PyTorch学习笔记
PyTorch安装及环境配置
conda环境安装
这里我们使用的anaconda,目前它也已经适配了apple芯片。所以我在我的M1 Pro的电脑上将miniforge3的方案替换成了anaconda3。官网:https://www.anaconda.com/
Windows端无需多说,苹果端如果是apple芯片,选择M1版本,如果是intel芯片,选择普通版本。
下载完成之后安装,需要配置一下环境变量(MacOS)。
首先进入根目录,并配置环境变量:
1
2
|
> cd ~
> vim ~/.zshrc
|
在配置文件中加入一行:
1
2
3
|
export PATH="/Users/caixiongjiang/opt/anaconda3:$PATH"
# 其中caixiongjiang是你的用户名
# vim中按i进行编辑模式,按Ese推出编辑模式,在普通模式下输入“:wq”表示保存并退出
|
启动环境配置,并配置国内镜像源:
1
2
3
4
5
6
7
8
|
> source ~/.zshrc
> conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
> conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
> conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
> conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
> conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
> conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
> conda config --set show_channel_urls yes
|
输入如下:
1
2
|
> conda info
# 最左边出现一个“(base)”表示已经成功了!
|
使用conda创建并管理不同的环境
创建环境:
1
2
3
4
5
6
7
8
9
10
|
# 创建一个python3.9的环境
> conda create -n pytorch python=3.9
# 切换环境
> conda activate pytorch
# 查看环境列表和当前使用环境
> conda info -e
# conda environments:
#
base /Users/caixiongjiang/opt/anaconda3
pytorch * /Users/caixiongjiang/opt/anaconda3/envs/pytorch
|
PyTorh安装
- Windows端:PyTorch自带CUDA工具加速,如果想要使用GPU做深度学习,需要下载带有CUDA的版本。
首先是只用CPU的版本:
1
|
> conda install pytorch torchvision torchaudio cpuonly -c pytorch
|
带GPU加速的版本(选择一个CUDA11.3的版本):
1
|
> conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
|
如果是普通intel芯片的电脑(安装正式版):
1
|
> conda install pytorch torchvision -c pytorch
|
如果是苹果的M1系列的芯片(安装预览版,2022年5月发布):
1
|
> conda install pytorch torchvision -c pytorch-nightly
|
-
检查pytorch是否可用:
1
2
3
4
5
6
7
8
|
# 切换到pytorch环境
> conda activate pytorch
# 进入python环境
> python
> import torch
# 是否可以使用GPU加速
> torch.cuda.is_avaliable()
True # True则代表可以使用
|
1
2
3
4
5
6
7
8
|
# 切换到pytorch环境
> conda activate pytorch
# 进入python环境
> python
> import torch
# 是否可以使用GPU加速
> torch.device('mps')
device(type='mps') #可以使用苹果自带的apple芯片进行GPU加速
|
Jupyter环境安装
因为annaconda是自带jupyter环境的,但是我们的新建的pytorch环境里面并没有支持jupyter环境的包,那就下载一下吧:
1
2
3
4
|
> conda activate pytorch
> conda install nb_conda
# 启动jupyter notebook
> jupyter notebook
|
在新建代码时,点击新建可以选择先前创建的环境。
Pytorch语法
Package工具
一个包里有有几个分隔区,每个分隔区里有几个工具箱。如何查看并使用工具箱:
- dir()函数,能让我们知道工具箱以及工具箱分隔区有什么东西。
- help()函数,能让我们知道每个工具是如何使用的,工具的使用方法。
Python文件vsPython控制台vsJupyter Notebook
如果代码是以块一个整体运行的话:
- Python文件的块是所有行的代码
- Python控制台的块是每一行的代码
- Jupyter Notebook的块是需要自己定义的,每一次in都是一个块
需要注意的是Python控制台是可以看到变量的信息的,和matlab相似。
PyTorch读取/加载数据
- Dataset:提供一种方式去获取数据其label值
- 如何获取每一个数据及其label
- 告诉我们总共有多少数据
- Dataloader:为神经网络提供不同的数据形式
Dataset代码实战
首先需要介绍一点Python中类的知识:
在Python中,如果想实现创建类似于序列和映射的类(可以迭代以及通过[下标]返回元素),可以通过重写魔法方法的方式去实现。常见的魔法方法包括__getitem__()、setitem()、delitem()、len(),它们的函数功能为:
1)__getitem__(self,key):返回键对应的值;
2)__len__():返回元素的数量;
3)__delitem__(self,key):删除给定键对应的元素;
4)__setitem__(self,key,value):设置给定键的值。
torch.utils.data.Dataset是PyTorch中用来表示数据集的抽象类,Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中从而使DataLoader类更加快捷的对数据进行操作。当处理自定义的数据集的时候必须继承Dataset,然后重写 len()和__getitem__()函数。
1)__len__(): 使得len(dataset)返回数据集的大小;
2)__getitem__():使得支持dataset[i]能够返回第i个数据样本这样的下标操作,在__getitem__()函数中完成图片的读取工作可以减小内存开销,只要在需要用到的时候才将图片读入。
深度学习训练数据集一般有两种表现形式,假设数据有c类:
- 1.数据和标签混合:
训练数据集下面会有c个文件夹的训练数据。标签通过文件的名称来定,数据则对应标签文件夹目录下的数据。
- 2.数据和标签分离:
训练数据集下面会有2$\times$c个文件夹,c个文件放的不同类训练数据,另外c个类的文件夹则是不同类的训练标签。训练数据和训练标签的前缀是一一对应的,标签一般放在.txt文件夹中。
下面针对1写一个加载数据的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir) # 对地址进行拼接
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name) # 每一张图片相对于程序的相对路径
img = Image.open(img_item_path) # 读取图片
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
|
常见的深度学习工具使用
Tensorboard安装
1
2
|
> conda activate pytorch
> pip3 install tensorboard
|
Tensorboard使用
先写一个简单的示例代码:
1
2
3
4
5
6
7
8
9
10
11
|
from torch.utils.tensorboard import SummaryWriter
# 如果要在logs后面加子文件可以加"/文件夹名"
writer = SummaryWriter("logs")
# writer.add_image()
# y = x
for i in range(100):
# 这里的第一个参数代表标题,第二个参数代表y轴的真实值,第三个参数代表x轴的真实值
writer.add_scalar("y = x", i, i)
writer.close()
|
运行这段代码,就可以在代码的同级目录下,多出一个logs的文件夹,文件夹的名字是代码中设定的。
那么如何使用Tensorboard来查看图像呢?
首先需要打开PyCharm中的Terminal,输入:
1
2
3
4
|
# logdir代表事件文件所在的文件夹 port代表自定义端口
# 这里在=后面使用绝对路径和相对路径都是OK的
> tensorboard --logdir=logs --port=9090
# 运行之后会发现一个本地的服务器地址,可以在浏览器打开
|
通常来说,add_image一般是用来观察训练结果的。
写一段示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs/2")
image_path = "dataset/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
# 这里的dataformats=”HWC“代表数据的shape为高度,宽度,通道数
# 默认的shape为通道数,高度,宽度
# 数字1代表的是step
# 第二个参数传入时一般为张量,或者numpy类型
writer.add_image("test", img_array, 1, dataformats="HWC")
writer.close()
|
Transforms一般形式是在一个.py文件里使用,它的功能类似于一个工具箱,能对图片做一些处理。工具箱里包含totensor,resize等工具,图片经过工具的处理会输出一个我们想要的结果。
看一个简单的使用案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
import cv2 as cv
# python的用法 -> tensor数据类型
# 通过 transforms.ToTensor 解决两个问题
# 2.为什么需要Tensor数据类型
# 绝对路径 /Users/caixiongjiang/PycharmProjects/learn-pytorch/dataset/train/ants_image/0013035.jpg
# 相对路径 dataset/train/ants_image/0013035.jpg
# 读取成jpg格式
img_path = "dataset/train/ants_image/0013035.jpg"
img = Image.open(img_path)
print(img)
# 读取成numpy格式
cv_img = cv.imread(img_path)
# 1.transforms该如何使用
tensor_trans = transforms.ToTensor() # 创建具体的工具(实例化)
tensor_img = tensor_trans(img) # 使用工具
print(tensor_img)
writer = SummaryWriter("logs/3")
writer.add_image("Tensor_img", tensor_img)
writer.close()
# 2.为什么需要Tensor数据类型
# tensor包含了一些神经网络中的一些信息,比如反向传播等
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs/3")
img = Image.open("dataset/val/bees/26589803_5ba7000313.jpg")
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize
# 第一个参数是均值,第二个参数是方差。
# 这里每个参数都有三个,是因为输入的维度3维的。
'''
output[channel] = (input[channel] - mean[channel]) / std[channel]
'''
print("变化前:" + str(img_tensor[0][0][0]))
trans_norm = transforms.Normalize([6, 3, 2], [9, 3, 5])
img_norm = trans_norm(img_tensor)
print("变化后:" + str(img_tensor[0][0][0]))
writer.add_image("Normalize", img_norm, 2)
# Resize
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize, 0)
print(img_resize)
# Compose - resize - 2
'''
Compose()用法:
相当于是多个转化操作合并到一个compose()函数中!
Compose()中的参数需要是一个列表,列表中的数据类型是transforms类型
所以得到,Compose([transforms参数1, transforms参数2, ...])
'''
trans_resize_2 = transforms.Resize(512) # transforms.Resize(x):将图片短边缩放至x,长宽比保持不变
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Compose", img_resize_2, 1)
# RandomCrop 随机裁剪
trans_random = transforms.RandomCrop((300, 450)) # 一个参数时,默认为a×a,两个参数则为a×b
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCropHW", img_crop, i)
writer.close()
|
torchvison中的数据集使用
在PyTorch的torchvision中自带了很多数据集,我们怎么使用它。这里可以参考官方的文档:https://pytorch.org/vision/stable/datasets.html
我们这里使用一个CIFAR10的数据集进行演示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# root代表保存路径
train_set = torchvision.datasets.CIFAR10(root="./torchvision_datasets_train", transform=dataset_transform, train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root="./torchvison_datasets_test", transform=dataset_transform, train=False, download=True)
# print(test_set[0])
# print(test_set.classes)
# img, target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(test_set[0])
writer = SummaryWriter("logs/p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
|
DataLoader的使用
dataset可以理解为一个数据集,而dataloader可以理解为将数据集中的数据加载到神经网络中。dataloader的官方文档如下:https://pytorch.org/docs/stable/data.html?highlight=dataloader#torch.utils.data.DataLoader
来看一个使用案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./torchvision_datasets_test", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# drop_last如果为True,代表最后一次数据集的batch不满batch-size,会被舍去
# num_workers代表并行处理的数量
# shuffle指打乱随机
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("logs/dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, target = data
# print(img.shape)
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step += 1
writer.close()
|
PyTorch写神经网络
神经网络基本骨架——nn.Module使用
首先,先贴一下神经网络模型的官方文档:https://pytorch.org/docs/stable/nn.html
主要写一下Pytorch中模型的写法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import torch
import torch.nn as nn
import torch.nn.functional as F
class MyModel(nn.Module):
"""
conv代表卷积层
relu代表ReLU激活函数
"""
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
class Cai(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
return output
test_md = Cai()
x = torch.tensor(1.0)
output = test_md(x)
print(output)
|
神经网络-卷积层示例
Pytorch中的Conv2d的对应函数(Tensor通道排列顺序是:[batch, channel, height, width]):
1
2
3
4
5
6
7
8
9
|
torch.nn.Conv2d(in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros')
|
每个参数代表的含义如下:
in_channels参数代表输入特征矩阵的深度即channel,比如输入一张RGB彩色图像,那in_channels = 3;
out_channels参数代表卷积核的个数,使用n个卷积核输出的特征矩阵深度即channel就是n;
kernel_size参数代表卷积核的尺寸,输入可以是int类型如3 代表卷积核的height = width = 3,也可以是tuple类型如(3, 5)代表卷积核的height = 3,width = 5;
stride参数代表卷积核的步距默认为1,和kernel_size一样输入可以是int类型,也可以是tuple类型,这里注意,若为tuple类型即第一个int用于高度尺寸,第二个int用于宽度尺寸;
padding参数代表在输入特征矩阵四周补零的情况默认为0,同样输入可以为int型如1 代表上下方向各补一行0元素,左右方向各补一列0像素(即补一圈0),如果输入为tuple型如(2, 1) 代表在上方补两行下方补两行,左边补一列,右边补一列。可见下图,padding[0]是在H高度方向两侧填充的,padding[1]是在W宽度方向两侧填充的;
在Pytorch中,**dilation = 1等同于没有dilation的标准卷积,dilation = 2等同于计算不同点之间的差距时会进行膨胀操作。**用一个例子来说明:
在一个维度上,一个大小为3的过滤器w会对输入的x进行如下计算:w[0] * x[0] + w[1] * x[1] + w[2] * x[2]。若dilation = 1,过滤器会计算:w[0] * x[0] + w[1] * x[2] + w[2] * x[4];换句话说,在不同点之间有一个1的差距。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 将二维矩阵变为batch-size为1,通道为1,矩阵大小为5×5
input = torch.reshape(input, (1, 1, 5, 5))
# 将二维矩阵变为batch-size为1,通道为1,矩阵大小为3×3
kernel = torch.reshape(kernel, (1, 1, 3, 3))
output = F.conv2d(input, kernel, stride=1)
print(output)
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
# print(input.shape)
# print(kernel.shape)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Cai(torch.nn.Module):
def __init__(self):
super(Cai, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
cai = Cai()
# print(cai)
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
output = cai(imgs)
# torch.size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.size([64, 6, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1
writer.close()
|
卷积网络-最大池化
首先解释一下最大池化,就是对输入图像做匹配,并取出匹配结果的最大值。它的目的是为了保留输入的特征,但是同时减少数据量。
MaxPool2d这个类的实现十分简单。
我们先来看一下基本参数,一共六个:
kernel_size :表示做最大池化的窗口大小,可以是单个值,也可以是tuple元组
stride :步长,可以是单个值,也可以是tuple元组,默认值为None。也就是如果不设置其就等于kernel_size的大小
padding :填充,可以是单个值,也可以是tuple元组,默认padding=0
dilation :控制窗口中元素匹配的步幅
return_indices :布尔类型,返回最大值位置索引
ceil_mode :布尔类型,为True,用向上取整的方法,计算输出形状;默认是向下取整。
这里特别说明一下ceil_mode,如果ceil_mode=True时,当输入图像被匹配的形状不足时,我们对这组数据的池化结果是保留的;diation和卷积中的功能是一样的,默认都是不膨胀。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 1、 ./是当前目录 2、 ../是父级目录 3、 /是根目录 根目录是指逻辑驱动器的最上一层目录
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Cai(torch.nn.Module):
def __init__(self):
super(Cai, self).__init__()
self.maxpool1 = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
cai = Cai()
writer = SummaryWriter("../logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
output = cai(imgs)
writer.add_images("input", imgs, step)
writer.add_images("output", output, step)
step += 1
writer.close()
|
神经网络-非线性激活
其实就是如何使用激活函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
import torch
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, -0.5],
[-1, 3]])
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Cai(torch.nn.Module):
def __init__(self):
super(Cai, self).__init__()
# inplace = True代表原地操作,值进行覆盖 inplace = False代表激活结果传给另一个变量(默认)
self.relu1 = torch.nn.ReLU(inplace=False)
self.sigmoid1 = torch.nn.Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
cai = Cai()
writer = SummaryWriter("../logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = cai(imgs)
writer.add_images("output",output, step)
step += 1
writer.close()
|
Sequential使用以及神经网络实战搭建
Sequential其实是将神经网络的模型放在一个序列里面,简洁易懂。
实战的话就是针对我们之前一直使用的数据集CIFAR10来写一个简洁一点的神经网络模型。
使用的网络模型结构CIFAR-quick model,如下图所示:
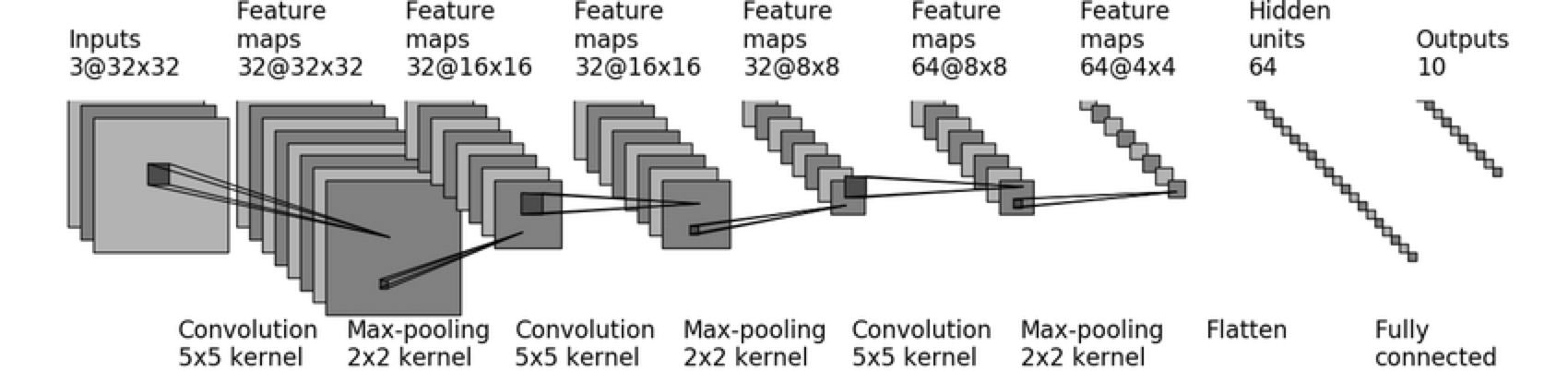
建立模型的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
import torch
from torch.utils.tensorboard import SummaryWriter
class Cai(torch.nn.Module):
def __init__(self):
super(Cai, self).__init__()
self.module1 = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32, 32, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32, 64, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Flatten(),
torch.nn.Linear(1024, 64),
torch.nn.Linear(64, 10)
)
def forward(self, x):
x = self.module1(x)
return x
cai = Cai()
print(cai)
input = torch.ones((64, 3, 32, 32))
output = cai(input)
print(output.shape)
# 生成计算图
writer = SummaryWriter("../logs_seq")
writer.add_graph(cai, input)
writer.close()
|
神经网络-损失函数&反向传播
神经网络就是一个不断迭代的过程,损失函数就是它的一个指标,迭代的过程就是让这个指标越来越小。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import torch
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = torch.nn.L1Loss(reduction="sum")
result = loss(inputs, targets)
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
# 当你应用一个分类问题的时候,分成c类,使用交叉熵
# -0.2 + ln(exp(0.1) + exp(0.2) + exp(0.3))
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
print(result)
print(result_mse)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
import torch
from torch import nn
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Cai(torch.nn.Module):
def __init__(self):
super(Cai, self).__init__()
self.module1 = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32, 32, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32, 64, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Flatten(),
torch.nn.Linear(1024, 64),
torch.nn.Linear(64, 10)
)
def forward(self, x):
x = self.module1(x)
return x
loss = nn.CrossEntropyLoss()
cai = Cai()
for data in dataloader:
imgs, targets = data
output = cai(imgs)
result_loss = loss(output, targets)
# 后向传播
result_loss.backward()
|
优化器
使用优化器,可以使用优化算法设置学习速率,自动计算反向传播,更新参数等。使用之前的CIFAR10 quick_model来计算梯度等,进行迭代。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
import torch
from torch import nn
import torchvision.datasets
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Cai(torch.nn.Module):
def __init__(self):
super(Cai, self).__init__()
self.module1 = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32, 32, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32, 64, 5, padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Flatten(),
torch.nn.Linear(1024, 64),
torch.nn.Linear(64, 10)
)
def forward(self, x):
x = self.module1(x)
return x
loss = nn.CrossEntropyLoss()
cai = Cai()
# 随机梯度下降
optim = torch.optim.SGD(cai.parameters(), lr=0.01)
for epoch in range(20):
# 每一轮学习中所有数据的loss
running_loss = 0.0
for data in dataloader:
imgs, targets = data
output = cai(imgs)
result_loss = loss(output, targets)
# 参数梯度重置为0
optim.zero_grad()
# 后向传播(计算梯度)
result_loss.backward()
# 更新参数
optim.step()
running_loss += result_loss
print(running_loss)
|
PyTorch网络模型修改和使用
PyTorch网络模型
在PyTorch中已经集成了许多经典的网络模型,在torchvision中有分类模型,语义分割模型,目标检测的模型。这次我们还是采用CIFAR10做一个分类模型,分类模型使用的是VGG模型中的vgg16。
torchvision.models.vgg16(***, weights: Optional[torchvision.models.vgg.VGG16_Weights] = None, progress: bool = True, **kwargs: Any)
参数:
- weight:默认为None值,代表没有预训练(该网络在其他公开数据集上运行一部分的结果)的权重。
- progress:训练的过程中是否显示进度条,默认为True
- **kwargs:传递给VGG基类的参数
使用vgg16网络对CIFAR10数据集训练:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
"""
本来想使用ImageNet数据集预训练VGG.vgg16网络模型,但由于数据集太大放弃了
然后训练CIFAR10数据集
"""
import torchvision
# 目前能通过此方法下载,必须外部下载,放到根目录下才行,而且ImageNet有100多个G的训练集,属实有点大。
# train_data = torchvision.datasets.ImageNet("../data_image_net", split="train", download=True,
# transform=torchvision.transforms.ToTensor())
from torch import nn
vgg16_false = torchvision.models.vgg16(weights=None)
vgg16_true = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights)
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
"""
由于VGG.vgg16是对1000个类进行分类,我们需要修改网络模型分成10类
可以使用添加一个线性层,也可以考虑修改最后的线性层
"""
# 模型增加层
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_true)
# 模型修改层
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
|
模型的保存和加载
model_save.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(weights=None)
# 保存方式1 (网络模型结构+参数)
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2(只保存网络模型的参数,字典的格式)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
# 保存自己的模型
class Cai(nn.Module):
def __init__(self):
super(Cai, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
cai = Cai()
torch.save(cai.state_dict(), "my_model.pth")
|
model_load.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import torch
import torchvision
from model_save import Cai
# 加载方式1->对应保存方式1
model1 = torch.load("vgg16_method1.pth")
print(model1)
# 加载方式2->对应保存方式2
vgg16 = torchvision.models.vgg16(weights=None)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
# 加载自己的模型
my_model = Cai()
my_model.load_state_dict(torch.load("my_model.pth"))
print(my_model)
|
完整的模型训练
完整的模型训练套路(CIFAR10数据集为例)
- 首先,先说一下分类问题特有的正确率检验,看一个例子就明白了:
1
2
3
4
5
6
7
8
9
10
11
|
import torch
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
print(outputs.argmax(1)) # 横向比较,找到较大的那个数的位置(从0开始)
print(outputs.argmax(0)) # 竖向比较,找到较大的那个数的位置(从0开始)
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print((preds == targets).sum())
|
完整的CIFAR10训练和测试,利用之前写过的CIFAR10 quick_model,训练10轮:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import torch
from torch import nn
# 搭建神经网络模型
class Cai(torch.nn.Module):
def __init__(self):
super(Cai, self).__init__()
self.module = torch.nn.Sequential(
nn.Conv2d(3, 32, (5, 5), padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, (5, 5), padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, (5, 5), padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.module(x)
return x
if __name__ == '__main__':
"""
main函数用于测试模型
"""
cai = Cai()
# 64张3通道32×32的图片
input = torch.ones((64, 3, 32, 32))
output = cai(input)
print(output.shape)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
cai = Cai()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器 SGD:随机梯度下降
# learning_rate = 0.01
# 1e-2 = 1×(10)^(-2) = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(cai.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练和测试的次数
total_train_step = 0
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
# 模型训练
for i in range(epoch):
print("-------------第{}轮训练开始--------------".format(i + 1))
# 训练步骤开始
cai.train() # 这句话是为了在网络中如果有drop_out或者batch_normal等层时才会起作用
for data in train_dataloader:
imgs, targets = data
outputs = cai(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
# 使用.item()取出tensor数据类型的内容
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
cai.eval() # 这句话是为了在网络中如果有drop_out或者batch_normal等层时才会起作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = cai(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
# 保存每一轮模型参数的结果
torch.save(cai, "cai_{}.pth".format(i + 1))
# torch.save(cai.static_dict(), "cai_{}.pth".format(i + 1))
print("模型已保存")
writer.close()
|
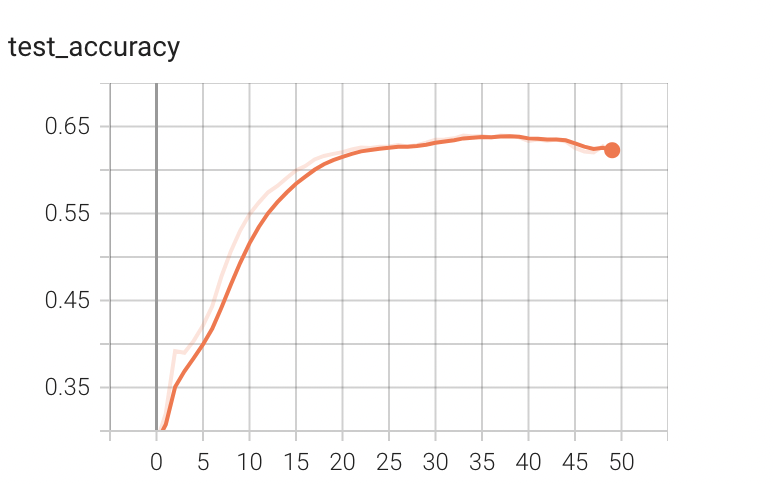
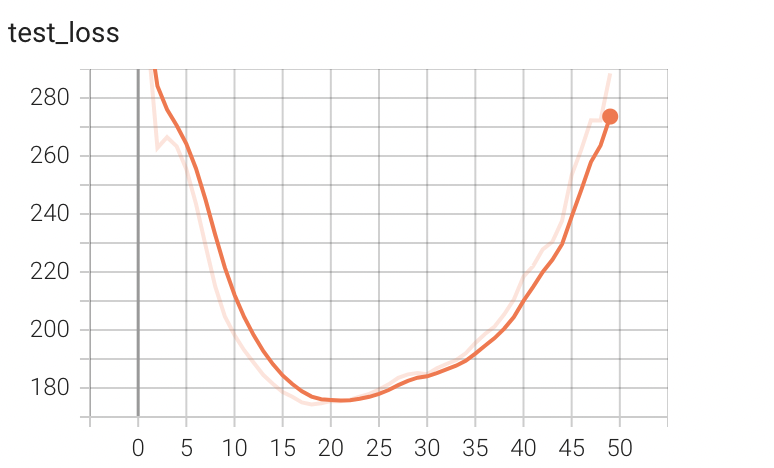
训练的tensorboard结果(10轮)如下,训练集50000张,测试集10000张:
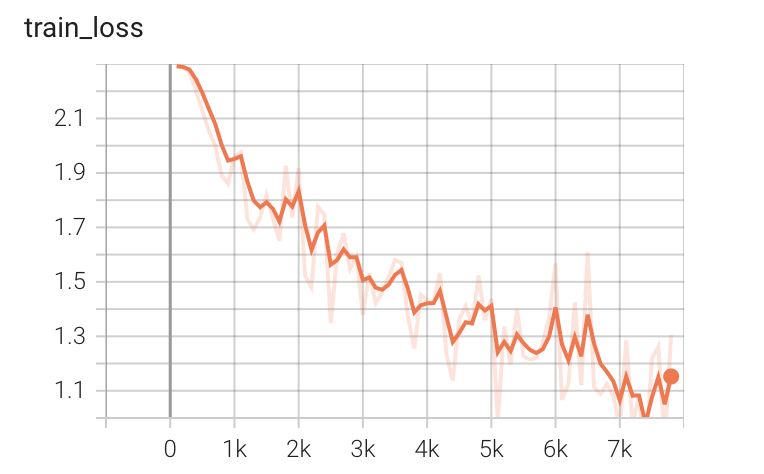

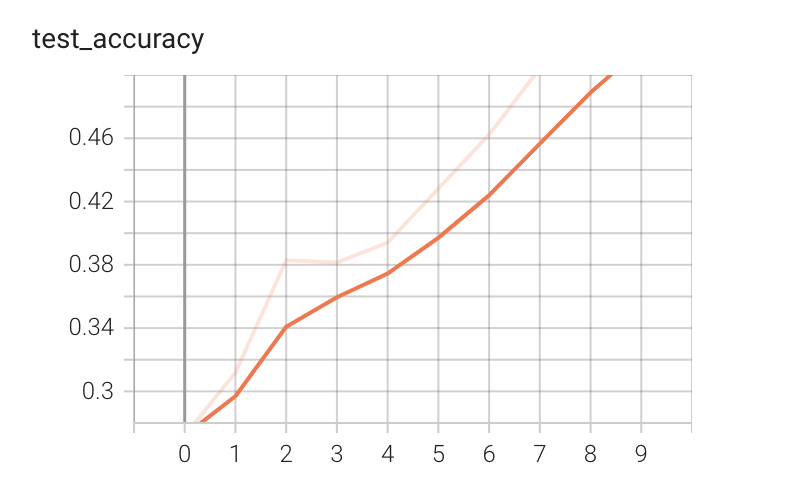
利用GPU进行训练
主要的思想就是将用到的模型,损失函数,数据都放到gpu上!
1
2
|
if torch.cuda.is_available():
model = model.cuda()
|
训练结果(10轮)如下,训练集50000张,测试集10000张:
运行时间:桌面端RTX 2060时间为76s
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import torch
# 返回得到默认的device
def get_default_device():
if torch.cuda.is_available():
return 'cuda'
elif getattr(torch.backends, 'mps', None) is not None and torch.backends.mps.is_available():
return 'mps'
else:
return 'cpu'
device = get_default_device()
model = Net()
model.to(device)
pred = model(X)
|
我的MBP上的代码需要改成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
|
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# 选择设备的函数
def get_default_device():
if torch.cuda.is_available():
return 'cuda'
elif getattr(torch.backends, 'mps', None) is not None and torch.backends.mps.is_available():
return 'mps'
else:
return 'cpu'
# 定义训练的设备
device = get_default_device()
# 准备数据集
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络模型
class Cai(torch.nn.Module):
def __init__(self):
super(Cai, self).__init__()
self.module = torch.nn.Sequential(
nn.Conv2d(3, 32, (5, 5), padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, (5, 5), padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, (5, 5), padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.module(x)
return x
# 创建网络模型
cai = Cai()
# 网络模型转移到苹果芯片的gpu
cai.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 损失函数转移到苹果芯片的gpu
loss_fn.to(device)
# 优化器 SGD:随机梯度下降
# learning_rate = 0.01
# 1e-2 = 1×(10)^(-2) = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(cai.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练和测试的次数
total_train_step = 0
total_test_step = 0
# 训练的轮数
epoch = 50
# 添加tensorboard
writer = SummaryWriter("../logs_train")
start_time = time.time()
# 模型训练
for i in range(epoch):
print("-------------第{}轮训练开始--------------".format(i + 1))
# 训练步骤开始
cai.train() # 这句话是为了在网络中如果有drop_out或者batch_normal等层时才会起作用
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = cai(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
# 使用.item()取出tensor数据类型的内容
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
cai.eval() # 这句话是为了在网络中如果有drop_out或者batch_normal等层时才会起作用
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = cai(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy.item()/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy.item()/test_data_size, total_test_step)
total_test_step += 1
# 保存每一轮模型参数的结果
# torch.save(cai, "cai_{}.pth".format(i + 1))
# torch.save(cai.static_dict(), "cai_{}.pth".format(i + 1))
print("模型已保存")
writer.close()
|
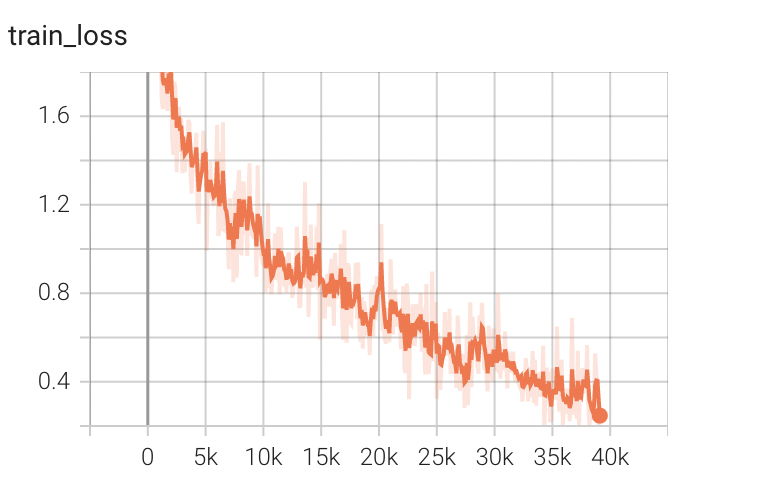
训练结果(10轮)如下,训练集50000张,测试集10000张:
运行时间:我的M1 pro的GPU上运行时间为54s
正确率:将epoch加到50轮,最高正确率为0.65
完整的模型验证套路
在网上找了一张狗的图片,放在test_imgs文件夹下,写一下验证套路代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import torch
import torchvision.transforms
from PIL import Image
from model import Cai
image_path = "../test_imgs/dog.png"
image = Image.open(image_path)
"""
png格式的图片是4个通道,在RGB通道外,还有一个透明度的通道。
所以要将4通道转化为3通道
"""
image = image.convert('RGB')
print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
# 加载网络模型,模型在'mps'环境下运行,如果用cpu验证,则需要指定device=’cpu‘
model = torch.load("cai_25.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1).item())
# 结果为5,为dog,正确预测
|
最后修改于 2022-07-29

本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。