={}"
.format(message, ret))
class Net(object):
def __init__(self, device_id, model_path):
self.device_id = device_id # int
self.model_path = model_path # string
self.model_id = None # pointer
self.context = None # pointer
self.input_data = []
self.output_data = []
self.model_desc = None # pointer when using
self.load_input_dataset = None
self.load_output_dataset = None
self.init_resource()
def release_resource(self):
print("Releasing resources stage:")
ret = acl.mdl.unload(self.model_id)
check_ret("acl.mdl.unload", ret)
if self.model_desc:
acl.mdl.destroy_desc(self.model_desc)
self.model_desc = None
while self.input_data:
item = self.input_data.pop()
ret = acl.rt.free(item["buffer"])
check_ret("acl.rt.free", ret)
while self.output_data:
item = self.output_data.pop()
ret = acl.rt.free(item["buffer"])
check_ret("acl.rt.free", ret)
if self.context:
ret = acl.rt.destroy_context(self.context)
check_ret("acl.rt.destroy_context", ret)
self.context = None
ret = acl.rt.reset_device(self.device_id)
check_ret("acl.rt.reset_device", ret)
ret = acl.finalize()
check_ret("acl.finalize", ret)
print('Resources released successfully.')
def init_resource(self):
# acl初始化
print("init resource stage:")
ret = acl.init()
check_ret("acl.init", ret)
# 分配设备内存
ret = acl.rt.set_device(self.device_id)
check_ret("acl.rt.set_device", ret)
# 创建上下文
self.context, ret = acl.rt.create_context(self.device_id)
check_ret("acl.rt.create_context", ret)
# 加载模型
self.model_id, ret = acl.mdl.load_from_file(self.model_path)
check_ret("acl.mdl.load_from_file", ret)
print("model_id:{}".format(self.model_id))
# 为模型分配desc
self.model_desc = acl.mdl.create_desc()
# 获取模型信息
self._get_model_info()
print("init resource success")
def _get_model_info(self,):
ret = acl.mdl.get_desc(self.model_desc, self.model_id)
check_ret("acl.mdl.get_desc", ret)
input_size = acl.mdl.get_num_inputs(self.model_desc)
output_size = acl.mdl.get_num_outputs(self.model_desc)
self._gen_data_buffer(input_size, des="in")
self._gen_data_buffer(output_size, des="out")
def _gen_data_buffer(self, size, des):
func = buffer_method[des]
for i in range(size):
# check temp_buffer dtype
temp_buffer_size = func(self.model_desc, i)
temp_buffer, ret = acl.rt.malloc(temp_buffer_size,
ACL_MEM_MALLOC_HUGE_FIRST)
check_ret("acl.rt.malloc", ret)
if des == "in":
self.input_data.append({"buffer": temp_buffer,
"size": temp_buffer_size})
elif des == "out":
self.output_data.append({"buffer": temp_buffer,
"size": temp_buffer_size})
def _data_interaction(self, dataset, policy=ACL_MEMCPY_HOST_TO_DEVICE):
temp_data_buffer = self.input_data \
if policy == ACL_MEMCPY_HOST_TO_DEVICE \
else self.output_data
if len(dataset) == 0 and policy == ACL_MEMCPY_DEVICE_TO_HOST:
for item in self.output_data:
temp, ret = acl.rt.malloc_host(item["size"])
if ret != 0:
raise Exception("can't malloc_host ret={}".format(ret))
dataset.append({"size": item["size"], "buffer": temp})
for i, item in enumerate(temp_data_buffer):
if policy == ACL_MEMCPY_HOST_TO_DEVICE:
if "bytes_to_ptr" in dir(acl.util):
bytes_data = dataset[i].tobytes()
ptr = acl.util.bytes_to_ptr(bytes_data)
else:
ptr = acl.util.numpy_to_ptr(dataset[i])
ret = acl.rt.memcpy(item["buffer"],
item["size"],
ptr,
item["size"],
policy)
check_ret("acl.rt.memcpy", ret)
else:
ptr = dataset[i]["buffer"]
ret = acl.rt.memcpy(ptr,
item["size"],
item["buffer"],
item["size"],
policy)
check_ret("acl.rt.memcpy", ret)
def _gen_dataset(self, type_str="input"):
dataset = acl.mdl.create_dataset()
temp_dataset = None
if type_str == "in":
self.load_input_dataset = dataset
temp_dataset = self.input_data
else:
self.load_output_dataset = dataset
temp_dataset = self.output_data
for item in temp_dataset:
data = acl.create_data_buffer(item["buffer"], item["size"])
_, ret = acl.mdl.add_dataset_buffer(dataset, data)
if ret != ACL_SUCCESS:
ret = acl.destroy_data_buffer(data)
check_ret("acl.destroy_data_buffer", ret)
def _data_from_host_to_device(self, images):
print("data interaction from host to device")
# copy images to device
self._data_interaction(images, ACL_MEMCPY_HOST_TO_DEVICE)
# load input data into model
self._gen_dataset("in")
# load output data into model
self._gen_dataset("out")
print("data interaction from host to device success")
def _data_from_device_to_host(self):
print("data interaction from device to host")
res = []
# copy device to host
self._data_interaction(res, ACL_MEMCPY_DEVICE_TO_HOST)
print("data interaction from device to host success")
result = self.get_result(res)
# free host memory
for item in res:
ptr = item['buffer']
ret = acl.rt.free_host(ptr)
check_ret('acl.rt.free_host', ret)
return result
def run(self, images):
self._data_from_host_to_device(images)
self.forward()
res = self._data_from_device_to_host()
return res
def forward(self):
print('execute stage:')
ret = acl.mdl.execute(self.model_id,
self.load_input_dataset,
self.load_output_dataset)
check_ret("acl.mdl.execute", ret)
self._destroy_databuffer()
print('execute stage success')
def _destroy_databuffer(self):
for dataset in [self.load_input_dataset, self.load_output_dataset]:
if not dataset:
continue
number = acl.mdl.get_dataset_num_buffers(dataset)
for i in range(number):
data_buf = acl.mdl.get_dataset_buffer(dataset, i)
if data_buf:
ret = acl.destroy_data_buffer(data_buf)
check_ret("acl.destroy_data_buffer", ret)
ret = acl.mdl.destroy_dataset(dataset)
check_ret("acl.mdl.destroy_dataset", ret)
def get_result(self, output_data):
result = []
dims, ret = acl.mdl.get_cur_output_dims(self.model_desc, 0)
check_ret("acl.mdl.get_cur_output_dims", ret)
out_dim = dims['dims']
for temp in output_data:
ptr = temp["buffer"]
# 转化为float32类型的数据
if "ptr_to_bytes" in dir(acl.util):
bytes_data = acl.util.ptr_to_bytes(ptr, temp["size"])
data = np.frombuffer(bytes_data, dtype=np.float32).reshape(tuple(out_dim))
else:
data = acl.util.ptr_to_numpy(ptr, tuple(out_dim), NPY_FLOAT32)
result.append(data)
return result
def apply_resource(device_id, model_path):
"""
网络模型初始化
"""
net = Net(device_id, model_path)
return net
def infer_om(net, resize_img):
"""
对图片进行推理
"""
res = net.run([resize_img])
res = np.array(res[0])
print("*****run finish******")
net.release_resource()
return res
|
调用模型进行推理代码如下:
1
2
|
net = apply_resource(device_id, model_path)
res = infer_om(net, data)
|
Flask调用的华为昇腾om模型推理的坑
由于是业务代码,只能讲个大概。主要的坑就是模型推理服务需要一次加载多次使用。
所以按照逻辑,我在全局使用了net = apply_resource(device_id, model_path)初始化了模型,然后在Flask内部的函数使用res = infer_om(net, data)进行推理,正常来说是可以正确返回的,但真实的结果是会卡在将数据从Host拷贝到Device。
问题:使用正常的图片加载推理可以正常进行,但使用flask在全局加载模型在flask内部调用模型进行推理会出错
原因:通过咨询华为官方库的人员,根本原因是华为的om模型推理必须使用device申请的同一块context(上下文)。
解决:在全局获取推理使用的context,然后在flask内部设置推理使用的centext为刚刚获取的context
1.模型加载前调用
context, ret = acl.rt.get_context()
2.flask内部调用
ret = acl.rt.set_context(context)
保证模型加载和执行在同一context内。
ssh传文件命令
1
|
$ scp -P <端口号> <文件名> <user_name>@<ip>:<目标文件地址>
|
1
|
$ scp -P <端口号> -r <文件夹名> <user_name>@<ip>:<目标文件地址>
|
最后修改于 2023-09-04

本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。