图像分割
图像分割的分类
- 语义分割:可以将图片中不同类别的事物用不同的颜色分割出来,同一类的食物使用相同的颜色填充。
- 实例分割:在语义分割的基础上将同一类别的不同个体分割出来,使用不同的颜色填充。
语义分割如何做?
语义分割是对图像中的每一个像素做语义判断,对逐个像素进行分类。
- 损失函数(c分类):
$$ loss=-\sum_{i=1}^c(w_cy\log(\hat{y}))\quad y代表真实值,\hat{y}代表预测值\ w_c=\frac{N-N_c}{N}\quad N代表总的像素个数,N_c代表类别为c的像素个数 $$
- Focal loss:
Focal loss用来解决难易不同的样本。在损失函数的基础上加入难易程度的奖励,识别准确率越高越容易,权重越低;识别准确率越低越难,权重越高。 $$ loss=-\sum_{i=1}^c(1-\hat{y})^{\gamma}y\log(\hat{y})\quad \gamma值一般取2 $$ 再将之前的样本比例权值$w_c$加上之后,损失函数为 $$ loss=-\sum_{i=1}^cw_c(1-\hat{y})^{\gamma}y\log(\hat{y})\quad $$
IOU计算
- 在多分类任务时:
iou_dog = 正确预测为狗的数量/(真实的狗的数量 + 预测为狗的数量 - 正确预测为狗的数量) - 在语义分割时:假设真实的图片标签为A,预测的图片为B,那么计算的公式:
A和B的交集/A和B的并集。在多类别时,这个指标会变成MIOU:计算所有类别的平均值。
U-net系列
U-net
U-net是一个典型的编码器解码器结构,编码器阶段进行特征提取和下采样(卷积和池化),解码器阶段进行上采样(插值)和特征拼接。模型结构如下:
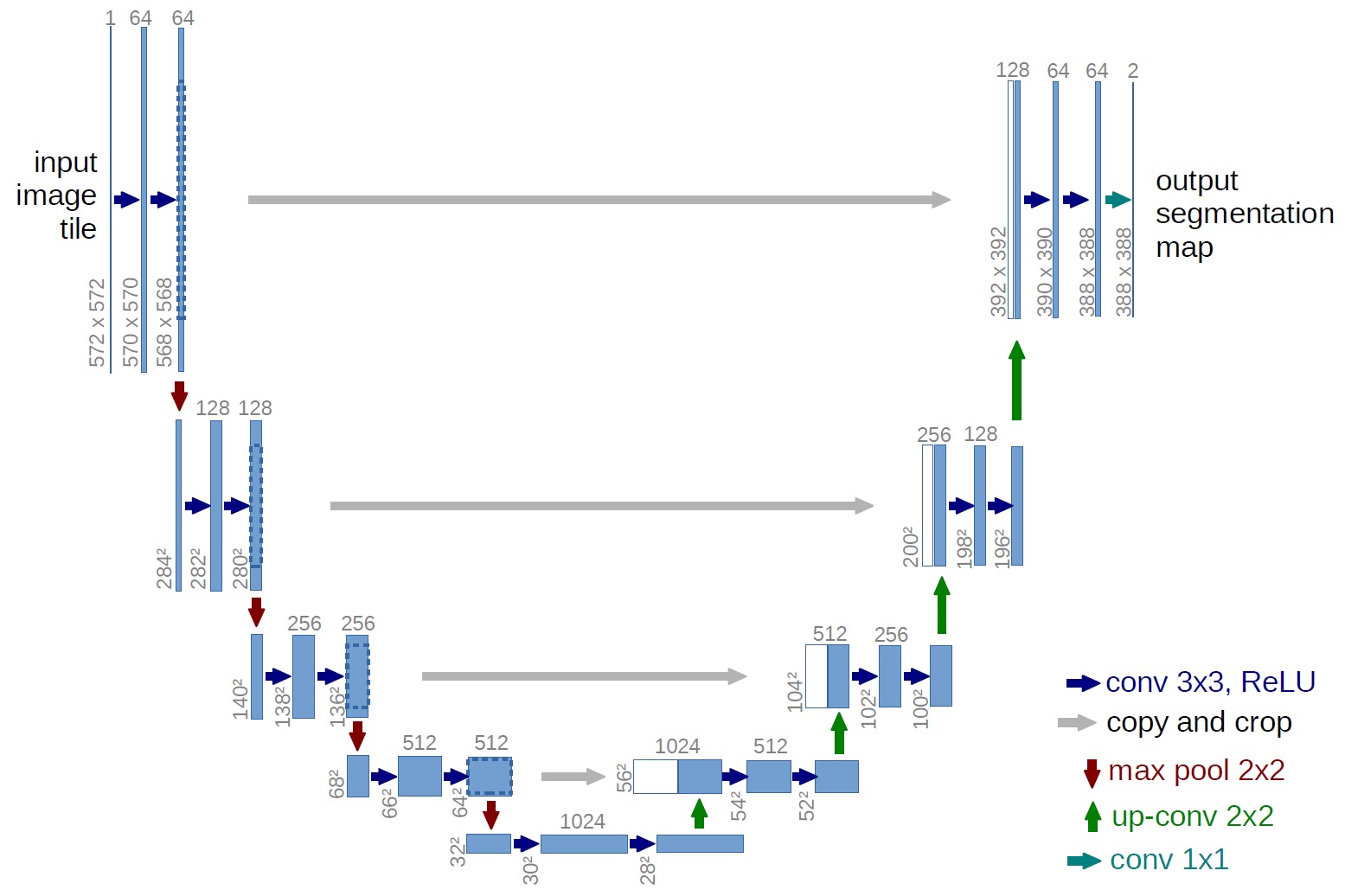
缺点:进行特征拼接的时候,浅层特征离得比较远,上层拼接效果不佳。
U-net++
首先看一下网络结构:

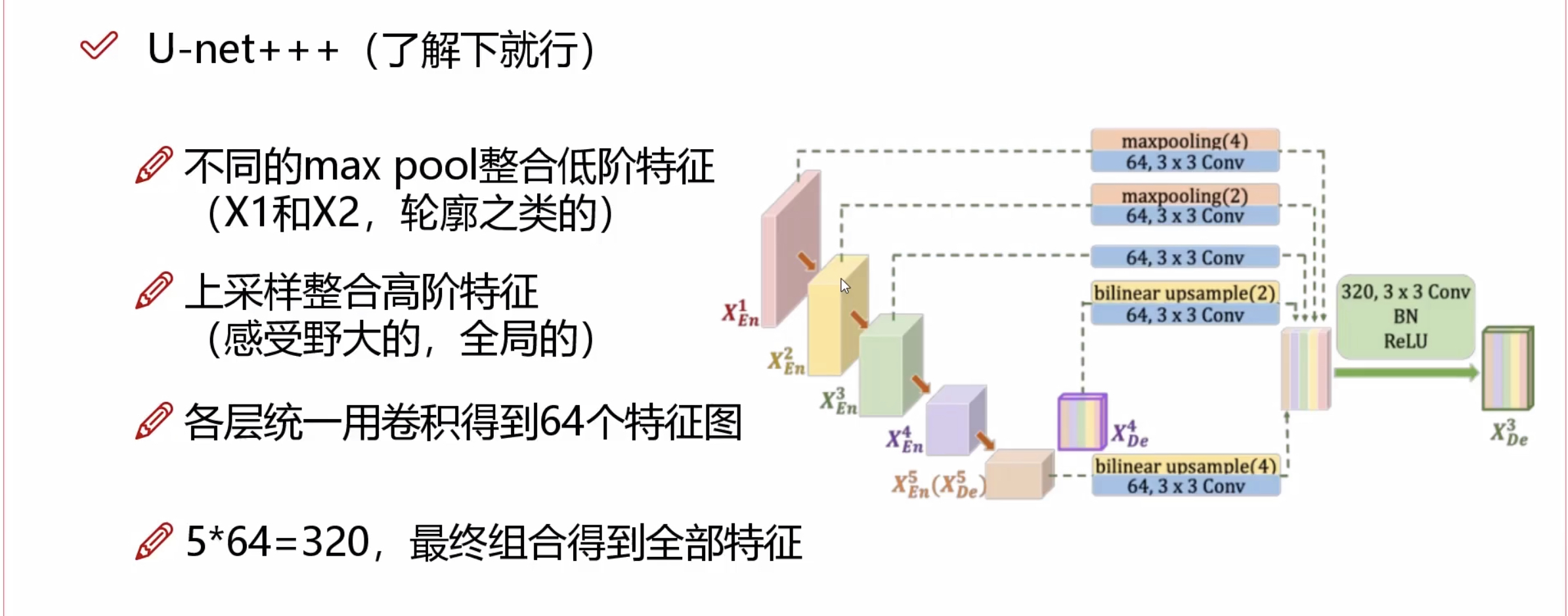
特点:在U-net的基础上,把能拼凑的特征全部都用上了。拼接的方式如上图,所有相邻的特征进行拼接。中间连线的部分是因为这部分的图像大小和输出图像大小一致,通过$1\times1$卷积将他们都作为预测的损失函数(也就是经常说的多输出)。
U-net++的优点:
可以更容易剪枝:比如我做到L4层的效果就很好,就可以将不需要的L5的上采样过程给去掉。
U-net+++
直接看结构,也是在特征融合上下功夫:
DeepLab系列
感受野
假设一个$7\times7$的图片,通过2次$3\times3$的卷积操作,得到一个像素,那么这个像素的感受野就是$7\times7$的。那么感受野的概念其实就类似于当前计算出像素的值和前面原始图像的49个像素都有关。一个像素的感受野越大,那么它提取处的特征信息可能更加准确。
空洞卷积
为了增大感受野,我们通常的做法会采用下采样(也就是池化层),但是池化层有一个缺点是它会丢失一部分信息。
空洞卷积的提出为增大感受野提供了一种新的方法,空洞卷积的做法如下图:
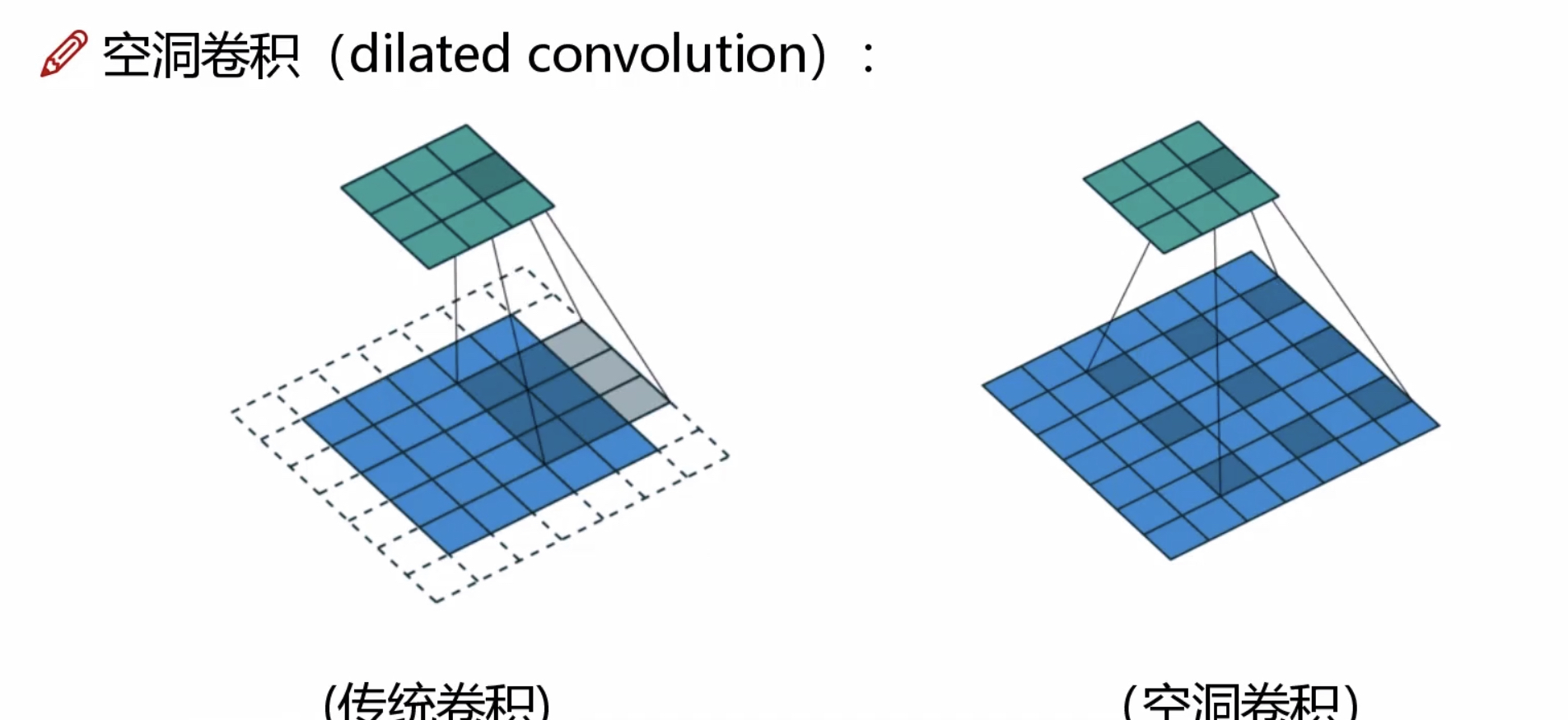
空洞卷积的优势:
1.图像分割任务中需要较大的感受野来完成更好的任务
2.在Pytorch代码中之需要改变一个参数就可以了
3.扩大感受野时,参数的多少不不变的,计算代价没有变化
SPP层的作用
为了使卷积网络模型满足不同分辨率的要求,我们通常会使用spatial pyramid pooling layer达到这种效果。
在卷积网络中,卷积层通常不会对输入图像的分辨率由要求,但是在全连接层,会限制你图像输入的大小。SPP-Layer 的结构如下图:
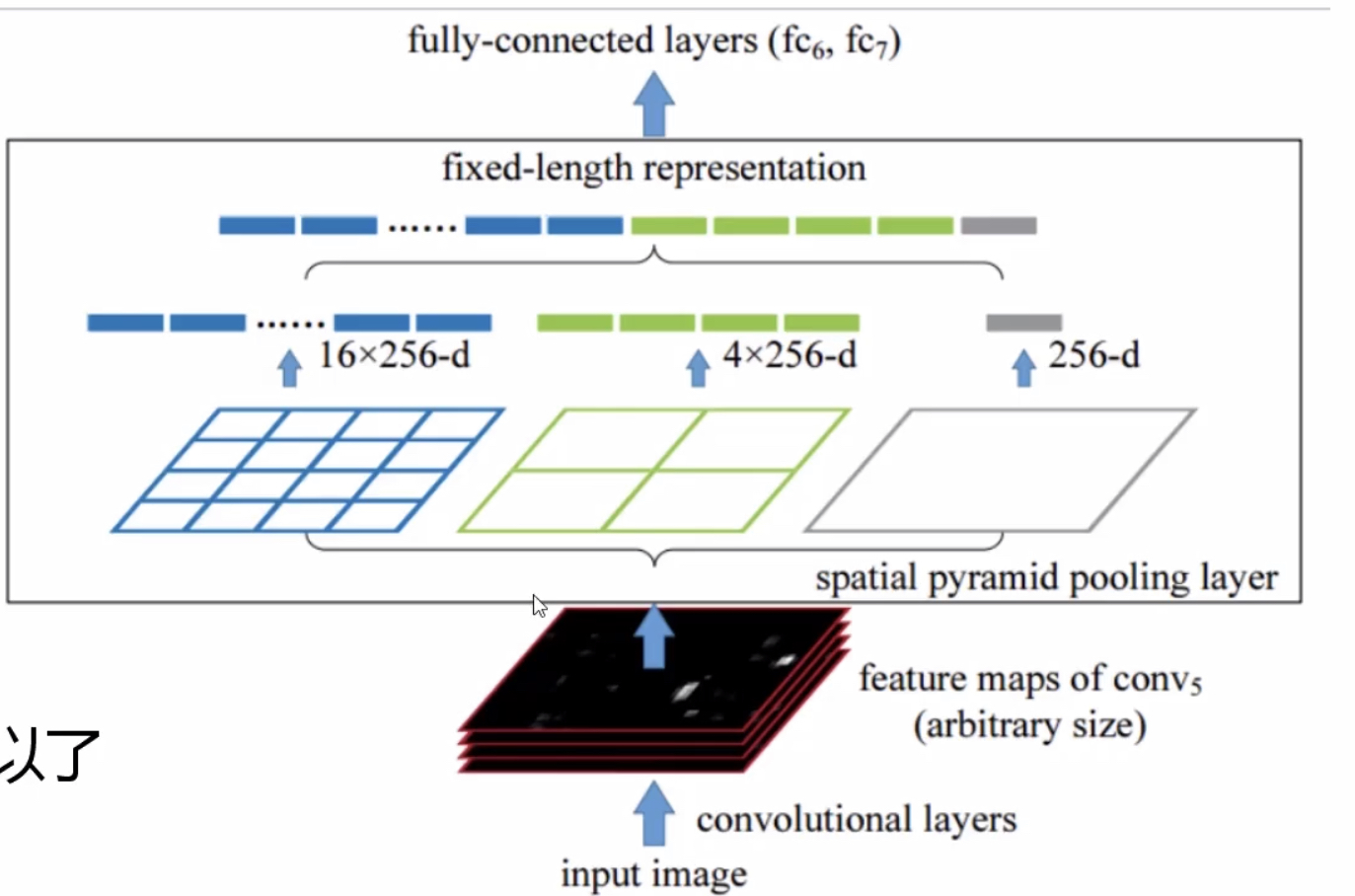
不管输入的图像大小是多少,该层都把你分别16等分、4等分、分成1份,分别进行池化,再进行特征拼接。无论你的输入大小是多大,得到的结果都是一样的,这样就保障了我们的输出特征是固定的。
ASPP特征融合策略
ASPP其实是在SPP的策略基础上加入了不同倍率的空洞卷积。
其主要结构如下:

DeepLabV3+
先看网络结构:

可以看到在特征融合层ASPP之前,有一个深度卷积网络(DCNN),这里一般选用市场上效果比较好的特征提取网络。整个网络是一种编码器和解码器的结构,解码器通过DCNN中提取的浅层特征(局部特征)和经过上采样的融合特征(考虑全局的特征)做拼接,再经过一次卷积核一次上采样(插值法)得到输出结果。注意:特征融合层采用不同倍率的空洞卷积来完成。
最后修改于 2022-08-11

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。