深度学习(8-9节)
网络模型的优化
ML策略
当你采用一个分类器,得到的准确率为90%,如何提高它的准确率呢?以下有这么多的方法可以使用:
- 收集更多的数据
- 提高训练集的多样性(反例集)
- 尝试使用优化算法
- 使用规模更大或者更小的网络
- 使用正则化
- 修改网络结构
- 修改激活函数
- 改变隐藏层单元的数目
- …
修改的方法有很多,但是需要选择一个正确的并不容易。
正交化
如果将神经网络比作一个可调节的电视机,调整电视机的各种按钮来改变电视机的布局,色彩,亮度就如同在神经网络中调整各种超参数来查看神经网络的效果。
对于一个电视来说,我们需要慢慢调整(一个开关一个开关调整)才能将电视机调好,那么这种一个超参数调整,只能改变其神经网络的某个性质的形式就叫做正交化。
单一数字评估指标
理解一下两个概念,Precision和Recall。
Precison:中文为查准率,预测为真的模型中,有多少样本是真的,它的占比值。对于一个猫分类器来说就是,模型预测为猫的类型样本中,有多少占比为真正的猫。
Recall:中文为召回率,对于所有样本标签为真的情况下,有多少占比是你的模型正确预测出来的。对于一个猫分类器来说就是,在所有标签为真猫的样本中,有多少占比是你的模型正确预测的。
对于一个分类器来说,两个指标都同等重要,所以我们需要找到一个结合查准率和召回率的指标,也就是所谓的F1分数,公式如下:
$$
F1=\frac{2}{\frac1p+\frac1R}\
其中p代表查准率,R代表召回率,计算方式在数学上称为调和平均数
$$
这样算出来的F1分数来判断网络的性能更加合理,称这种形式为单一数字评估指标。
再举一个例子,如下图:
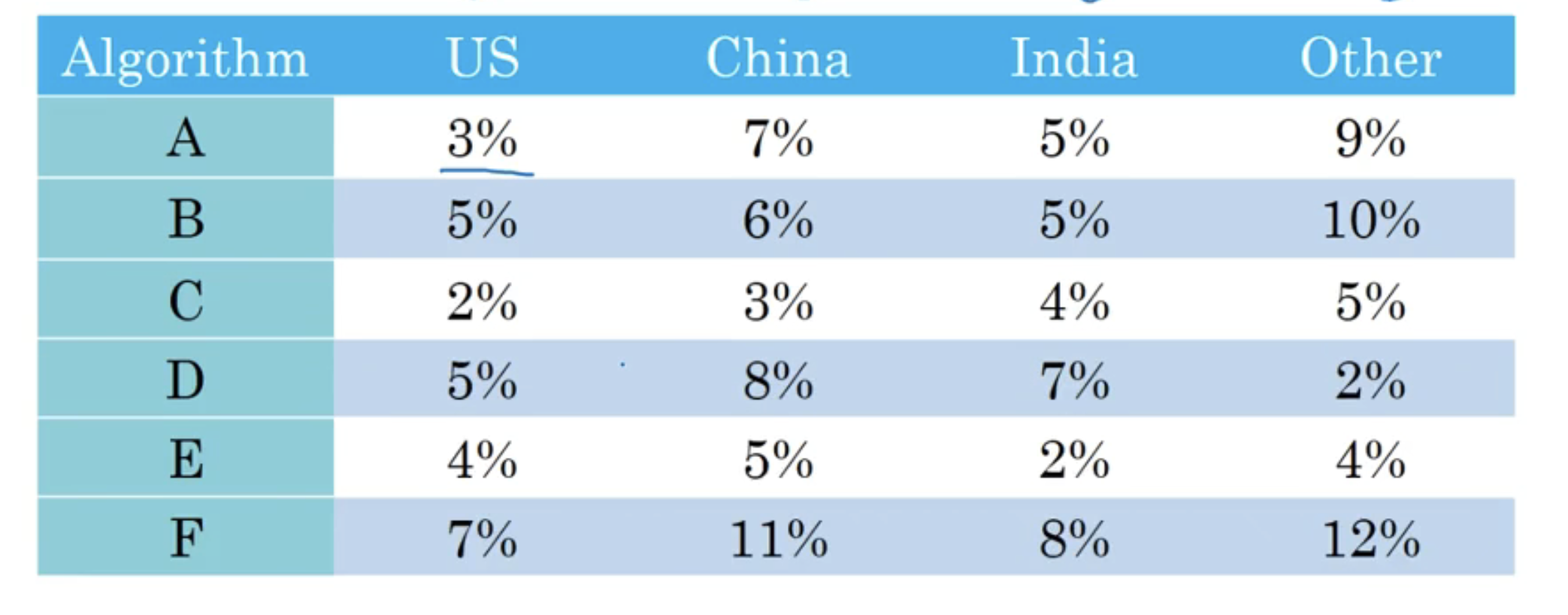
算法在不同地区的错误率都不同,无法统一进行比较,那我们就将其整合为一个值,就是做平均之后再做比较。
满足和优化指标
对于某些多个指标的情况,我们想建立单一实数评估指标是非常困难的。比如,准确率和运行时间,想要合并为一个成本指标是很困难的,因为我们并不知道两个指标哪个更重要,或者说两个指标之间的关联性。所以我们可以采用满足和优化指标,在该例中就是在满足运行时间在多少毫秒之内,优化准确率,这样就可以找到最优的那个算法。
划分训练/开发/测试集
- 划分dev/test sets:
假设你要开发一个猫分类器,需要在不同区域进行运营:美国,英国,中国,印度,澳大利亚等。你如何设立开发集和测试集呢?
如果你在8个区域中随机选取4个区域作为开发集,4个区域作为测试集,效果可能是非常糟糕的。我们选取的原则是让开发集和测试集尽量来自同一分布。所以我们的做法一般是将所有数据随机洗牌,放入开发集和测试集,这样开发集和测试集都有来自8个区域的数据。
- 开发集和测试的大小:
在机器学习中,会有一条七三分的比例划分训练集和测试集,如果有开发集,则会按照6:2:2的比例来划分训练集,开发集,测试集。但在如今的数据量在百万级别的情况下,这样做会更加合理:98%作为训练集,1%开发集,%1测试集。
- 训练集,开发集和测试集的目的:
开发集是为了指定产品的优化目标,训练集决定了你向优化目标迭代的速度,测试集是为了评估投产系统的性能。
何时改变开发_测试集和指标
假设一个猫分类器,使用了算法A和算法B,它们都分别采用分类错误率来衡量算法的性能。算法A的错误率为3%,算法B的错误率为5%,但是算法A在错误分类的图片里,将色情图片分为了猫的图片,这是用户不能接受的。所以在这种情况下,即使你的算法在开发集上的指标更好,依然被认为是不好的产品。当你的指标错误地预测算法,就是你需要修改开发_测试集和指标的时候。
那么如何修改指标?
我们可能会对目标错误率设置一个$W$来赋予不同的图片以不同的权重:
$$
W^{(i)}=\begin{cases}
1,&如果x^{(i)}不是色情图片\
10,&如果x^{(i)}是色情图片
\end{cases}
$$
需要注意的是在目标函数上加上$W$,也需要修改归一化常数
贝叶斯误差和可避免偏差
假设一个两个不同的模型,在训练集和开发集上的错误率如下:
一个问题的错误率是有一个贝叶斯误差(理论最小误差),在大多数时候人类识别的错误率是接近贝叶斯误差的。
| 问题1的错误率 | 问题2 | |
|---|---|---|
| 训练集 | 8% | 8% |
| 开发集 | 10% | 10% |
| 人类错误率相近 | 1% | 7.5% |
在训练集和人类错误率之间的差值被称为可避免偏差,训练集和开发集之间的误差被认为是需要更加优化方差。问题1,训练集与人类错误率相差较远,是训练欠拟合,可以加大训练网络或者迭代时间等来缩小;问题2中的训练集8%和测试集10%,略微过拟合,可以用正则化来降低拟合程度。
那么如果要把人类错误率作为贝叶斯错误的替代,该如何定义人类错误率呢?
假设一个医学图像分类的例子:
-
普通的人类在该任务上达到了3%的错误率。
-
普通的医生能达到1%的错误率
-
经验丰富的医生能达到0.7%的错误率
-
一个经验丰富的医生团队能达到0.5%的错误率
那么在上述的例子中,该如何界定人类水平错误率呢?
在我们的定义中,人类水平错误率应该逼近理论错误率的极限,那么我们就将最低的0.5%来估计贝叶斯错误率。
改善模型的表现
改善模型的表现,需要满足很多条件:
1.首先,你的算法需要对训练集的拟合很好,这可以看成是你做到的可避免偏差很低。
2.在训练集中做的很好的情况下,然后推广到开发集和测试集的效果也很好,也就是方差不是太大。
- 降低可避免偏差的方法:
- 训练更大的模型
- 训练更久,或者使用更好的优化算法来加快训练速度
- 寻找更好的神经网络架构(比如RNN,CNN)/寻找一组更好的超参数
- 降低方差的方法:
- 使用更多数据
- 正则化
- 数据扩增
- 修改网络架构/寻找不同的超参数组合
修改模型的错误
误差分析
如果你的猫分类器识别错误了100张图片,你的识别错误率为10%。如果只有5张图片错误识别成狗,那么针对狗做算法优化最多从10%优化到9.5%;如果有50张图片错误识别成狗,那么针对狗做算法优化可以从10%优化到5%。很显然,对于第一种情况优化方式是不合理的,第二种情况优化方式是合理的。
一般会在开发集的预测错误样本上进行误差分析,有时候人工进行误差分析是很有效果的。
清除标注错误的数据
如果你的训练数据集出现标注错误的数据,比如一张狗的图片被你标记成了猫。其实对于数据较多的数据集,有少量数据标注错误其实对结果影响不大。深度学习算法对随机标注错误不敏感,但是对于系统性的标注错误就很敏感。
如果你的开发集或测试集出现标注错误的数据,就要看情况了。如果严重影响了对你开发集上评估算法的能力,那应该花时间去修复标记错误。其实也是通过错误预测的样本进行分析,看看有多少错误是因为标注数据导致的,如果占比很低,可以不进行错误的修改,如果占比较高,可以进行错误的修改。
在不同的划分上训练并测试
目前很多深度学习团队可能将训练集和开发集分开,来自不同的数据分布。那么如何解决两种数据分布不同的数据对算法性能的影响呢?
- 第一种做法是将两组数据合并在一起:假设你有200000张高清的猫的图片和10000张模糊的不专业的猫的图片,合并之后就有210000张图片。进行随机洗牌后,训练集包含205000张图片,开发集和测试集各包含2500张图片。这样做的好处是数据集都来自于同一分布,更好管理;缺点是开发集的样本大部分为你从网上下载的高清图片,并不是你关注的数据分布,显然这是不合理的。
- 第二种做法是将200000张网图和5000/2500张不专业的图一起作为训练集,然后5000张不专业图1:1用作开发集和测试集。优点是你的开发集的数据分布是你想要的,缺点是你的训练集分布和开发测试集分布不同。
根据经验,一般选择第二种做法会更加好!
不匹配数据划分的偏差和方差
我们已经学会了如何在同一分布数据上进行偏差分析和方差分析!假设训练集与开发测试集分布不同,我们又需要如何分析偏差和方差呢?
假设训练集和开发集的照片来自不同分布,如果训练集误差为1%,开发集误差为10%。那么久不能简单的说算法过拟合,泛化能力不强。这里的开发集误差高的原因可能有两个:1.是因为训练集在训练的过程中过拟合(方差过高)2.是因为开发集的数据来自和训练集不同的分布。
如何分辨哪种因素影响了开发集的高误差呢?
我们通常的做法是将训练集再划分,比如9:1,将0.9作为训练集,0.1作为开发集,这样相当于是同分布的训练集和开发集。那么总体的数据划分如下:
将原本的训练集的90%作为训练集,将10%作为train-dev集,将原来的开发测试集作为dev-test集。然后将train-dev集和dev-test集上的错误率进行对比,来看看到底是哪个因素影响了开发集的高误差,从而确定我们的优化方向。
- 如果你的训练集和train-dev集误差率相差很多,说明你的算法还存在问题。
- 上面一条的误差不大,而train-dev集误差率和dev-test集误差相差较大,说明是因为数据分布不同造成了高误差。
- 如果两个差距都相差很大,说明两个因素都有影响,均需要优化。
- 假设开发集和测试集的误差相差很大,那么算法可能在开发集上过拟合了,需要在开发集上收集更多的数据。
- 如果出现了训练集和train-dev集上表现不好,而在dev-test集上表现更好,那么可能是训练集的数据更难识别,更难处理的原因。
解决数据不匹配
解决数据不匹配,首先需要了解训练集和开发集的之间区别(错误分析)。找到区别后,可以根据区别来模拟数据,也可以在训练集里加入更多类似于开发集的数据。
迁移学习
假设你有一个已经训练好的语音识别模型,你想将它应用于其他地方,可以使用迁移学习的方法。做法是将输出层去掉,在原始的神经网络的基础上加上一层或者多层的神经网络节点。
那么什么时候使用迁移学习是比较合适的呢?
当你在某个领域学习到的数据和知识应用到另一个领域,而正好这个领域你的数据集比较少,那么你可能能够使用迁移学习来完成这个目标。使用迁移学习有一个重要的前提是:如果想提高任务B的性能,任务A和任务B都要有相同的输入x,任务A比任务B的数据多,迁移学习才是有意义的。
多任务学习
如果对一张图片你需要识别多个物体时,你输入的$x^{(i)}$对应的$y^{(i)}$可能有更高的维数(假设你需要识别4个类,那么维度就变成4$\times$1)。
那么假设对于一个4个维度的网络,我们的损失函数如何定义: $$ \hat{y}^{(i)}=\frac1m\sum_{i=1}^m\sum_{j=1}^4L(\hat{y_j}^{(i)},y_j^{(i)})\ 这里的L是指logsitc损失 $$
多任务学习与softmax回归有什么区别?
softmax将单个标签分配给单个样本,实现多分类问题
多任务学习则是一个图片对应多个标签,每一个标签都是一个多维矩阵。
虽然多任务学习可以使用多个网络单任务来完成,但有时,多任务网络会比单任务多网络的性能更好,而且多任务学习可以解决只有部分物体被标记的情况(比如这张图片中漏标了一个,只对做了标记的进行求和)。
多任务学习提升算法性能的原理:
其实多任务学习可以看成是多次迁移学习的代替。在许多物体的识别的低网络迭代部分是相似的,对于其他物体识别特征的学习的效果相当于增加该物体识别学习的样本数量。(前提是其他任务的样本比该任务的样本多,才能提升该任务识别的性能)。
端到端的深度学习
传统的学习流程(以语音识别为例): $$ X(audio)\xrightarrow{MFCC}特征\xrightarrow{机器学习算法}音位\rightarrow单词\rightarrow Y(听写文本) $$ 而在端到端的学习中,简化成为了黑盒模型: $$ audio\xrightarrow{单个神经网络} 听写文本 $$ 端到端学习被证明比传统的学习流程更好,但只限于数据量比较大的情况下。
如何选择端到端学习?
1.如果你的数据量很大,可以采用端到端学习
2.如果你没有特别多的东西,还是需要人为的组件来支撑(特征提取等)
因为有部分公式可能因为博客插件不支持的原因,完整的笔记请看: https://github.com/caixiongjiang/deep-learning-computer-vision
最后修改于 2022-07-26

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。