ATC模型转换工具
ATC模型转换工具聚焦于开源框架的网络模型(Caffe,TensorFlow,Pytorch)通过昇腾张量编译器ATC(Ascend Tensor Compiler)将其转换成昇腾AI处理器支持的离线模型。模型转换的过程中可以实现算子调度的优化、权重数据重排、内存使用优化等(自动),可以脱离设备完成模型的预处理。
ATC模型转换-快速入门
下图是整个ATC工具的功能架构:
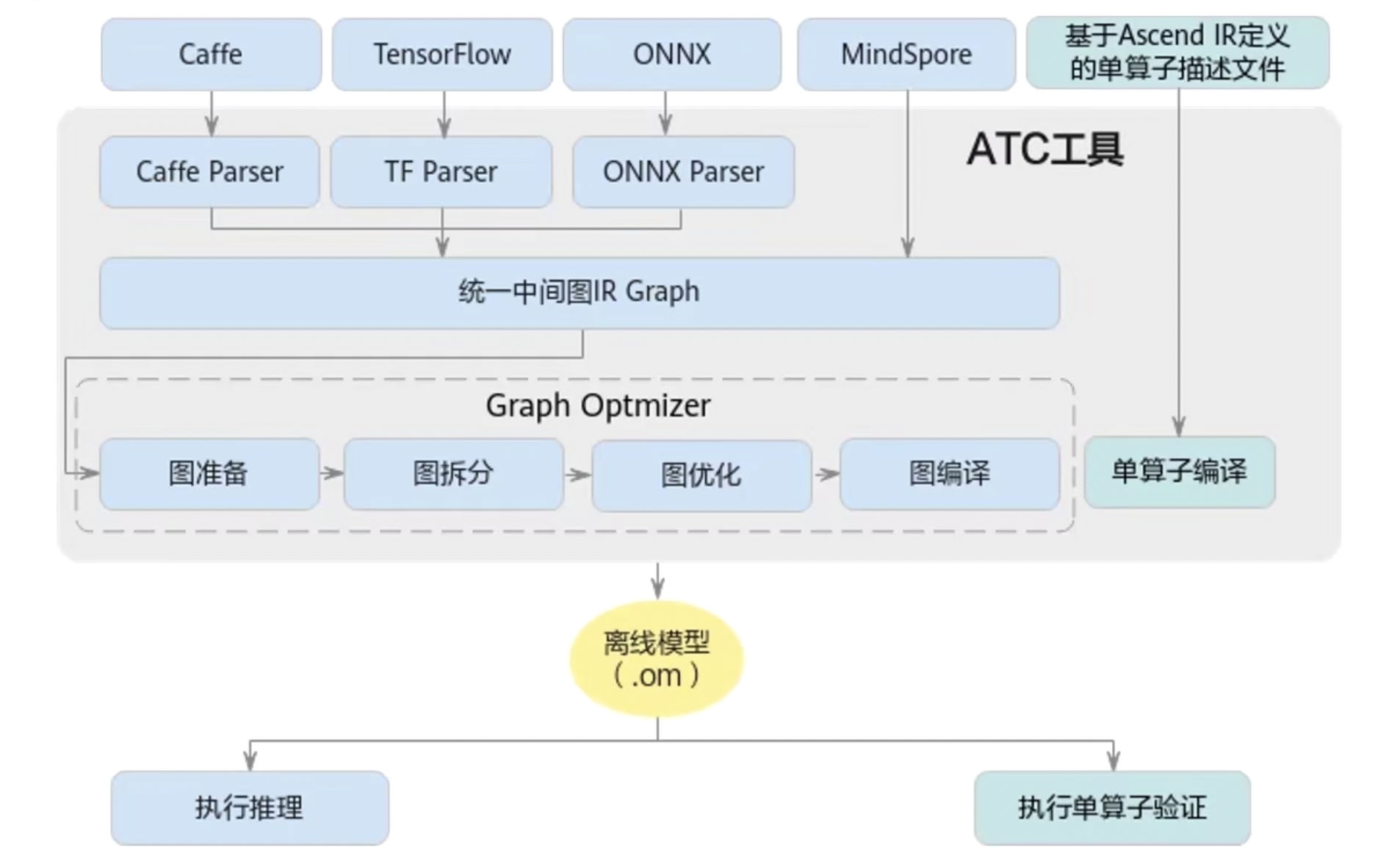
以上支持Caffe,TensorFlow,ONNX,MindSpore四个框架转化为离线模型(.om)。
- Caffe需要的文件:model.protoxt(caffe网络模型结构)、model.caffemodel(caffe网络模型权重)
- TensorFlow需要的文件:model.pb(包含TensorFlow模型的网络结构和权重)
- ONNX需要的文件(代表Pytorch框架):model.pt、model.pth –> model.onnx(包含ONNX模型的计算图和权重)
- MindSpore需要的文件(华为自家的框架):model.air
需要注意的是MindSpore训练出来的模型文件有两种:.air和.mindir,其中.air经过转化之后可以用于离线推理,.mindir经过转化之后可以用于在线推理。
离线推理和在线推理的区别
在线推理是在AI框架内执行推理的场景,这通常只能用于验证结果。不利用在设备上进行迁移,因为它需要依赖厚重的AI框架,也没有对模型的推理速度进行优化。而离线模型不依赖于AI框架(需要推理框架,但通常在设备上会集成),可以直接在设备上进行推理。
在线推理类似于pytorch模型的推理,离线推理类似于NVIDIA的TensorRT的推理。
使用MindStudio进行模型转换
模型转化的过程已经在开发环境部署中介绍过了,不赘述。模型转换成功之后会在命令行提示的目录下生成.om离线模型文件和ModelConvert.txt模型转化日志文件。
ATC模型转换-高手进阶
- 如何在命令行窗口使用ATC工具?
- 如何在模型转换的过程中加入一点动态输入形状信息?
- 如何在模型转换过程中把一些预处理动作加入到模型中?
命令行(CLI)调用ATC
在命令行窗口调用ATC工具,首先需要配置一些环境变量。这些环境变量在安装CANN-toolkit的时候已经展示过了,是第三组环境变量,需要把这些环境变量配置到~/.bashrc中,再source一下。
使用ATC工具的注意事项:
-
支持原始框架类型为Caffe、TensorFlow、MindSpore、ONNX的模型转换。
当原始框架为Caffe、MindSpore、ONNX时,输入数据类型为FP32,FP16(通过设置入参
--input_fp16_nodes实现,MindSpore框架不支持该参数)、UINT8(通过配置数据预处理实现)。当原始框架为TensorFlow时,输入数据类型为FP16、FP32、UINT8、INT32、BOOL(原始框架类型为TensorFlow时,不支持输入输出数据类型为INT64,需要用户自行将INT64修改为INT32类型)。
-
当原始框架为Caffe时,模型文件(.prototxt)和权重文件(.caffemodel)的输出名字、输出类型必须保持一致(名称包括大小写也要保持一致)。
-
当原始框架为TensorFlow时,只支持FrozenGraphDef(.pb)格式。
-
不支持动态shape的输入,模型转换时需要指定固定数值。
-
对于Caffe框架网络模型:输入数据最大支持四维,转维算子(reshape、expanddim等)不能输出五维。
-
模型中的所有层算子除了const算子外,输入和输出需要满足
dim != 0。 -
只支持算子规格参考中的算子,并满足算子限制条件。
ATC模型转换命令举例:
- CAFFE模型转换:
|
|
- TensorFlow模型转换:
|
|
- ONNX模型转换:
|
|
- MindSpore模型转换:
|
|
其中output参数代表的是输出离线模型的文件夹位置, soc_version代表要跑在哪一个昇腾AI处理器上,““里面的input代表的是输入节点的名字。
- 查看昇腾芯片的详细信息
|
|
返回信息中“Chip Name”对应取值即为<soc_version>。使用atc命令转换模型时,实际配置的<soc_version>值,要去掉“Chip Name”对应取值中的空格,例如“Chip Name”对应取值为Ascend xxx yyy,实际配置的<soc_version>值为Ascendxxxyyy。
|
|
动态shape
图片推理全过程:
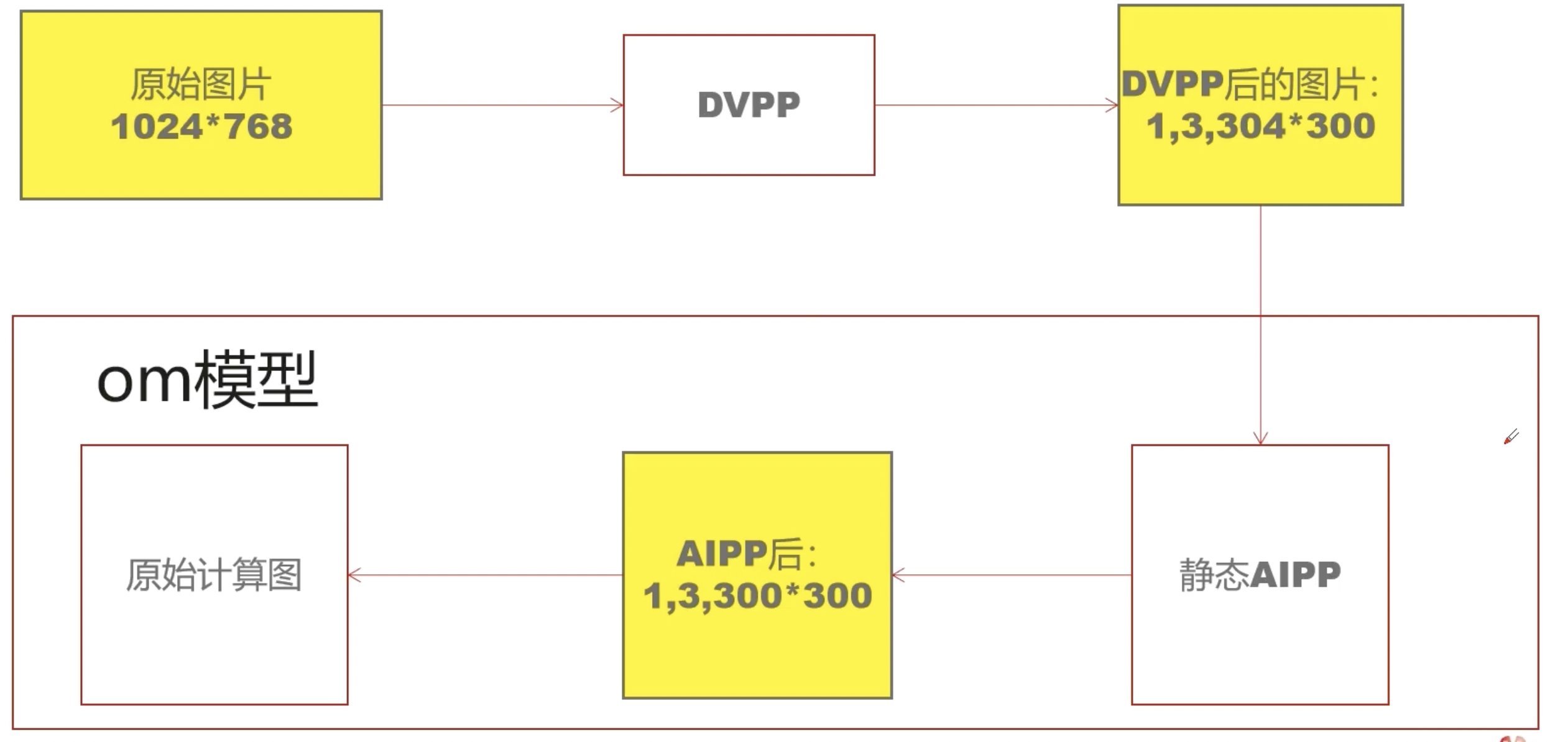
DVPP的过程是对图片进行resize或者crop,但此过程需要进行内存对齐(16*2),对齐之后图片的大小变为了$304\times 300$。对齐过程如下:
|
|
om模型的组成:静态AIPP和原始计算图
om模型的输入能否实现动态Batch或者动态宽高或者动态维度?
四个动态的兼容性:

从上图可以看出,动态AIPP只能和动态Batch或者动态分辨率配合使用!
动态Batch
在MindStudio模型转换的过程中,将输入数据data写为(-1, 3, 224, 224),然后在Dynamic Batch栏中填入1, 2, 4, 8等。
动态分辨率
同样在输入数据data中写为(1, 3, -1, -1),然后在Dynamic Image Size栏中填入512, 512; 600, 600; 800, 800。
动态维度
某些推理场景为非计算机视觉类,排布格式不一定是NCHW。如果需要动态决定输入数据维度,则需要用到AscendCL动态维度特性。
注意动态维度不能和任何其他动态特性(动态Batch、动态分辨率、动态AIPP)功能混用。
动态维度必须使用CLI方式转:
|
|
动态维度必须指定-input_format=ND
AIPP
AIPP (Artificial Intelligence Pre-Processing)智能图像预处理,用于在Al Core上完成图像预处理,包括改变图像尺寸、色域转换 (转换图像格式)、减均值/乘系数(改变图像像素),数据处理之后再进行真正的模型推理。
该模块功能与DVPP相似,都是用于图像数据预处理,但与DVPP相比,由于DVPP各组件基于处理速度和处理占有量的考虑,对输出有特殊的限制,如输出图片需要长宽对齐,且其输出格式通常为YUV420SP 等格式。这样的设定虽在视频分析的场景下有非常广阔的输入,但深度学习模型的输入通常为RGB或BRG,且输入图片尺寸各异,因此ATC工具流程中提供了AIPP功能模块。
与DVPP不同的是,AIPP主要用于在Al Core上完成数据预处理,通过AIPP提供的色域转换功能,输出满足要求的图片格式;通过改变像尺寸中的补边 (Padding)功能,输出满足长宽对齐的图片等,AIPP的出现是对DVPP能力的有效补充。
AIPP根据配置方式不同,分为静态AIPP和动态AIPP;如果要将原始图片输出为满足推理要求的图片格式,则需要使用色域转换功能:
如果要输出固定大小的图片,则需要使用AIPP提供的Crop(抠图)、Padding(补边)功能。
MindStudio中的AIPP:
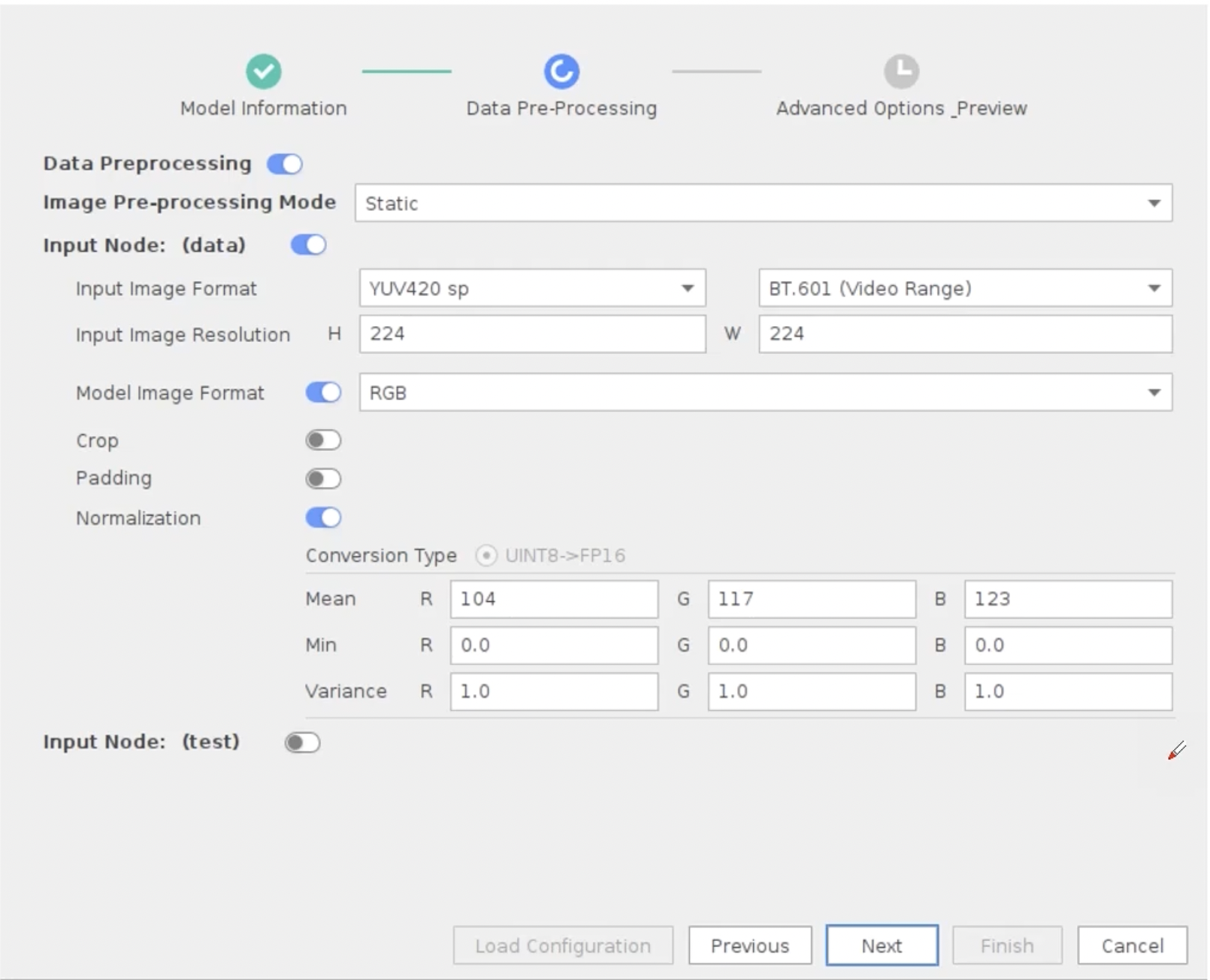
在Input Node中的的Format和Resolution都是指进入AIPP的格式和分辨率,该分辨率是DVPP处理后内存对齐过的尺寸。Model Image Format指的是你的模型输入需要的色域格式,该部分如果和Input Image Format不同,则AIPP会自动转换。Normalization指的是输入归一化参数。
控制台中的AIPP:
- 首先需要设置一个
insert_op.cfg文件:
|
|
CLI模型转换中加入AIPP预处理
|
|
最后修改于 2023-08-10

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。