图像分割中的上采样方法
反最大池化的方法
在下采样中,我们通常采用最大池化的方法来进行。那么对应在上采样中,反最大池化的方法其实就是记住最大池化时得到像素在原图中的位置,将其他位置填充为0。如图所示:
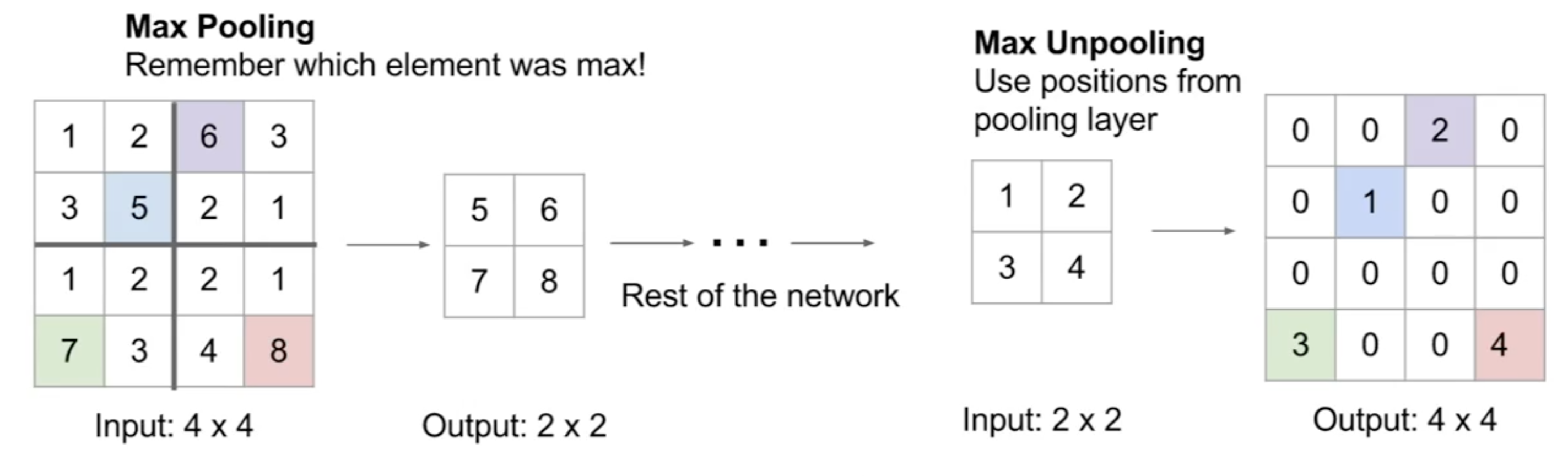
最早的SegNet所使用的上采样就是这种方式!
转置卷积
第二种方法就是转置卷积,这种方法和前面的反最大池化方法的最大区别就是转置卷积的参数是可以用于学习训练的,它不是一个固定的策略!
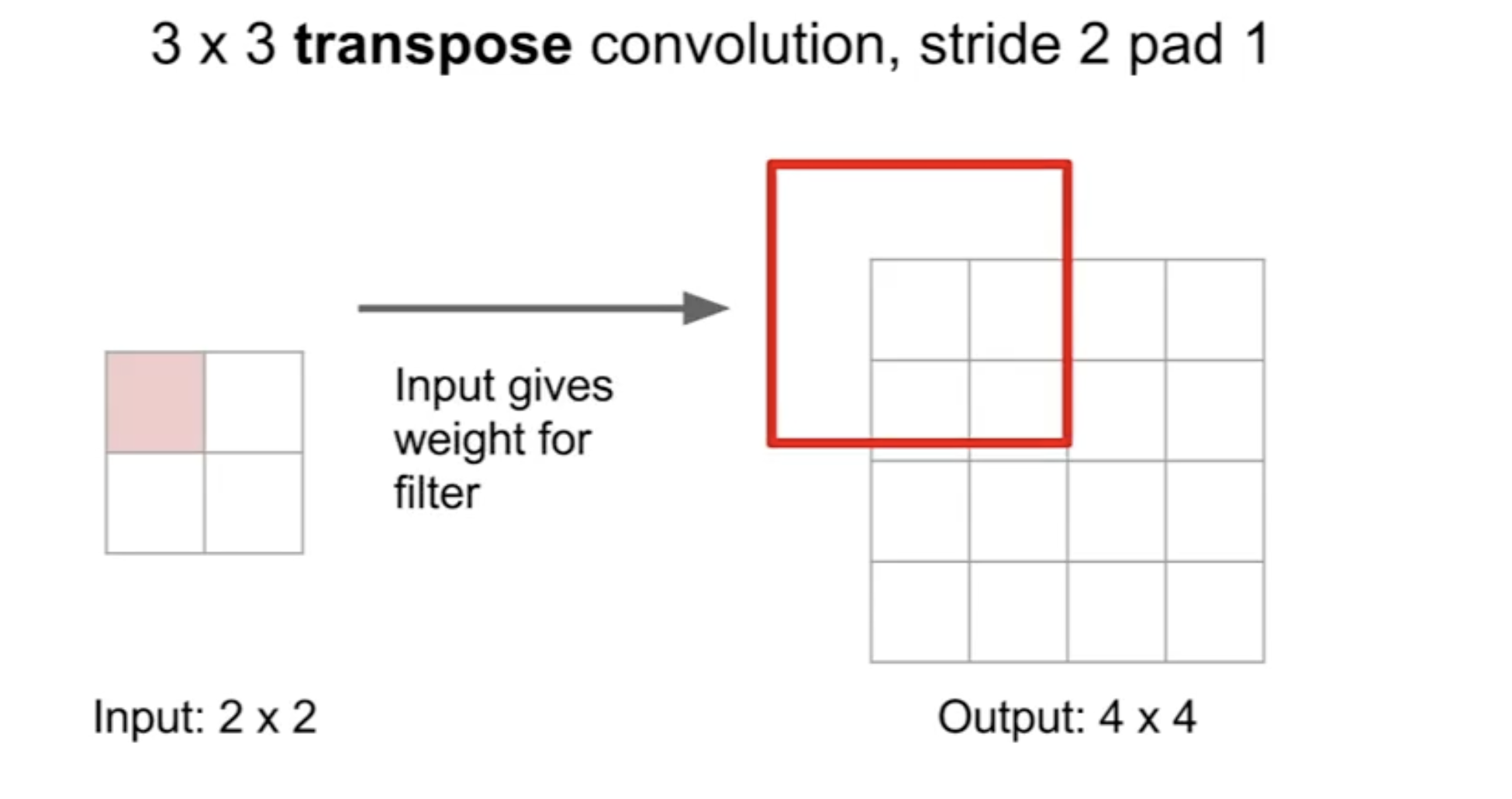
这个图可能看的不是很准确,想看动图的可以访问PyTorch官方给出的动图
以3$\times$3的卷积核将2$\times$2变为4$\times$4的图像为例(没有填充,没有步幅):
1.第一步就是要将2$\times$2的图像使用零padding成为一个6$\times$6(4+2*1得到)的图像
2.对该填充后的图像做3$\times$3的卷积,得到输出图像
在深度学习的论文中,出现反卷积/跨步卷积/上卷积其实指的就是这种转置卷积。
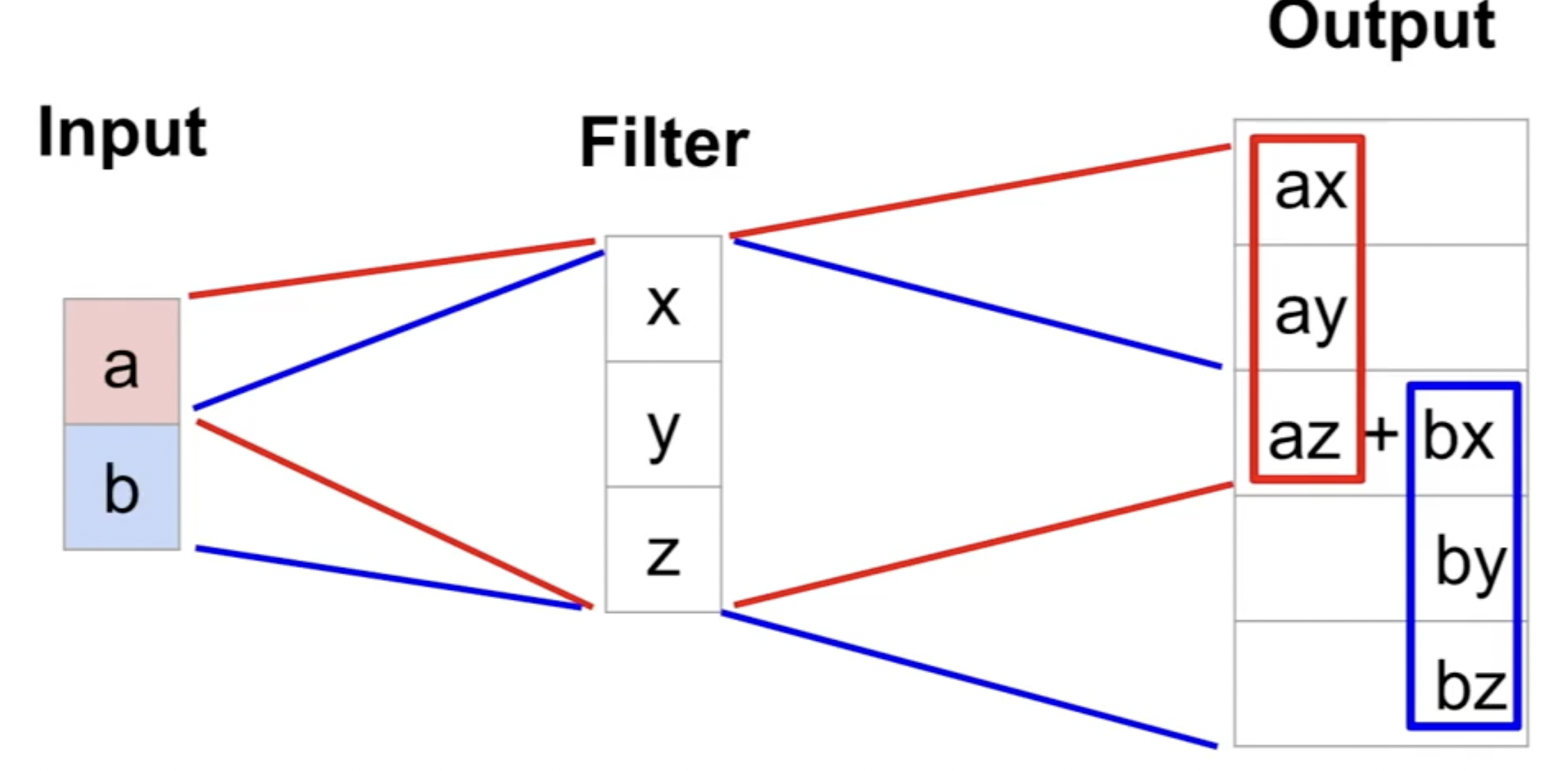
放一张一维的图用于理解:
指标计算
基本指标
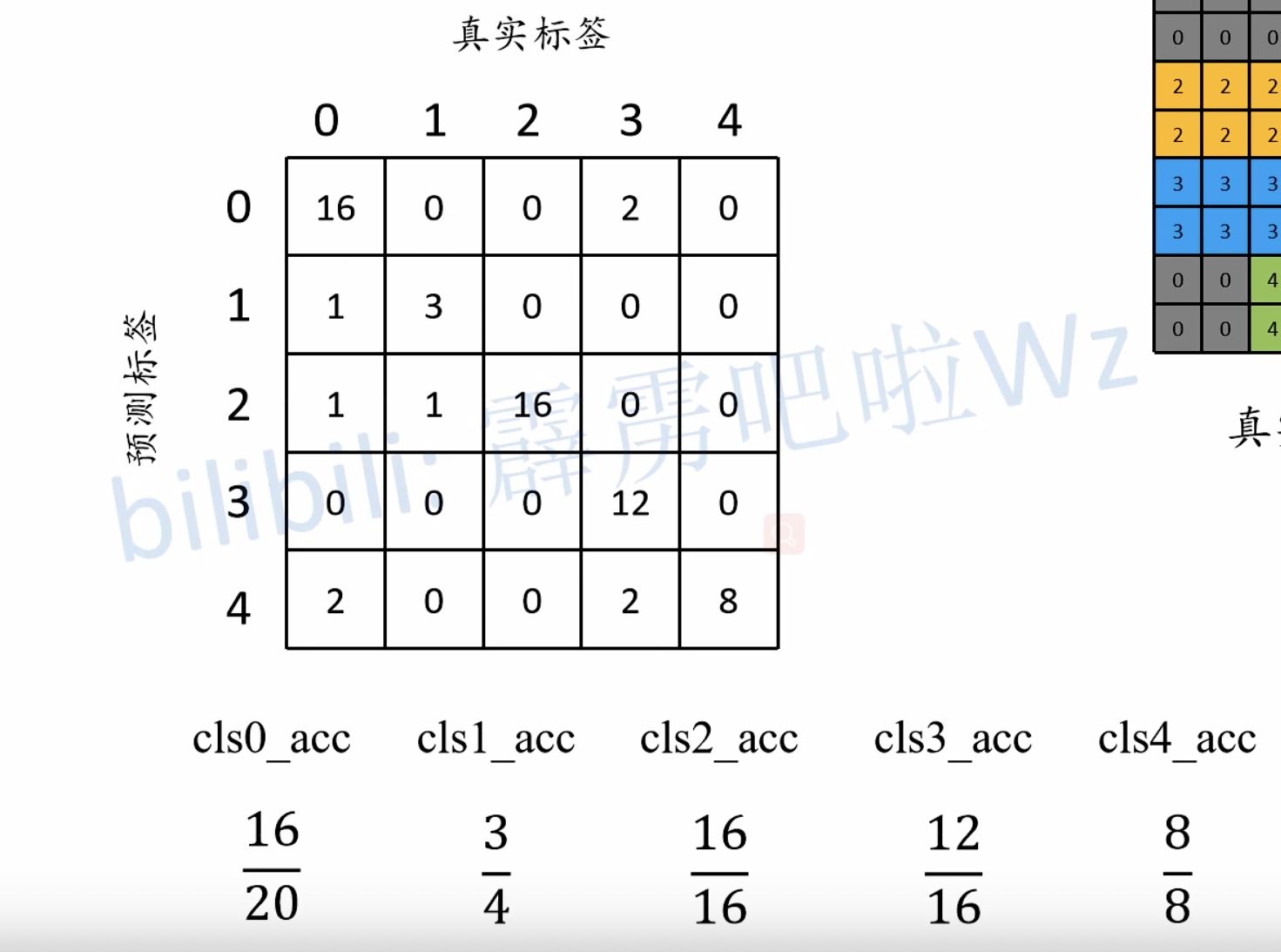
在图像分割中的基本指标通常包括Global Acc、mean Acc、MIOU,``等指标。
Global Acc(Pixel Acc) = $\frac{\sum_in_{ii}}{t_i}$
mean Acc = $\frac{1}{n_{cls}}\sum_i\frac{n_{ii}}{t_i}$
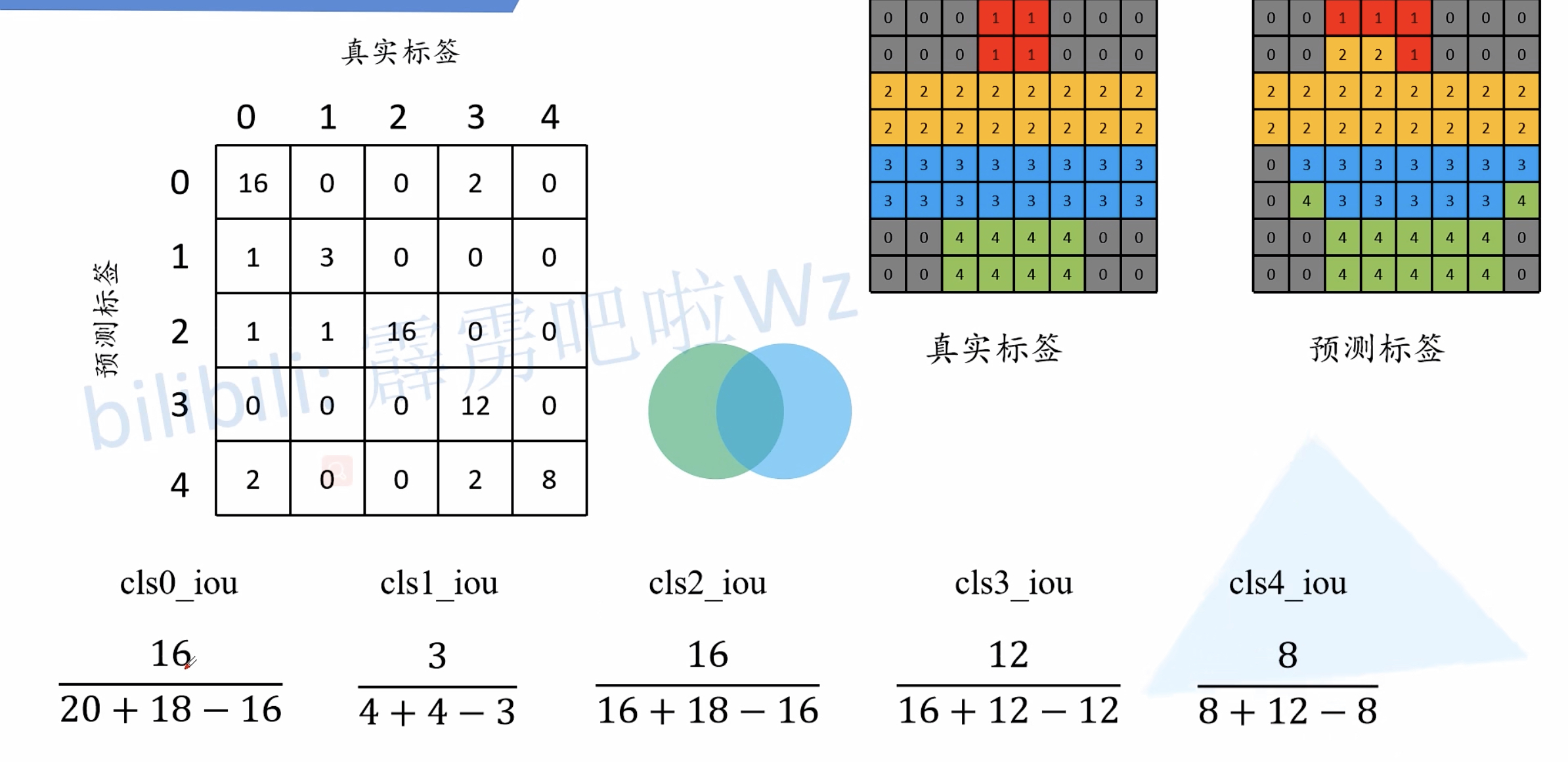
MIOU = $\frac{1}{n_{cls}}\sum_i\frac{n_{ii}}{t_i+\sum_jn_{ji}-n_{ii}}$
$n_{ij}$:类别i被预测成为类别j的像素个数
$n_{cls}$:目标类别个数(包含背景)
$t_i=\sum_jn_{ij}$:目标类别i的总像素个数(真实标签)
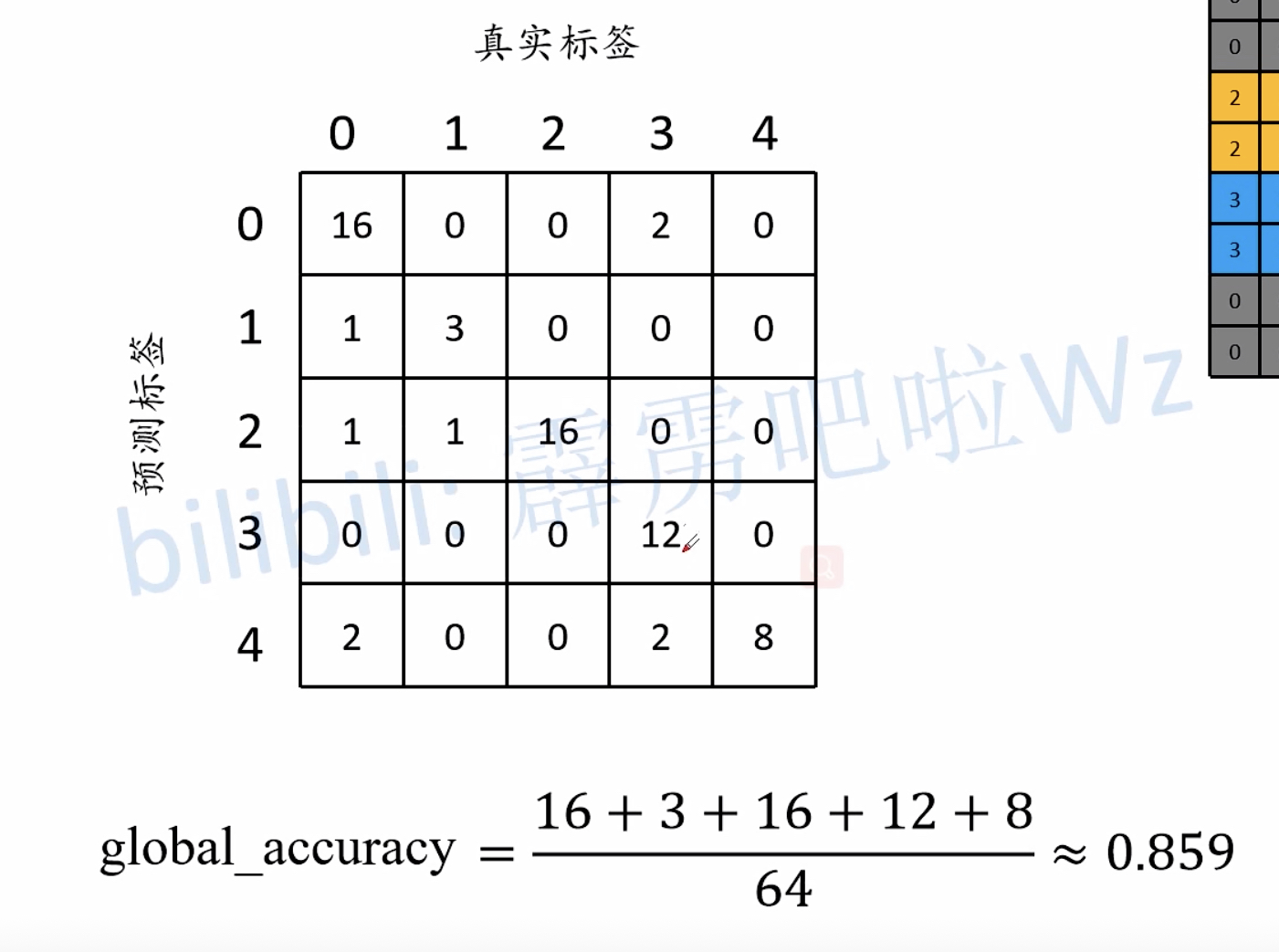
通过混淆矩阵理解指标
直接看下面三个图就可以理解了:
实操
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
'''
混淆矩阵
Recall、Precision、MIOU计算
'''
import numpy as np
from sklearn.metrics import confusion_matrix
import cv2
# 输入必须为灰度图
# labels为你的像素值的类别
from utils import keep_image_size_open
def get_miou_recall_precision(label_image, pred_image, labels):
label = label_image.reshape(-1)
pred = pred_image.reshape(-1)
out = confusion_matrix(label, pred, labels=labels)
# print(out)
# TP = out[0][0]
# FN = out[0][1] + out[0][2]
# FP = out[1][0] + out[2][0]
# TN = out[1][1] + out[1][2] + out[2][1] + out[2][2]
# print(TP / (TP + FP + FN))
r, l = out.shape
iou_temp = 0
recall = {}
precision = {}
for i in range(r):
TP = out[i][i]
temp = np.concatenate((out[0:i, :], out[i + 1:, :]), axis=0)
sum_one = np.sum(temp, axis=0)
FP = sum_one[i]
temp2 = np.concatenate((out[:, 0:i], out[:, i + 1:]), axis=1)
FN = np.sum(temp2, axis=1)[i]
TN = temp2.reshape(-1).sum() - FN
iou_temp += (TP / (TP + FP + FN))
recall[i] = TP / (TP + FN)
precision[i] = TP / (TP + FP)
MIOU = iou_temp / len(labels)
return MIOU, recall, precision
if __name__ == '__main__':
from PIL import Image
label = keep_image_size_open(r'D:\pythonSpace\teach_demo\pytorch-unet\data\SegmentationClass\000799.png')
pred = Image.open(r'D:\pythonSpace\teach_demo\pytorch-unet\result\result.png')
l, p = np.array(label).astype(int), np.array(pred).astype(int)
print(get_miou_recall_precision(l, p, [0, 1, 2]))
|
语义分割的常见数据集格式
PASCAL VOC数据集
原图为JPEG格式,标签为PNG格式。
标签为单通道,只不过Pillow读取时默认读取的为P模式(调色板模式)。目标边缘有白色的像素255,在计算损失时会忽略掉255进行计算。
数据集的文件目录如下:
VOCdevkit
└── VOC2012
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)
└── SegmentationObject 实例分割png图(基于目标)
MS COCO数据集
针对图像中的每一个目标都记录了多边形坐标。
COCO数据集的文件目录如下:
├── coco2017: 数据集根目录
├── train2017: 所有训练图像文件夹(118287张)
├── val2017: 所有验证图像文件夹(5000张)
└── annotations: 对应标注文件夹
├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件
├── captions_train2017.json: 对应图像描述的训练集标注文件
├── captions_val2017.json: 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹
如何使用官方给出的API来读取COCO数据集的信息呢?
关于该API的使用demo:https://github.com/cocodataset/cocoapi
Linux安装pycocotools:
1
|
pip install pycocotools
|
Windows安装pycocotools:
1
|
pip install pycocotools-windows
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
import os
import random
import numpy as np
from pycocotools.coco import COCO
from pycocotools import mask as coco_mask
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
random.seed(0)
json_path = "/data/coco2017/annotations/instances_val2017.json"
img_path = "/data/coco2017/val2017"
# random pallette
pallette = [0, 0, 0] + [random.randint(0, 255) for _ in range(255*3)]
# load coco data
coco = COCO(annotation_file=json_path)
# get all image index info
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
# get all coco class labels
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前三张图像
for img_id in ids[:3]:
# 获取对应图像id的所有annotations idx信息
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据annotations idx信息获取所有标注信息
targets = coco.loadAnns(ann_ids)
# get image file name
path = coco.loadImgs(img_id)[0]['file_name']
# read image
img = Image.open(os.path.join(img_path, path)).convert('RGB')
img_w, img_h = img.size
masks = []
cats = []
for target in targets:
cats.append(target["category_id"]) # get object class id
polygons = target["segmentation"] # get object polygons
rles = coco_mask.frPyObjects(polygons, img_h, img_w)
mask = coco_mask.decode(rles)
if len(mask.shape) < 3:
mask = mask[..., None]
mask = mask.any(axis=2)
masks.append(mask)
cats = np.array(cats, dtype=np.int32)
if masks:
masks = np.stack(masks, axis=0)
else:
masks = np.zeros((0, height, width), dtype=np.uint8)
# merge all instance masks into a single segmentation map
# with its corresponding categories
target = (masks * cats[:, None, None]).max(axis=0)
# discard overlapping instances
target[masks.sum(0) > 1] = 255
target = Image.fromarray(target.astype(np.uint8))
target.putpalette(pallette)
plt.imshow(target)
plt.show()
|
标注工具
labelme
比较传统的工具,但使用也比较多。
EISeg
它是百度PaddlePaddle框架的一款标图工具。对于简单的物体,可以自动抠图,但有时候真的不是很准。
PyTorch载入部分预训练权重
假设我们需要使用迁移学习,就需要载入预训练的权重。那么自定义的数据集分类个数不同,对应的模型结构可能也会有所改变。
那么直接载入全部预训练权重是会出错的。
1
2
3
4
5
|
net = resnet34() # num_classes默认等于1000
net.load_state_dict(torch.load(model_weight_path, map_location=device))
# 改变全连接层的结构
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 5)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
net = resnet34(num_classes=5)
# 查看权重字典key,value值
# net_weights = net.state_dict()
# print(net_weights)
pre_weights = torch.load(model_weight_path, map_location=device)
del_key = []
for key, _ in pre_weights.items():
if "fc" in key:
del_key.append(key)
for key in del_key:
del pre_weights[key]
missing_keys, unexpected_keys = net.load_state_dict(pre_weights, strict=False)
print("[missing_keys]:", *missing_keys, sep="\n")
print("[unexpected_keys]:", *unexpected_keys, sep="\n")
|
最后修改于 2022-08-21

本作品采用
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。